 2015-06-28
2015-06-28 1067
1067Цель занятия – освоить приёмы работы со средствами статистической обработки данных в Excel и использования инструмента Пакет анализа.
К статистическим методам изучения случайных явлений прибегают в тех случаях, когда требуется изучить распределение большой совокупности однородных предметов (явлений, объектов, индивидуумов) по некоторому признаку. Например, когда необходимо проанализировать распределение осуждённых по полу, возрасту, статье, сроку наказания и т.д. Понятно, что исчерпывающее описание такого распределения можно получить, выяснив значение признака для всех без исключения представителей данной (как правило, большого объёма) совокупности. Поэтому на практике поступают обычно так: обследование всей совокупности заменяют обследованием небольшой её части. Такую часть называют выборкой, а всю совокупность – генеральной совокупностью.
В настоящее время имеется развитый математический аппарат, позволяющий по результатам обследования выборки делать обоснованные заключения о распределении признака по всей совокупности. В этой связи статистическую обработку данных можно свести к вычислениям по известным формулам. Excel содержит 97 статистических функций, представленных, в частности, в табл. 10.3. Выбрать нужную функцию можно из списка функций в категории «Статистические» (рис. 10.26).
Таблица 10.3
| Имя функции | Описание функции |
| ДИСП.В | Оценивает дисперсию по выборке |
| КВАДРОТКЛ | Возвращает сумму квадратов отклонений от среднего по выборке |
| КОВАРИАЦИЯ.В | Возвращает ковариацию для выборки, т.е. среднее произведений отклонений для каждой пары точек данных в двух наборах данных |
| КОРРЕЛ | Возвращает коэффициент корреляции между двумя множествами данных |
| СРЗНАЧ | Возвращает среднее арифметическое аргументов |
Рис. 10.26. Порядок выбора статистической функции
При проведении сложного статистического анализа данных можно упростить процесс и сэкономить время, используя надстройку Пакет анализа. Для анализа данных с помощью этого пакета следует указать входные данные и выбрать параметры; расчёт будет выполнен с помощью подходящей статистической макрофункции, а результат будет помещен в выходной диапазон. Некоторые инструменты позволяют представить результаты анализа в графическом виде.
Для доступа к инструментам, включенным в пакет анализа, нужно нажать кнопку Анализ данных ( )в группе Анализ на вкладке Данные. Если кнопка Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа»[3]:
)в группе Анализ на вкладке Данные. Если кнопка Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа»[3]:
1. На вкладке Файл выберите команду Параметры, а затем – категорию Надстройки.
2. В списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3. В окне Доступные надстройки (рис. 10.27) установите флажок Пакет анализа и нажмите кнопку ОК.
При нажатии кнопки Анализ данных () откроется окно «Анализ данных», в котором из списка необходимо выбрать нужный инструмент. Рассмотрим основные из них.
Пакет анализа позволяет выполнять три вида дисперсионного анализа: однофакторный, двухфакторный с повторениями и двухфакторный без повторений. Нужный вариант выбирается с учётом числа факторов и имеющихся выборок из генеральной совокупности (табл. 10.4).
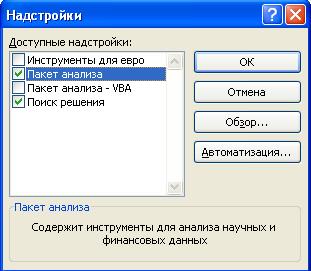
Рис. 10.27. Окно Доступные настройки
Инструменты «Корреляция» и «Ковариация» применяются для одинаковых значений, если в выборке наблюдается N различных переменных измерений. Оба вида анализа возвращают таблицу (матрицу), показывающую коэффициент корреляции или ковариацию соответственно для каждой пары переменных измерений. В отличие от коэффициентов корреляции, масштабируемых в диапазоне от -1 до +1 включительно, соответствующие значения ковариации не масштабируются. Оба вида анализа характеризуют степень «совместного изменения» двух переменных.
Инструмент ковариационного анализа вычисляет значение функции КОВАР для каждой пары переменных измерений (напрямую использовать функцию КОВАР вместо ковариационного анализа имеет смысл при наличии только двух переменных измерений, т.е. при N = 2). Элемент по диагонали таблицы, возвращаемой инструментом ковариационного анализа, в строке i и столбце i, является значением ковариации i -ой переменной измерения с самой собой; это всего лишь дисперсия генеральной совокупности для данной переменной, вычисляемая функцией ДИСПР.
Ковариационный анализ даёт возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Таблица 10.4
| Вид дисперсионного анализа | Условия применения |
| Однофакторный | Служит для анализа дисперсии по данным двух или нескольких выборок. При анализе гипотеза о том, что каждый пример извлечен из одного и того же базового распределения вероятности, сравнивается с альтернативной гипотезой, предполагающей, что базовые распределения вероятности во всех выборках разные. Если выборок только две, можно применить функцию ТТЕСТ. Для трёх и более выборок не существует более общего варианта функции ТТЕСТ, но вместо этого можно воспользоваться моделью однофакторного дисперсионного анализа. |
| Двухфакторный с повторениями | Применяется, если данные можно систематизировать по двум параметрам. Например, данные о количестве осуждённых по конкретной статье УК в трёх регионах (A, B, C) по двум возрастным группам (несовершеннолетние, совершеннолетние). Таким образом, для каждой из 6 возможных пар условий {регион, возраст}, имеется набор наблюдений за количеством осуждённых. Тогда можно проверить следующие гипотезы: 1) извлечены ли данные о количестве осуждённых для различных регионов из одной генеральной совокупности. Возраст в этом анализе не учитывается; 2) извлечены ли данные о количестве осуждённых для различных возрастных групп из одной генеральной совокупности. Регион в этом анализе не учитывается. |
| Двухфакторный без повторений | В отличие от предыдущего предполагает, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {регион, возраст} из предыдущего примера). |
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлечёнными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов.
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчёта, содержащего информацию о центральной тенденции и изменчивости входных данных.

