 2015-06-14
2015-06-14 4514
4514Теория принятия решений (исследование операций) — научная дисциплина, изучающая социальные, психологические, логические, информационные и математические стороны принятия решений. В центре внимания этой теории две основные проблемы: обоснование выбора решения и механизм его осуществления. Все принимаемые решения можно разбить на индивидуальные и коллективные.*
* При этом нельзя говорить о преобладании тех или иных. В различных областях права возможны разные формы принятия решений. В правотворческой деятельности процесс выработки, принятия и осуществления решения имеет преимущественно коллективный характер.
В теории принятия решений различают:
управленческие решения (решения, принимаемые в процессе управленческой деятельности);
государственные решения (решения, принимаемые на уровне государственной политики в целом);
политические решения (решения, принимаемые политическими органами государства);
оптимальные решения — наилучшие по некоторому критерию.
Теория принятия решений нередко трактуется как комплекс математических дисциплин, в которых исследуются формализованные задачи. Основные разделы теории — математическое моделирование, теория группового решения, теория игр.*
* Теория принятия решений применяется в задачах планирования, управления и проектирования.
Математическое программирование изучает методы нахождения экстремумов (максимумов или минимумов) функций многих переменных при наличии ограничений на эти переменные.*
* Обычно ограничения формулируются в виде равенств или неравенств.
Теория группового выбора изучает концепции и механизмы "справедливого" (согласованного) объединения индивидуальных решений в единое коллективное (групповое) решение — выбор простым квалифицированным большинством, одноступенчатое, многоступенчатое голосование и т.д.
При определенных предпосылках принятие решения может опираться и на теорию игр, которая занимается математическими моделями принятия оптимальных решений в условиях конфликта. Под конфликтом понимается столкновение противоположных интересов, взглядов, позиций лиц и системы.*
* Создателями теории игр являются американский математик и кибернетик Дж. фон Нейман и экономист О. Моргенштерн.
Теория принятия решений имеет важные математические аспекты. Для уточнения понятия "выбор решения" целесообразно использовать математические понятия, прежде всего — множества и подмножества. Принятие правотворческого решения — это практическая процедура нахождения из множества возможных вариантов решений такого, который представляется оптимальным.
Конечным результатом правотворческого процесса является принятие конкретного нормативного правового акта (НПА) — федерального конституционного закона, федерального закона, постановления Правительства, указа Президента РФ и др.
Правотворческие решения делятся на общие и частные. Общими являются решения о принятии (отклонении, изменении) данного нормативного акта. Частные решения касаются отдельных вопросов законодательной процедуры (например, принятие закона в первом чтении).
В структуре процесса принятия решения важное место занимает информационная компонента, ибо принятие решений с полным основанием можно рассматривать как процесс целенаправленного преобразования исходной информации. Обеспечение принятия решений полной и надежной информацией в нужное время — центральная и наиболее сложная проблема организации управления.
В процессе принятия правотворческого решения первичная юридическая, экономическая, политическая, социальная и иная необходимая для подготовки нормативного правового акта информация преобразуется в правовую — в нормы и институты права. Процесс преобразования эмпирической информации дискретен (прерывен). Его дискретными тактами являются определенные периоды обработки первичной информации, сопряженные со стадиями законотворческого процесса.
Информационный поток непрерывен. Он продолжается на всех стадиях законодательного процесса. Сама законодательная инициатива есть сигнал о необходимости начала работы по созданию соответствующего законопроекта.
Термин "принятие решений" используется и в новейших законодательных актах. Так, он фигурирует в Регламенте Государственной Думы (гл. 14, 15). Глава 10 Регламента называется "Порядок голосования и принятия решений". Согласно ст. 134 федеральный закон, отклоненный Президентом Российской Федерации, передается Советом Государственной Думы на заключение в ответственный комитет, который в течение 10 дней рассматривает мотивы решения Президента Российской Федерации отклонить федеральный закон. По итогам рассмотрения ответственный комитет вносит проект постановления Государственной Думы, в котором может рекомендовать один из следующих вариантов решения:
а) принять федеральный закон в редакции, предложенной Президентом Российской Федерации;
б) согласиться с мотивами решения Президента Российской Федерации и снять федеральный закон с дальнейшего рассмотрения Государственной Думой;
в) принять федеральный закон с учетом предложений Президента Российской Федерации;
г) создать специальную комиссию для преодоления возникших разногласий и предложить Президенту Российской Федерации и при необходимости Совету Федерации направить для работы в ней своих представителей;
д) одобрить федеральный закон в ранее принятой редакции.
Принятие решения Советом Федерации регламентируется главой 7 Регламента Совета "Порядок голосования и принятия решения". Статья 71 выделяет виды голосования: количественные, рейтинговые, альтернативные и дает определение каждого из них.
Голосование осуществляется с использованием или без использования электронной системы, бюллетенями и путем опроса.*
* Другие главы Регламента также посвящены процедурам принятия решений. Термин "принятие решения" применяется также в Федеральном законе "Об оперативно-розыскной деятельности" (ст. 7 и 10) и др.
Наряду с понятием правотворческого решения в теории права используется и понятие "правоприменительное решение". Это могут быть судебные решения по конкретным уголовным, гражданским или арбитражным делам.
Решение является главным элементом всякой правоприменительной деятельности. Их осуществлению подчиняется вся деятельность государственных органов. В сфере компетенции исполнительной власти различают постановления и распоряжения глав администрации, приказы ответственных должностных лиц и т.д.
Для решения задач информатизации принципиальное значение имеют следующие свойства принятия решений.
Решения в юридической сфере относятся к классу нормативных, т. е. таких, процедуры которых регламентированы законом. В серии управленческих решении реализуется процесс последовательного устранения неопределенности и противоречий. Процесс принятия решений основан на применении экспертных технологий для генерирования альтернативных вариантов, принятия коллективных решений, определения рейтингов. В нормативно организованном поведении субъект заранее учитывает такой фактор, как возможная санкция, если планируемое поведение будет отклоняться от заданного.
Принятие решения есть процесс целенаправленного преобразования исходной информации о состояний объекта управления в информацию о наиболее рациональном пути достижения желаемого состояния в будущем. Информационный аспект составляет основу системной концепции принятия решений в сложных иерархических организациях и организационных системах.
Сбор, обработка, получение, хранение, оценка и использование информации в процессе выработки и принятия решения подчиняются ряду правовых принципов.
Каждое решение по применению права должно быть законным и обоснованным. Это требование вытекает из того, что решения в правовой сфере всегда принимаются в условиях некоторой правовой ситуации, действия норм материального и процессуального права. Под законностью понимается строгое соответствие решения требованиям материального и процессуального права. Под обоснованностью — информационная обеспеченность решения.
Процессы принятия решений федеральными органами государственной власти регулируются нормами Конституции РФ.
В сфере уголовно-процессуального законодательства закон содержит многочисленные нормы, регулирующие процесс принятия решений в связи с раскрытием, расследованием и рассмотрением уголовных дел.*
Так, УПК РСФСР содержит правила поведения следователя, предъявляющего обвинение.
В области административного права принятие решений министерствами и комитетами, их должностными лицами регулируется положениями о министерствах и комитетах.
§ 8. Понятие алгоритма
Алгоритм — это строгий порядок действий, точное предписание о последовательности операций для решения всех задач данного типа. ЭВМ работает по программе, в основе которой лежит тот или иной алгоритм.
Понятие алгоритма занимает важное место в информатике. Это ее фундаментальное понятие. Вместе с тем теория алгоритмов является разделом математической логики.*
* Теория алгоритмов тесно связана с метаматематикой, которая изучает методы математических доказательств, способы построения аксиоматических теорий, свойства математических процедур.
В алгоритме применения права происходит проверка каждого условия (совокупность которых предусмотрена законом) посредством логической операции сравнения по принципу: "да" — "нет".
В криминалистике разработаны алгоритмы расследования уголовных дел и проведения отдельных следственных действий. Нужно различать общий алгоритм расследования и частные методики. У каждого следственного действия (например, допроса) — свой алгоритм, значит, имеет место иерархия алгоритмов.
Всякий алгоритм применяется к исходным данным и выдает результаты (выходные данные). В ходе работы алгоритма появляются различные промежуточные данные. Поэтому должны быть указаны виды данных, с которыми могут работать алгоритмы.*
* Для описания данных, во-первых, фиксируется набор элементарных символов (алфавит данных) и, во-вторых, даются правила построения сложных данных из простых.
Последовательность шагов алгоритма должна быть однозначной. Не допускается произвола при выборе очередного шага. Обязательно должны быть зафиксированы начальный и заключительный шаги.
Информатика выделяет два крупных класса алгоритмов: вычислительные, информационные.
Вычислительные алгоритмы работают со сравнительно простыми видами данных (числа, матрицы).
Информационные алгоритмы представляют собой набор процедур (например, поиск числа или слова, удовлетворяющего определенным признакам), работающих с большими объемами информации.
Алгоритм, заданный в виде последовательности команд на языке вычислительной машины, называется машинной программой. Команда машинной программы (машинная команда) — это элементарная инструкция ЭВМ, выполняемая ею автоматически без каких-либо дополнительных указаний и пояснений.*
* Алгоритм характеризуется такими свойствами, как детерминированность, массовость, результативность.
Нормативные акты, регламентирующие правовые процедуры, содержат немалое число различных алгоритмов. Создание права есть последовательный процесс принятия серии решений. Этот алгоритм можно назвать общим. Так, правотворческий процесс состоит из следующих стадий:*
Стадия 1. Поступление законопроекта, внесенного субъектом права законодательной инициативы, в Государственную Думу.
Стадия 2. Первичное рассмотрение законопроекта, вносимого в порядке законодательной инициативы.
Стадия 3. Рассмотрение законопроекта в первом чтении.
Стадия 4. Рассмотрение законопроекта во втором чтении.
Стадия 5. Рассмотрение законопроекта в третьем чтении.
Стадия 6. Прохождение закона в Совете Федерации.
Стадия 7. Повторное рассмотрение закона, отклоненного Советом Федерации.
Стадия 8. Прохождение закона у Президента Российской Федерации.
Стадия 9. Повторное рассмотрение закона, отклоненного Президентом Российской Федерации.
* Данная схема разработана Управлением информационно-технологического обеспечения Аппарата Государственной Думы с участием других подразделений Аппарата в целях создания Автоматизированной системы обеспечения законодательной деятельности.
На каждой стадии правотворческого процесса информации должно быть столько, чтобы можно было принять оптимальное решение.
Важным условием повышения эффективности правовых актов является ввод в законодательные тексты значительного числа норм алгоритмического типа — таких, которые четко и последовательно описывают юридические процедуры в конкретной области.
Нормы и процедуры алгоритмического характера содержатся в Регламенте Государственной Думы. Это следующие алгоритмы:
порядок внесения законопроектов;
рассмотрение законопроектов и принятие федеральных законов;
повторное рассмотрение федеральных законов, отклоненных Советом Федерации;
повторное рассмотрение федеральных законов, отклоненных Президентом Российской Федерации;
рассмотрение предложений о пересмотре положений Конституции.
Алгоритмы законодательной деятельности закреплены и в Регламенте Федерального Собрания:
порядок голосования и принятия решения (гл. 7);
порядок рассмотрения федеральных законов (гл. 10);
порядок повторного рассмотрения федеральных законов (гл.12) и др.
В судебной экспертизе алгоритм — это программа оптимизации действий в последовательности, обеспечивающей при определенных условиях разрешение поставленного перед экспертом вопроса.
§ 9. Методы измерения количества информации
Одной из важных практических задач информатики является поиск эффективных методов измерения количества сведений, циркулирующих в информационных процессах.
Значительный вклад в это дело внес крупный американский ученый К. Шеннон, создавший статистическую теорию информации, где решаются многие вопросы ее измерения. Так, в фундаментальном труде, посвященном статистической теории связи (1948), Шеннон доказал теорему о пропускной способности канала связи: при скоростях передачи, превышающих пропускную способность, не существует таких методов кодирования и декодирования, которые обеспечивали бы восстановление передаваемого сигнала.
Теория кодирования изучает те формы, в которые может быть воплощено содержание любых данных (сообщений). Кроме того, теория систематически исследует вопросы передачи информации по различным каналам.
Информация имеет дело со случайными явлениями и процессами. Поэтому она тесно связана с понятием вероятности.*
* Процесс получения информации можно рассматривать как процесс выбора. Выбор осуществляется как отправителем, так и получателем сообщения. Этот выбор имеет случайный характер.
Если бы система, от которой исходит информация, была известна заранее, не было бы смысла передавать сообщение. Оно приобретает смысл, когда состояние системы заранее неизвестно, случайно.
Исходная система случайным образом может оказаться в том или ином состоянии, ей заведомо присуща какая-то степень случайности, неопределенности. Понятие информации может интерпретироваться как снятие неопределенности.
Неопределенность — это отсутствие данных о системе и ее состоянии. Она может быть измерена.*
* Понятие неопределенности встречается в правовых ситуациях. Так, в соответствии с Федеральным конституционным законом о Конституционном Суде от 24 июня 1994 г. введено понятие о правовой неопределенности (ст. 36).
Сообщение содержит тем больше информации, чем меньше вероятность того события, о котором идет речь в полученном сообщении. Сведения, полученные от системы, тем ценнее и содержательнее, чем больше была неопределенность системы до получения этих сведений. Следовательно, понятие информации и неопределенности тесно связаны и дополняют друг друга. С увеличением знания об исследуемой системе уменьшается ее неопределенность.
Чтобы уметь численно оценивать степень неопределенности самых разнообразных явлений и по этим признакам их сравнивать, нужно иметь какую-то меру, характеризующую неопределенность. Такая мера может быть установлена на основе некоторого опыта. Теория вероятности и теория информации показывают, что при проведении опыта с N равновероятными исходами неопределенность его будет тем выше, чем больше величина N. Поэтому в теории информации за меру неопределенности опыта (а следовательно, и интересующая нас информация) берется число состояний исследуемой системы (случайной величины).
Чем больше возможных состояний содержит система, от которой исходит информация, тем более она неопределенна.
Английский ученый Хартли предложил использовать в качестве меры неопределенности ("мера Хартли") логарифм от числа возможных состоянии:*
H = K log aN,
где N — число возможных состояний системы.
* Логарифм числа по данному основанию — показатель степени, в которую надо возвести основание для того, чтобы получить данное число.
Чем большее число N имеет система, тем ценнее данные о реализации конкретного состояния.
"Степень неожиданности" того или иного случайного события (А) определяется его вероятностью: чем вероятность меньше, тем событие неожиданнее. А так как с увеличением неожиданности события возрастает ценность связанной с ним информации, то естественно считать доставляемую событием А информацию I(А) зависящей от его вероятности (р), т. е. считать, что величина I(А) является функцией р:
I (A) = f (p).
При этом информация должна возрастать с уменьшением р и равняться нулю при р = 1 (если событие осуществляется с частотой 1, т. е. наверняка, то оно не несет с собой никакой информации):
f (p) = 0 при р = 1; f(p 1 ) > f (p), если р 1< р.
Эти и некоторые другие несложные соображения приводят к выводу о том, что информация I(А), доставляемая некоторым случайным событием А, измеряется логарифмом величины p:
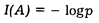
(логарифмическая мера количества информации).*
* При этом логарифм берется с обратным знаком. Это делается из математических соображений: р — есть дробь, а логарифм дроби есть величина отрицательная. При наличии знака минус выражение — log p становится положительным.
Однако величина I(А) сама по себе представляет мало интереса, так как относится к отдельному сообщению (выбору).
Кроме того, считалось, что все состояния исходной системы равновероятны. К. Шеннон сделал важное обобщение. Он предположил, что величина неопределенности зависит не только от числа возможных исходов опыта, но и от вероятности каждого состояния.*
* Исходы опыта могут иметь разную вероятность.
За основу своего подхода К. Шеннон взял представление о случайной величине:
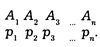
Первый ряд чисел — значения некоторой случайной величины, второй— вероятности, с которыми реализуется каждое значение.
Если по-прежнему отдельные исходы А 1, А 2 ..., Аn опыта (имеющие вероятности р 1, р 2,..., рn) осуществлялись в длинной серии испытаний n 1, п 2 ... соответственно n раз, то получается окончательно:
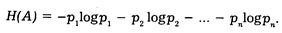
Средняя энтропия ЩА), связанная с осуществлением опыта А, представляет собой весьма важную статистическую характеристику этого опыта; можно считать, что она выражает "меру степени неопределенности" А; чем "неопределеннее" исход опыта А, чем труднее предсказать его заранее, тем большую информацию мы получим, выяснив этот исход. Руководствуясь некоторыми физическими аналогиями, Шеннон назвал величину ЩА) энтропией опыта А.
В краткой записи:
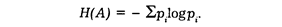
Энтропия — это количественная мера неопределенности. Уничтоженная сведениями энтропия и есть информация. Организация и структура, упорядочивание и управление противостоят энтропии и неопределенности, противодействуют их возрастанию.
Примем следующие обозначения:
Н 0 (Х) — энтропия случайной величины до получения сообщения о ее состоянии;
Н 1 (Х) — энтропия случайной величины после получения сообщения о ее состоянии (остаточная энтропия);
Н(Х) — разность величин Н 1 (Х) и Н 0 (Х). Тогда количество информации может быть представлено в следующем виде:
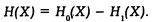
Приведенные методы измерения информации широко применяются в различных сферах науки и практики (психологии, лингвистике, социологии и др.). Кроме того, они позволяют обоснованно выбрать единицу информации.
В связи с развитием средств связи и коммуникаций и их использованием для обработки и передачи правовой информации возникла необходимость найти методы измерения ее количественных характеристик.
Правовая информация характеризуется качественными и количественными параметрами. Количество правовой информации может быть измерено (при определенных предпосылках). Здесь возможны два подхода.
Первый подход основан на определении "физического объема" информации.
Физический объем — это длина представляемого, текста, емкость — количество передаваемой информации, компактность — соотношение информационного и физического объемов, плотность — соотношение емкости и объема. Единицами измерения объемов нормативного текста могут быть: количество статей в нормативном правовом акте, число типографских страниц, которые занимает изучаемый нормативный акт, число фраз, содержащихся в данном акте.
Второй подход основан на положениях теории информации.
Формула К. Шеннона позволяет ввести единицу информации. За единицу информации принято считать такое ее количество, которое содержится в исходе опыта (сообщения), содержащего только два возможных состояния (1 или 0). При этом каждое состояние может быть реализовано с вероятностью, равной 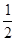 .
.
Приведем элементарный расчет. Условия:
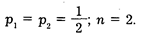
Подставляем эти данные в формулу Шеннона:
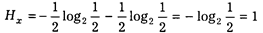
(при этом 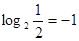 ).
).
Полученная таким образом единица информации называется бит. В информатике используются производные единицы. 1 байт (один байт) = 8 бит.
1 Кбайт (один килобайт) = 210 = 1024 байт (1 тыс. байт)
1 Мбайт (один мегабайт) = 220 = 1048576 байт (1 млн. байт)
1 Гбайт (один гигабайт) = 230 (1 млрд. байт).
Средняя страница содержит около 2,5 Кбайт, учебник — чуть больше 0,5 Мбайт текста. В Большой Советской Энциклопедии примерно 120 Мбайт. В одном номере четырехстраничной газеты — 150 Кбайт, а если собрать по одному номеру всех газет, выходящих в нашей стране, то в них будет уже гигабайт информации. Если человек говорит по 8 часов в день, то за 70 лет жизни он производит около 10 гигабайт информации.
В небольших системах правовой информации ее объем измеряется в мегабайтах.* В больших компьютерных центрах и системах правовая информация измеряется в гигабайтах.
* Один мегабайт равен примерно 500 стр. машинописного текста.
В десятичной системе исчисления единица измерения — дит (десятичный разряд).
Пример. Сообщение в двоичной системе в виде восьмиразрядного двоичного кода 10111011 имеет объем данных
Vд = 8 дит.
Сообщение в десятичной системе в виде шестиразрядного числа 275905 имеет объем данных V = 6 дит.
Литература
Баранов В. М., Поленина С. В. Система права, система законодательства и правовая система. Н. Новгород, 1999.
Гаврилов О. А. Правовая кибернетика и теория социалистического права / Право и кибернетика. М., 1984.
Гаврилов О. А. Основы правовой информатики. М., 1998.
Громов Г. Р. Национальные информационные ресурсы. Проблемы промышленной эксплуатации. 1984.
Глушков В. М. Основы безбумажной информатики. М., 1982. Информатика / Под ред. проф. Н. В. Макаровой. М., 1998. Информатика. Энциклопедический словарь для начинающих / Под ред. проф. Д. А. Поспелова. М., 1994.
Курушин В. Д., Минаев В. А. Компьютерные преступления и информационная безопасность. М., 1998.
Леванский В. А. Моделирование в социально-правовых исследованиях. М., 1982.
Правовая информатика и кибернетика / Под ред. Н. С. Полевого. М., 1993.
Рассолов М. М. Правовая информатика. М. 1972.
Шеннон К. Работы по статистической теории связи. М., 1960.
Яглом А. М., Яглом И. М. Вероятность и информация. М., 1974.
Глава 4. Методологические основы правовой информатики
§ 1. Информатика и проблема искусственного интеллекта
Методология правовой информатики характеризуется значительным разнообразием применяемых средств. Так, на современном этапе "горячей точкой" являются исследования по искусственному интеллекту. Именно здесь решаются многие коренные вопросы будущего информатики и вычислительной техники, используются новейшие методы научных междисциплинарных исследований.
Интеллект и интеллектуальная система (язык, право) — это мощные системы, моделирующие мир (его часть) (см. рис. 8).

Рис. 8. Интеллектуальные процессы. (Ю. И. Шемякин, А. Р. Романов. Компьютерная семантика. М., 1995. С. 19).
Искусственный интеллект — это искусственно созданная система, реализуемая на современных ЭВМ, и предназначенная для моделирования (имитации) свойств реального интеллекта человека, его мыслительной деятельности, его психики, т. е. способности выбора целесообразного решения на основе ранее аккумулированной информации. ЭВМ в состоянии при определенных условиях доказывать математические теории, сочинять стихи и тексты, осуществлять машинный перевод, автоматическое реферирование, сложный информационный поиск и т. д. Проблема искусственного интеллекта — одна из самых сложных научно-практических проблем, которая когда-либо стояла перед человечеством. В настоящее время это главное направление развития информатики и вычислительной техники.*
* Отошли в прошлое дебаты по вопросу о том, может ли машина мыслить. В настоящее время становится все более очевидным тот факт, что ЭВМ (компьютер) в состоянии выполнять значительное число умственных операций, включая те из них, которые можно отнести к простым творческим актам.
В исследованиях по искусственному интеллекту выделились шесть основных направлений.
1. Представление знаний (создание "баз знаний", формализация и представление в памяти интеллектуальной системы специальных знаний).
2. Манипулирование знаниями (обучение интеллектуальных систем методам и манипулированию знаниями).
3. Общение (например, понимание компьютером текстов на естественном языке, диалог человека и ЭВМ).
4. Восприятие информации (обучение ЭВМ распознаванию образов, анализу зрительной информации).
5. Обучение интеллектуальной системы решению таких задач, с которыми она раньше не встречалась.
6. Создание моделей нормативного, ситуативного, целесообразного поведения.
В исследованиях по искусственному интеллекту используется следующий комплекс методов: методы математической логики, язык фреймов, методы математической и прикладной лингвистики; методы когнитивной психологии, исследующей механизм познания и др.
В теории искусственного интеллекта используется понятие "модель мира". Так, модель мира, отраженная в сознании юриста, состоит из следующих основных частей:
объекты правового регулирования в целом;
специальные объекты правового регулирования (экономика, политика, научно-технический прогресс и др.);
общие модели правового регулирования;
специальные модели правового регулирования.
Право и законодательство России (как и любой страны) могут вполне обоснованно рассматриваться как сложные интеллектуальные системы. Так, плотность юридической информации на единицу текста закона исключительно велика. Особый класс — федеральные конституционные законы, включающие сложные проблемы регулирования наиболее существенных сфер деятельности общества: политики, экономики, социальной жизни и т. д. Трудность правового регулирования определяется прежде всего тем, что в данной сфере объектом управленческого воздействия выступают разнообразные по своим качественным параметрам явления и социальные процессы с наличием сложнейшего человеческого фактора. Мыслительной деятельности юриста (судьи, криминалиста, судебного эксперта и др.) присущ высокий уровень интеллектуальности, специализации и профессионализма.
Для интеллектуальных систем характерно наличие базы знании с такими чертами, как внутренняя интерпретируемость, структурированность, связанность, активность. Всякая социальная информация имеет интеллектуальный характер. В информатике появились понятия "интеллектуализация", интеллектуальная система", "интеллектуальная технология", "интеллектуальный интерфейс" и другие средства "гуманизации" ЭВМ и создания интеллектуальных машин пятого поколения. Интеллектуальную природу имеют и автоматизированные информационные системы в области права.
Материал в правовой сфере столь велик по объему и столь сложен по содержанию, что создание интеллектуальных, в частности экспертных, систем не только возможно, но и необходимо. Интеллектуальные системы и технологии проникают и в сферу законодательства. Указ Президента РФ "Концепция правовой информатизации России" ориентирует работу по информатизации правовой сферы на применение новейших технологий. Указ прямо говорит о необходимости использования в правовой сфере элементов искусственного интеллекта. Однако в целом в концепции и программе информатизации правовой сферы России задачи применения интеллектуальных систем и технологий отражены недостаточно.*
* Система искусственного интеллекта и, прежде всего, экспертные системы отнесены к основным компонентам информационной инфраструктуры Генеральной прокуратуры РФ.
Большую роль системы играют в правоприменительной практике США. Руководством ФБР утверждена стратегия компьютеризации своих служб. Исследовались возможность и эффективность применения статистических систем распознавания при создании четырех информационных систем и получены практические результаты.
В ряде стран приняты специальные программы внедрения интеллектуальных технологий и систем в государственно-правовую сферу. Так, в Главном полицейском управлении Японии разрабатываются: система помощи консультативным пунктам по проблемам преступности несовершеннолетних; система расследования крупных экономических преступлений и др.
В настоящее время сложились следующие основные направления применения интеллектуальных технологий в правовой сфере.
Создание экспертных систем. В середине 70-х годов в исследованиях по искусственному интеллекту сформировалось перспективное направление, получившее название "экспертные системы". Экспертная система — это человеко-машинный комплекс, основанный на профессиональных данных специалистов соответствующей сферы, имеющий внутреннюю логику (совокупность, как правило, математически выраженных правил умственной деятельности), способный генерировать решения по существу рассматриваемой проблемы.
Простые экспертные системы, рассчитанные на широкий круг пользователей, создаются в период до 4 лет, стоимость их разработки составляет до 300 тыс. долл. (сложные экспертные системы — до 10 млн. долл.). В США рынок экспертных систем составил в 1986 г. 130 млн. долл., в 1995 г. — 8—10 млрд. долл.*
* По имеющимся прогнозам мировой рынок экспертных систем в 2000 г. составит 60 млрд. долл. Исследования и разработка экспертных систем составляют основу программ развитых стран по искусственному интеллекту.
Различают следующие типы экспертных систем:
1) интеграционные, цель которых — извлечение описаний ситуации из данных;
2) диагностические, цель — установление диагноза;
3) проектирующие, цель — проектировать какой-либо объект;
4) планирующие, цель — распределение действий по различным сценариям;
5) мониторинговые — служащие для сравнения различных ситуаций;
6) образовательные, цель — создание систем автоматизированного обучения;
7) контрольные, цель — осуществление контроля за протеканием изучаемого процесса.
Особенность интеллектуальных ЭВМ заключается в том, что они используют не базы данных, а базы знаний. Знанием является проверенный практикой результат познания действительности. Применительно к правовой сфере знание — это накопленные человечеством инстинкты, факты, принципы и прочие объекты правового познания. Поэтому в отличие от базы данных в базе знаний располагаются познаваемые сведения, содержащиеся в документах, книгах, статьях, отчетах.
В работе "Экспертные системы в праве" английский юрист Р. Сасскинд отмечает, что искусственный интеллект в приложении к праву — это интеллектуальные системы, которые представляют собой программы, составленные таким образом, чтобы они могли действовать как эксперты в определенных областях. Подобные системы настолько удобны в работе, что у специалистов появился оценочный эпитет "интеллектуальный помощник". Согласно точке зрения Сасскинда только тогда, когда широта и глубина знаний в определенной области позволяют системе выступать в качестве эксперта, можно говорить об экспертной системе. Экспертные системы объясняют, аргументируют и делают выводы.
Экспертная система составляется юристами — обычно узкими специалистами в какой-либо области права — и предназначена функционировать в качестве помощника в процессе решения юридических задач исключительно в одной области (а также в учебных целях). Пользователями таких систем обычно являются юристы-практики, сталкивающиеся с задачами, находящимися вне области их компетенции.*
* Экспертиза специалиста-юриста требуется, в частности, при составлении юридических документов, допросе, интервьюировании (опросе) клиентов, разработке судебных процедур.
Создание высокоэффективных экспертных систем требует использования разнообразных знаний. Важное место в их системе занимает язык фреймов. Понятие "фрейм" было введено в науку американским ученым Марвином Минским (1979). Язык фреймов является идеальным средством моделирования юридических конструкций различного уровня. Фрейм — ячейка, куда попадает информация. Во фреймах происходит процесс восприятия и переработки информации. Обобщая имеющиеся данные с языка фреймов, можно утверждать следующее. Фрейм — это структура данных, предназначенных для представления стереотипной ситуации. Когда человек сталкивается с новой ситуацией, он извлекает из памяти структуру, называемую фреймом. Фрейм можно представить в виде сети из узлов и отношений. Имеется несколько конструкций фреймов и различных точек зрения на разновидности фреймов и приемы их использования в процессе создания экспертных систем.
Фрейм имеет имя (название) и состоит из частей, называемых слотами. Изображается фрейм в виде цепочки:
Фрейм = (слот 1) (слот 2)... (слот n).
Итак, фрейм — это типическая конструкция, которая выражает в формализованной форме устойчивые связи и отношения объективной действительности.
Из изложенного следует большое генетическое сходство языка фреймов и языка права. Праву также присущи определенные формальные конструкции. Они пронизывают всю "ткань" права. Их позитивную роль трудно переоценить. Наличие таких конструкций повышает уровень правоприменительной деятельности, существенно облегчая правотворческий процесс.
В форме фрейма могут быть представлены некоторые иные структурные элементы правового текста, такие как "юридическая обязанность", "юридический запрет", "субъект права", "динамика права" и др. (см. рис. 9).
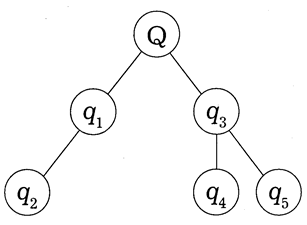
Q — наименование фрейма
q1 и q2 — атрибутивная характеристика права (политические, экономические и иные права)
q3 — общий объект права (право на что?)
q4 и q5 — право на действие и право на вещь
Рис. 9 Семантическая сеть фрейма "иметь право"
В процессе формирования базы данных и разработки экспертной системы язык фреймов может эффективно использоваться для семантического представления: структуры правовых понятий; структуры правовых ситуаций; юридических конструкций.
Начиная с 1970 г. в Великобритании и США создан и внедрен в юридическую практику целый ряд экспертных систем. Это системы "Таксоман", "Миг-проект", "Юдит", "Лирс" и другие, всего более 25. Они используются при составлении юридических документов и договоров, интервьюировании клиентов, допросах, разработке тактики и стратегии судебных процедур. Системы объясняют сложные правовые ситуации и цитируют используемые источники, а также находят юридические аргументы в процессе логической аргументации. Они задают вопросы пользователю, направляя ход его мыслей. Большинство этих систем использует ту или иную теорию или философию права. Многие системы исходят из постулатов позитивной нормативной теории права, разработанной Г. Кельзеном.
Первые простейшие интеллектуальные системы были созданы в СССР в 60-е и 70-е гг.* Такие системы позволяли при помощи ЭВМ выполнять квалификацию сложных фактических составов. В 60-е гг. вопросы моделирования правоприменительной деятельности оказались в центре внимания академика В. Н. Кудрявцева. В. Н. Кудрявцев отмечает, что различные. юридические правила, институты, отдельные нормы в совокупности и порознь содержат множество различных алгоритмов (например, ст. 303 УПК РСФСР о последовательности вопросов, разрешаемых при вынесении приговоров), имеющих, однако, слишком общий характер. Тем не менее могут быть построены программы, упорядочивающие процесс квалификации юридически значимых действий. В 1970 г. В. Н. Кудрявцев провел психологический эксперимент, в задачи которого входило изучение эвристических свойств процесса применения норм права при квалификации преступлений. В результате эксперимента установлено, что фактически решение задачи у большинства испытуемых складывается из двух частей: построение и использование алгоритма опознания типа задачи и использования алгоритма в собственном смысле слова. Опознание типа задачи имеет своей целью приблизительное определение области, в которой следует искать решение. Вместе с ним перестраивается и основной алгоритм квалификации.
* Это оригинальные работы в области трудового, пенсионного, хозяйственного права. Их авторы: Л. Б. Гальперин, А. Ф. Деев, А. Г. Ольшанецкий, С. С. Москвин, Б. Я. Ковалерчук и др.
В 90-е гг. серия содержательных работ по созданию программ и алгоритмов квалификации различных преступлений. выполнена в НИИ проблем укрепления законности и правопорядка Генеральной прокуратуры РФ (руководитель работ — Б. В. Андреев). Ряд программ внедрен в практику работы органов прокуратуры.
Создание интеллектуальных информационно-поисковых систем. Существующие информационно-поисковые системы недостаточно эффективны.
Интеллектуальная ИПС обрабатывает запросы, сформулированные на обычном "разговорном" языке, что особенно привлекательно для рядового пользователя, не желающего обременять себя различными лингвистическими тонкостями типа падежных окончаний или знанием командных языков и булевой алгебры для правильной комбинации ключевых слов при формулировке запроса.
Система DIANA опирается на новые интеллектуальные средства обработки пользовательских запросов на естественном языке.
Автоматизированный анализ нормативных правовых текстов. Существующие методы обработки НПА не в состоянии полностью удовлетворить потребности правотворческой деятельности. Необходимы существенно новые методы, основанные на результатах исследования механизмов мышления юриста и на базах знаний и опыта, накопленного при разработке нормативных правовых актов.
Одной из форм автоматизированного анализа НПА является их классификация. Автоматизированный анализ нормативных текстов основан на использовании современной компьютерной техники для обработки и обобщения информационных потоков.*
* Компьютерной фирмой Redlab разработана программа, позволяющая обрабатывать поток политической информации, поступающей с телетайпной ленты. Используемые при этом методы представляют интерес и для правовой информатики.
Методология разработки автоматизированного рубрицирования основывается на системе выделения унитермов. Идея выделения унитермов была предложена в 1952 г. немецким ученым М. Таубом. Он предположил, что содержание и смысл любого документа могут быть выражены набором некоторых слов (унитермов), встречающихся в тексте документов. Если один и тот же термин применяется много раз, то это свидетельствует о его типичности (характерности) для данного документа (отрасли законодательства, рубрики НПА). Однако нельзя ограничиваться выделением одного какого-либо слова или небольшой группы слов, ибо они могут встречаться и в других отраслях законодательства.
Удобным приемом, используемым в процессе создания семантического образа НПА, является использование заголовков нормативных правовых актов и входящих в них разделов. Такие заголовки семантически коррелируют с содержанием текста закона, выражая его концентрическое содержание.
Заголовки могут содержать:
1) упоминание о субъекте данной отрасли законодательства;*
2) указание на регулирование какого-либо социально-экономического процесса;
3) указание на предмет правового регулирования.
* Например, заголовок содержит такой термин, как "суд".
Необходимо использовать и статистический подход. Термин, который встречается в данном НПА наиболее часто, может быть с уверенностью включен в число идентифицирующих. В процессе работы компьютера происходит сравнение двух образов: "образа" отрасли законодательства (рубрики) и "образа" НПА. При их совпадении компьютер относит поступивший НПА к определенной рубрике.
Требования, которые содержатся в вышестоящих законодательных актах, а также сформулированы в науке и практике, могут быть формализованы. Но "лобовая" атака на проблему автоматизированного анализа правовых норм не сулит особого успеха. Автоматизированное сравнение всех правовых текстов практически невозможно в силу значительной сложности нормативных актов и их большой политематичности.
Для выявления противоречий в НПА необходимо разработать критерии создания баз нормативных требований, которые фактически предъявляются к актам и нормам в различных сферах правового регулирования.
Модель НПА должна быть автоматически сравнена с данными, которые хранятся в базе проблемной информации. Это позволяет выявить и получить на экран компьютера именно ту информацию, с которой в режиме активного диалога должна сравниваться проектируемая правовая информация (акт, часть акта и т. д.).
Чтобы проанализировать содержание законодательного акта НПА на непротиворечивость, необходимо в первую очередь обладать информацией о том, как акты взаимосвязаны. Те из них, которые значительно удалены друг от друга в семантическом пространстве, не подлежат проверке на непротиворечивость, ибо они относятся к совершенно разным предметным областям и сферам регулирования.
В заключение следует сказать, что применение компьютера и интеллектуальных технологий в правотворчестве позволяет вывести этот процесс на более высокий уровень. Вместе с тем следует учитывать, что создание законодательных актов является творческим процессом высокой степени сложности. Полной алгоритмизации этот процесс не поддается. Компьютер не в состоянии "создать" законопроект.
Создание законопроектов — сложнейшая задача, при решении которой реализуются высшие творческие функции человеческого мышления. Невозможность эффективно применять ЭВМ для создания приемлемых законопроектов обусловлена рядом факторов. Среди них и такие, как невозможность компьютерного моделирования процессов постоянного познания и обобщения социальной и правовой реальности на уровне законопроекта в целом, отдельного института, отдельной правовой нормы. Следует иметь в виду и то, что каждая правовая норма требует своего алгоритма создания и моделирования.
§ 2. Информатика и кибернетика
Развитие информатики тесно связано с развитием другой, близкой к ней, науки — кибернетики (общей теории управления). Применительно к праву речь должна идти о такой отрасли знания, как правовая кибернетика.
В 60-е и 70-е гг. кибернетика бурно прогрессировала. Кибернетические и информационные идеи рассматривались нераздельно. При этом идеи информатики занимали подчиненную роль по отношению к идеям и методам кибернетики.
В конце 70-х гг. началось формирование информатики как самостоятельной науки, что привело к определенному принижению роли и значения кибернетики. В настоящее время наметилась другая крайность: некоторые специалисты стали рассматривать кибернетику в качестве части информатики, что принципиально неверно.
Огромная заслуга американского ученого Норберта Винера и его последователей состоит в том, что установлена общность принципов управления в сложных системах живой и неживой природы. Винер дал обширную логико-функциональную трактовку регулирования (управления), назвав его кибернетикой. Базой послужила классическая теория регулирования с обратной связью, основы которой были заложены трудами Платона, Ампера, Максвелла, Вышнеградского, Ляпунова и других ученых.*
* Вместе с тем Н. Винер не дал систематического изложения идей кибернетики.
Тем самым проблема управления в технических, биологических и социальных системах была поставлена во всей полноте, чем положено начало глубокому и всестороннему ее изучению.*
* В последнее время развиваются экономическая, техническая, биологическая кибернетика, нейрокибернетика, однако пока нет "полного и убедительного изложения общей кибернетики как самостоятельной науки.
Академику А. И. Бергу принадлежит известное определение кибернетики как науки об оптимальном управлении любыми сложными динамическими системами, основанной на теоретическом фундаменте логики и математики и применении средств автоматизации, информационно-логических машин.
Великий русский ученый А. Н. Колмогоров создал математическую теорию об интерполировании и экстраполяции случайных последовательностей, обосновал ряд фундаментальных положений об интеллектуальных системах. В. М. Глушков рассматривал кибернетику как науку "об общих законах преобразования информации в сложных управляющих системах".*
* Одновременно появилась неправильная тенденция расширения предмета кибернетики: в число кибернетических стали включать любые исследования с применением ЭВМ и математических методов.
При этом исследовалась зависимость между управлением и информацией. Любой системе управления объективно присущи информационные связи. Информационная модель социального управления отражает совокупность информационных потоков, которые обусловлены решением поставленных (управленческих) задач. Закрепление в нормативном порядке информационных параметров — важное свойство крупных законодательных и иных правовых актов. Например, в международно-правовых актах — это контроль за поведением и деятельностью субъектов международного права, меры инспектирования и взаимной проверки.
С учетом определения кибернетики, данного академиком А. И. Бергом, можно утверждать, что правовая кибернетика — это научная дисциплина, изучающая особенности процессов управления и регулирования в сфере государства и права на фундаменте математики, логики и моделирования.
Можно сделать следующие выводы: информатика и кибернетика — это разные науки. Соответственно разными являются такие науки, как правовая информатика и правовая кибернетика (отрасль общей теории управления).
Таким образом, общая и правовая кибернетика полностью сохраняет "свое лицо". Статус правовой кибернетики как самостоятельной отрасли научно-практического знания должен быть восстановлен.
В структуре правовой кибернетики можно будет выделить следующие проблемы:
1) правовые аспекты понятий "управление" и "регулирование";
2) эффективность и оптимальность правового регулирования;
3) устойчивость систем регулирования;
4) системы управления в правовой сфере;
5) адаптивные процессы;
6) системный анализ и математическое моделирование;
Все это должно учитываться при подготовке юридических кадров и становлении правовой кибернетики как особого средства управления.
В 70-е гг. процесс разработки автоматизированных систем в юридической сфере находился под сильным влиянием концепций, связанных с созданием АСУ (автоматизированных систем управления) — формы организации социального управления, сущность которой заключается в активном использовании ЭВМ с целью повышения эффективности сбора и обработки информации для принятия на ее основе управленческих решений. Концепция АСУ оказала влияние на юридическую сферу. Стали создаваться АСУ — МВД, АСУ — Прокуратура, АСУ — Юстиция, АСУ — Верховный Суд.*
* Идеологом работ по созданию АСУ был выдающийся ученый академик В. М. Глушков. Под его руководством выполнялись работы по созданию Объединенной государственной автоматизированной системы (ОГАС).
Однако автоматизированные системы в том виде, как они конструировались в прошлом, да и в настоящее время, не являются, строго говоря, системами управления. По существу, они имеют информационный характер. Ведь за этапами сбора первичной обработки, хранения и поиска информации следуют стадии ее анализа, синтеза и самое главное — принятия решения. А именно эти стадии не охвачены концепцией АСУ.
Таким образом, широкая трактовка категории "АСУ" стала демонстрировать свои глубокие недостатки. В настоящее время наблюдается тенденция к разграничению АСУ и некоторых близких систем.
АСУ в подлинном смысле слова рассчитана на выработку управленческих решений или на формирование в результате анализа — синтеза существенных черт подобного рода решений; при этом широко используются экономико-математические и социально-математические методы.
Системы новых поколений, близкие к АСУ, но не эквивалентные ей, следует называть автоматизированными системами информационного обеспечения (АСИО). На большее они не рассчитаны, хотя и это немало.
На рубеже 70—80-х гг. концепция информатизации пра-воприменительньгх органов значительно изменилась. Из практических разработок стал исчезать термин "АСУ". На смену пришли другие понятия: АСИО-Прокуратура, АСИО-Юстиция, Информационно-вычислительные сети МВД РФ, что является значительно более точным.

