 2015-07-14
2015-07-14 407
407Метод обратного распространения ошибки - это способ быстрого расчета градиента, основанный на особенностях функции пересчета сети, которые позволяют сократить вычислительную сложность расчета градиента. Метод использует ошибку на выходе сети для расчета частных производных по весам последнего слоя обучаемых связей, затем по весам последнего слоя и ошибке сети определяется ошибка на выходе предпоследнего слоя и процесс повторяется.
Описание алгоритма. Обратное распространение ошибки применяется к многослойным сетям, нейроны которых имеют нелинейность с непрерывной производной, например такую:
Нелинейность такого вида удобна простотой расчета производной: 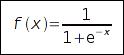 Для обучения сети используется P пар векторов сигналов:
Для обучения сети используется P пар векторов сигналов: 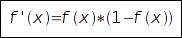 входной вектор I и вектор, который должен быть получен на выходе сети D. Сеть, в простом случае, состоит из N слоев, причем каждый нейрон последующего слоя связан со всеми нейронами предыдущего слоя связями, с весами w [n]. При прямом распространении, для каждого слоя рассчитывается (и запоминается) суммарный сигнал на выходе слоя (S [n]) и сигнал на выходе нейрона. Так, сигнал на входе i-го нейрона n-го слоя:
входной вектор I и вектор, который должен быть получен на выходе сети D. Сеть, в простом случае, состоит из N слоев, причем каждый нейрон последующего слоя связан со всеми нейронами предыдущего слоя связями, с весами w [n]. При прямом распространении, для каждого слоя рассчитывается (и запоминается) суммарный сигнал на выходе слоя (S [n]) и сигнал на выходе нейрона. Так, сигнал на входе i-го нейрона n-го слоя: 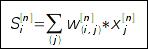 Здесь w (i,j) - веса связей n-го слоя. Сигнал на выходе нейрона рассчитывается применением к суммарному сигналу нелинейности нейрона:
Здесь w (i,j) - веса связей n-го слоя. Сигнал на выходе нейрона рассчитывается применением к суммарному сигналу нелинейности нейрона: 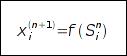 Сигнал выходного слоя x [N] считается выходным сигналом сети O. По выходному сигналу сети O и сигналу D, который должен получится на выходе сети для данного входа, рассчитываться ошибка сети. Обычно используется средний квадрат отклонения по всем векторам обучающей выборки:
Сигнал выходного слоя x [N] считается выходным сигналом сети O. По выходному сигналу сети O и сигналу D, который должен получится на выходе сети для данного входа, рассчитываться ошибка сети. Обычно используется средний квадрат отклонения по всем векторам обучающей выборки: 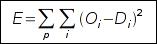 Для обучения сети используется градиент функции ошибки по весам сети. Алгоритм обратного распространения предполагает расчет градиента функции ошибки "обратным распространением сигнала" ошибки. Тогда частная производная ошибки по весам связей рассчитывается по формуле:
Для обучения сети используется градиент функции ошибки по весам сети. Алгоритм обратного распространения предполагает расчет градиента функции ошибки "обратным распространением сигнала" ошибки. Тогда частная производная ошибки по весам связей рассчитывается по формуле: 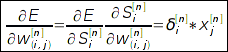 Здесь δ - невязка сети, которая для выходного слоя рассчитывается по функции ошибки:
Здесь δ - невязка сети, которая для выходного слоя рассчитывается по функции ошибки: 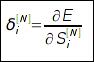 А для скрытых слоев - по невязке предыдущего слоя:
А для скрытых слоев - по невязке предыдущего слоя: 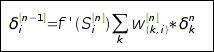 Для случая сигмоидной нелинейности и среднего квадрата отклонения как функции ошибки:
Для случая сигмоидной нелинейности и среднего квадрата отклонения как функции ошибки: 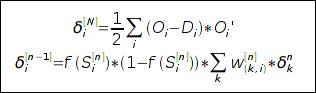 Собственно обучение сети состоит в нахождении таких значений весов, которые минимизируют ошибку на выходах сети. Существует множество методов, основанных или использующих градиент, позволяющих решить эту задачу. В простейшем случае, обучение сети проводится при помощи небольших приращений весов связей в направлении, противоположенном вектору градиента:
Собственно обучение сети состоит в нахождении таких значений весов, которые минимизируют ошибку на выходах сети. Существует множество методов, основанных или использующих градиент, позволяющих решить эту задачу. В простейшем случае, обучение сети проводится при помощи небольших приращений весов связей в направлении, противоположенном вектору градиента: 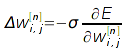 Такой метод обучения называется "оптимизация методом градиентного спуска" и, в случае нейросетей, часто считается частью метода обратного распространения ошибки.
Такой метод обучения называется "оптимизация методом градиентного спуска" и, в случае нейросетей, часто считается частью метода обратного распространения ошибки.








