 2015-08-21
2015-08-21 2352
2352Алгоритм Rprop, или пороговый алгоритм обратного распространения ошибки,
реализует следующую эвристическую стратегию изменения шага приращения параметров для многослойных нейронных сетей.
Многослойные сети обычно используют сигмоидальные функции активации в скрытых слоях. Эти функции относятся к классу функций со сжимающим отображением, поскольку они отображают бесконечный диапазон значений аргумента в конечный диапазон значений функции. Сигмоидальные функции характеризуются тем, что их наклон приближается к нулю, когда значения входа нейрона существенно возрастают. Следствием этого является то, что при использовании метода наискорейшего спуска величина градиента становится малой и приводит к малым изменениям настраиваемых параметров, даже если они далеки от оптимальных значений.
Цель порогового алгоритма обратного распространения ошибки Rprop (Resilient propagation) [36] состоит в том, чтобы повысить чувствительность метода при больших значениях входа функции активации. В этом случае вместо значений самих производных используется только их знак.
Значение приращения для каждого настраиваемого параметра увеличивается с коэффициентом delt_inc (по умолчанию 1.2) всякий раз, когда производная функционала ошибки по данному параметру сохраняет знак для двух последовательных итераций.
Значение приращения уменьшается с коэффициентом delt_dec (по умолчанию 0.5) всякий раз, когда производная функционала ошибки по данному параметру изменяет знак
по сравнению с предыдущей итерацией. Если производная равна 0, то приращение остается неизменным. Поскольку по умолчанию коэффициент увеличения приращения составляет 20 %, а коэффициент уменьшения – 50 %, то в случае попеременного увеличения и уменьшения общая тенденция будет направлена на уменьшение шага изменения параметра. Если параметр от итерации к итерации изменяется в одном направлении,
то шаг изменения будет постоянно возрастать.
Алгоритм Rprop определяет функцию обучения trainrp.
Вновь обратимся к сети, показанной на рис. 3.8, но будем использовать функцию
обучения trainrp:
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},trainrp');
Функция trainrp характеризуется следующими параметрами, заданными по умолчанию:
net.trainParam
ans =
epochs: 100
show: 25
goal: 0
time: Inf
min_grad: 1.0000e–006
max_fail: 5
delt_inc: 1.2000
delt_dec: 0.5000
delta0: 0.0700
deltamax: 50
Здесь epochs – максимальное количество циклов обучения; show – интервал вывода информации, измеренный в циклах; goal – предельное значение критерия обучения; time – предельное время обучения; min_grad – минимальное значение градиента; max_fail – максимально допустимый уровень превышения ошибки контрольного подмножества по сравнению с обучающим; delt_inc – коэффициент увеличения шага настройки; delt_dec – коэффициент уменьшения шага настройки; delta0 – начальное значение шага настройки; deltamax – максимальное значение шага настройки.
Установим следующие значения этих параметров:
net.trainParam.show = 10;
net.trainParam.epochs = 300;
net.trainParam.goal = 1e–5;
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
net = train(net,p,t); % Рис.3.11
На рис. 3.11 приведен график изменения ошибки обучения в зависимости от числа выполненных циклов обучения.
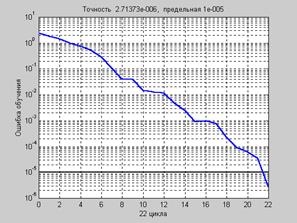 Рис. 3.11
Рис. 3.11
a = sim(net,p)
a = –0.9974 –1.0010 0.9995 0.9984
Нетрудно заметить, что количество циклов обучения по сравнению с алгоритмом GDA сократилось практически еще в 3 раза и составило по отношению к алгоритму GD значение, близкое к 8.5.

