 2015-08-13
2015-08-13 1387
1387Першим етапом побудови дерева рішень є налаштування призначення полів.
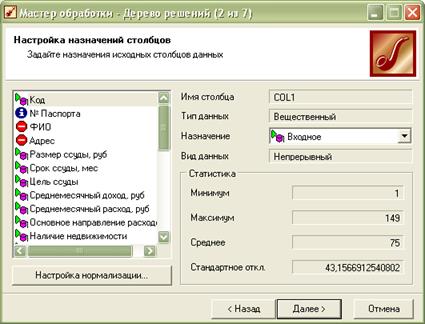
Рисунок 1.3 – Вікно програми Deductor на 2 кроці процесу побудови дерева рішень: налаштування призначення стовпців
Тут необхідно вказати, як будуть використовуватися поля початкового набору даних при навчанні дерева і подальшій практичній роботі з ним. У лівій частині вікна є список всіх полів вхідного набору даних. Для налаштування поля потрібно виділити його в списку, при чому в правій частині вікна відображаються поточні параметри поля:
- Ім'я стовпця – ідентифікатор поля, визначений у вхідному наборі даних, який тут змінити не можна.
- Тип даних – тип даних, що містяться у відповідному стовпці (дійсний, стрічковий, дата, тощо). Тип даних також задається у вхідному наборі та не можу тут змінюватись.
- Призначення – тут необхідно вибрати спосіб використання даного поля при навчанні та роботі дерева рішень. Вибір здійснюється за допомогою випадаючого списку:
· 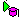 Вхідне – значення поля будуть вхідними даними для побудови і подальшої практичної роботи дерева рішень, на їх основі буде здійснюватись класифікація.
Вхідне – значення поля будуть вхідними даними для побудови і подальшої практичної роботи дерева рішень, на їх основі буде здійснюватись класифікація.
·  Вихідне – це поле буде містити результати класифікації. Вихідне поле може бути тільки одне та воно має бути дискретним.
Вихідне – це поле буде містити результати класифікації. Вихідне поле може бути тільки одне та воно має бути дискретним.
·  Інформаційне – поле не буде використатися при навчанні дерева, але буде поміщене в результуючий набір без змін.
Інформаційне – поле не буде використатися при навчанні дерева, але буде поміщене в результуючий набір без змін.
·  Невикористовуване – поле не буде використовуватися при побудові та роботі дерева рішень та буде виключене з результуючої вибірки. Навідміну від непридатного, таке поле може бути використаним, якщо в цьому виникне необхідність.
Невикористовуване – поле не буде використовуватися при побудові та роботі дерева рішень та буде виключене з результуючої вибірки. Навідміну від непридатного, таке поле може бути використаним, якщо в цьому виникне необхідність.
·  Непридатне – поле не може бути використаним при побудові та роботі алгоритму, але буде поміщено в результуючий набір без змін.
Непридатне – поле не може бути використаним при побудові та роботі алгоритму, але буде поміщено в результуючий набір без змін.
- Вид даних – вказує на характер даних, що містяться в полі (неперервний або дискретний). Цю властивість також не можна тут змінити. В залежності від виду даних внизу відображаються певні характеристики значень для даного поля.
Статус непридатного поля встановлюється тільки автоматично та надалі може бути зміненим лише на невикористовуване або інформаційне. Поле стає непридатним, якщо:
- поле є дискретним і містить всього одне унікальне значення;
- неперервне поле з нульовою дисперсією (відхиленням);
- поле містить пропущені значення.
За допомогою кнопки «Налаштування нормалізації» можна здійснити нормалізацію вхідних даних, налаштувавши параметри у відповідному вікні.
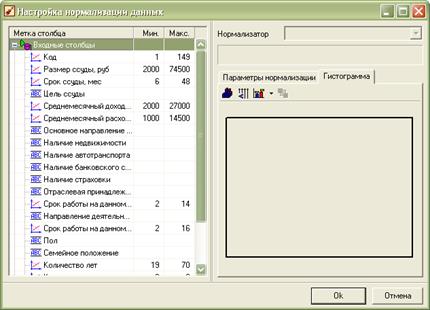
Рисунок 1.4 – Вікно нормалізації даних
Метою нормалізації значень полів є перетворення даних до вигляду, який найкраще підходить для опрацювання засобами пакету Deductor. Для побудови дерева рішень дані, що надходять на вхід, повинні мати числовий тип. У цьому випадку нормалізатор може перетворити дискретні дані в набір унікальних індексів.
Для кожного поля визначається свій вид нормалізації поля:  лінійна нормалізація вихідних значень або
лінійна нормалізація вихідних значень або  перетворення унікальних значень у їх індекси.
перетворення унікальних значень у їх індекси.
Наступним кроком необхідно задати налаштування навчальної вибірки.
Рисунок 1.5 – Вікно програми Deductor на 3 кроці процесу побудови дерева рішень: налаштування навчальної та тестової вибірок
Тут можна розбити навчальну вибірку для на дві підмножини – навчальну та тестову.
- Навчальна множина – включає записи (приклади або об’єкти), які будуть використовуватися в якості вхідних даних та відповідних бажаних вихідних значень.
- Тестова множина – також включає записи із вхідними та бажаними вихідними значеннями, але використовується не для навчання моделі, а для перевірки результатів.
Для розбивки вихідної множини навчальну та тестову необхідно налаштувати ряд параметрів:
- Зі списку «Спосіб поділу вихідної множини» вибирається порядок відбору записів в усі три множини: вхідну, навчальну та тестову. Якщо обрано варіант «По порядку», то порядок записів при їх поділі не змінюється. Множини послідовно формуються відповідно до заданої для них кількості записів. Якщо ж обрано варіант «Випадково», то відбір записів відбувається випадковим чином.
- Далі необхідно вказати, які множини будуть використовуватися. Для того щоб множинабула сформована, потрібно встановити прапорець ліворуч від його назви. Якщо прапорець не встановлений, то множина використовуватися не буде. Навчальна множина використовується завжди, тому скинути прапорець для неї не можна.
- Для кожної з використовуваних множин потрібно задати її розмір, який може задаватись кількістю записів або у відсотках від обсягу вхідної вибірки. Для цього у відповідній клітинці треба ввести значення з клавіатури. Можна використовувати не всі записи, а тільки частину з них – тоді сумарне число записів розраховується автоматично і є меншим за 100%. Якщо ж сумарне число записів буде перевищувати максимальне для даної вхідної вибірки, то автоматично включається баланс множин, тобто при вказанні для однієї з множин розміру, результаті якого сумарне число буде перевищувати максимальне, розмір інших множин буде відповідно зменшеним.
У стовпці «Порядок сортування» можна визначити порядок проходження записів всередині кожної множини. Для цього потрібно двічі клацнути мишкою на стовпці «Порядок сортування» для відповідної множини та вибрати значення з випадаючого меню. У правій частині вікна розташовані кнопки, які дозволяють змінювати порядок застосування множин у процесі навчання.
Важливо: Для того, щоб навчальна множина була репрезентативною, необхідно, щоб у ній були присутні всі унікальні значення всіх дискретних стовпців.
Наступним кроком є налаштування параметрів навчання.
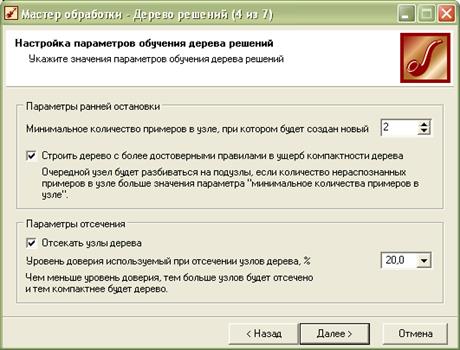
Рисунок 1.6 – Вікно програми Deductor на 4 кроці процесу побудови дерева рішень: налаштування параметрів процесу навчання при побудові дерева рішень
В цьому вікні потрібно задати параметри, відповідно до яких буде проводитися навчання дерева:
- Параметри ранньої зупинки:
· «Мінімальна кількість прикладів, за якої буде створений новий вузол» – якщо у вузол потрапляє менше прикладів, ніж задано, то вузол ввашається листком і подальше розгалуження припиняється.
· «Будувати дерево з більш достовірними правилами, спричиняючи складність дерева» – встановлення прапорця включає спеціальний алгоритм, що збільшує вірогідність результатів класифікації, ускладнюючи структуру дерева. Скидання прапорця, хоча й приводить до спрощення дерева, знижує вірогідність результатів класифікації.
- Параметри відсікання
· «Будувати дерево з більш достовірними правилами, спричиняючи складність дерева» – встановлення прапорця включає спеціальний алгоритм, що збільшує вірогідність результатів класифікації, ускладнюючи структуру дерева. Скидання прапорця, хоча й приводить до спрощення дерева, знижує вірогідність результатів класифікації.
- «Рівень довіри, що використовується при відсіканні вузлів дерева». Значення цього параметра задається у відсотках (вибирається зі списку) і повинне бути в межах від 0% до 100%. Чим більший рівень довіри, тим більш гіллястим вийде дерево. Чим менший рівень довіри, тим більше вузлів буде відсічено при побудові дерева.
Після налаштування параметрів навчання відбувається запуск процесу навчання, під час якого, власне, будується дерево рішень (Мал. 7). Цей процес може зайняти певний час, тривалість якого залежить від величини вхідної вибірки даних та потужності комп’ютера.
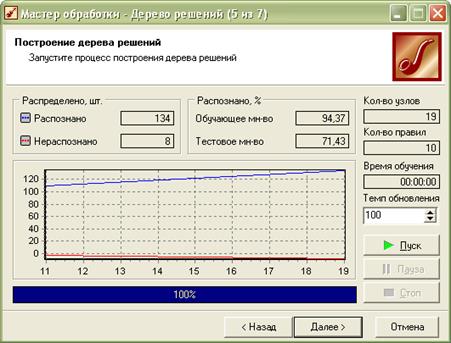
Рисунок 1.7 – Вікно програми Deductor на 5 кроці процесу побудови дерева рішень: побудова дерева рішень
Для керування процесом побудови дерева передбачені відповідні кнопки керування: «Пуск», «Пауза», «Стоп». У секції «Розподілено, шт.» відображається кількість об’єктів навчальної безлічі, які були розпізнані або не розпізнані в процесі побудови дерева. У секції «Розпізнано, %» вказується відсоток розпізнаних об’єктів окремо для навчальної та тестової вибірок – якщо цей відсоток буде досить великим (80%–95%), то побудову дерева можна вважати успішною. Кількість розпізнаних та не розпізнаних у процесі навчання об’єктів відображається на графіку в нижній частині вікна. Розпізнані об’єкти показуються синьою штрих-пунктирною лінією, а нерозпізнані – червоною.
Щоб краще роздивитись будь-яку область на графіку, можна збільшити її масштаб, рухаючи мишкою з натиснутою лівою клавішею у напрямку від лівого верхнього кута до правого нижнього кута. При зміні напрямку руху курсора з правого нижнього кута до лівого верхнього кута масштаб буде зменшуватись.
У правій частині вікна відображається така інформація:
- кількість вузлів в отриманому дереві.
- кількість правил.
- тривалість навчання – час, що пройшов від початку побудови дерева до його завершення.
- темп відновлення – можна задати період відновлення графіка, що відображає побудову дерева.
Під графіком розташований прогрес-індикатор, що відображає процес побудови дерева.
Останнім кроком є вибір способу відображення дерева та присвоєння його назви.








