 2015-06-04
2015-06-04 926
926Понятие простого типа данных носит двойственный характер. С точки зрения размерности микропроцессор аппаратно поддерживает следующие основные типы данных:
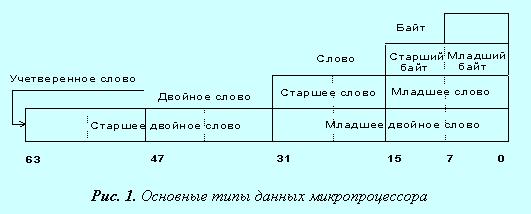
· байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
· слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
· двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам. Нумерация этих бит производится от 0 до 31. Слово, содержащее нулевой бит, называется младшим словом, а слово, содержащее 31-й бит, - старшим словом. Младшее слово хранится по меньшему адресу. Адресом двойного слова считается адрес его младшего слова. Адрес старшего слова может быть использован для доступа к старшей половине двойного слова.
· учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам. Нумерация бит производится от 0 до 63. Двойное слово, содержащее нулевой бит, называется младшим двойным словом, а двойное слово, содержащее 63-й бит, — старшим двойным словом. Младшее двойное слово хранится по меньшему адресу. Адресом учетверенного слова считается адрес его младшего двойного слова. Адрес старшего двойного слова может быть использован для доступа к старшей половине учетверенного слова.
Кроме трактовки типов данных с точки зрения их разрядности, микропроцессор на уровне команд поддерживает логическую интерпретацию этих типов:
· Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
8-разрядное целое — от –128 до +127;
16-разрядное целое — от –32 768 до +32 767;
32-разрядное целое — от –231 до +231–1.
· Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
байт — от 0 до 255;
слово — от 0 до 65 535;
двойное слово — от 0 до 232–1.
· Указатель на память двух типов:
ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
· Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
· Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
· Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
· Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
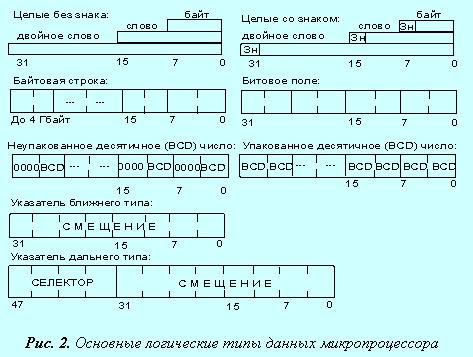
Отметим, что “ Зн ” на рис. 2 означает знаковый бит.
После всего сказанного было бы логичным возникновение вопроса: как описать эти простые типы данных ассемблера, а затем и воспользоваться ими в программе? Ведь любая программа предназначена для обработки некоторой информации, поэтому вопрос о том, как описать данные с использованием средств языка обычно встает одним из первых.
TASM предоставляет очень широкий набор средств описания и обработки данных, который вполне сравним с аналогичными средствами некоторых языков высокого уровня.








