2015-09-06
2015-09-06 2998
2998I. Языковая дивергенция.— II. Роль базисной лексики в датировке языковой дивергенции.— III. Метод Сводеша.— IV. Соотношение между постулатами глоттохронологии и реально наблюдаемой языковой историей.— V. Модификация основной формулы глоттохронологии.— VI. Глоттохронология германских языков.— VII. Этимостатистика.
I. Концепция генеалогического древа предполагает, что родственные языки развиваются из общего языка-предка. Исходя только из структуры дерева, мы можем дать лишь относительную хронологию языковой дивергенции: так, мы можем сказать, что праславянский язык существовал позже прабалтославянского, а последний — позже праиндоевропейского, но не можем сказать, когда существовал каждый из них. Интересно задаться вопросом: существует ли способ измерения абсолютной временн{о/}й глубины языковой дивергенции, иными словами, способ определения времени распада праязыка?
В случаях, когда нам хорошо известна история соответствующей языковой семьи, ответ прост: глубина дивергенции соответствует реально засвидетельствованному времени раздельного существования отдельных языков. Так, в случае с романскими языками мы можем с уверенностью утверждать, что время распада общероманского праязыка (т. е. народной латыни) приблизительно совпадает со временем падения Западной Римской Империи: именно с этого момента диалекты народной латыни, на которых говорили в разных концах этого политического объединения, постепенно начинают превращаться в отдельные языки.
Однако в подавляющем большинстве случаев момент распада праязыка исторически не засвидетельствован. Можно ли по чисто лингвистическим данным определить календарное время дивергенции двух языков, то есть время существования их общего праязыка?
На этот вопрос можно ответить положительно только в том случае, если какие-либо из изменений происходят с более или менее постоянной скоростью: тогда по количеству произошедших изменений можно судить о времени, отделяющем язык от праязыка или два родственных языка друг от друга. Изменения эти должны происходить в одной подсистеме языка, поскольку инновации в разных подсистемах могут быть несопоставимы между собой: например, едва ли можно определить, для чего нужно больше времени — для двух передвижений согласных или для возникновения сингармонизма, для падения редуцированных или для развития эргативности.
II. Но какие из многочисленных языковых изменений могут иметь постоянную скорость? Рассмотрим возможные типы языковых инноваций:
1) изменения в фонетике;
2) изменения в грамматике (в грамматической семантике и синтаксисе);
3) изменения плана содержания слов (т. е. семантические изменения);
4) замена грамматических морфем;
5) лексические замены.
Опираться на фонетические и грамматические изменения сложно из-за их несопоставимости, семантические изменения в настоящее время слишком слабо изучены. Кроме того, известны случаи очень быстрого изменения как фонологических, так и морфологических систем (особенно при активных языковых контактах, см. Гл. 1.4), а также наоборот — чрезвычайного фонологического и морфологического консерватизма, сохранения исходных систем на протяжении очень долгих периодов времени (особенно в случае изолированного существования языка — например, в островных или горных условиях). В то же время изменения в лексике наиболее пригодны для строгих датировок, так как допускают применение статистических методов.
В наиболее простых случаях датировки, полученные при помощи подсчета базисной лексики, хорошо коррелируют с датировками, полученными путем анализа других элементов языка. Для случаев же более сложных желательно пользоваться некоторым единым критерием — с тем, чтобы получать сопоставимые результаты.
Выше (см. Гл. 1.1) мы писали, что основным критерием близости языков — хотя и с многочисленными оговорками — может служить именно лексическая близость. Чтобы сохранялось взаимопонимание между различными поколениями носителей, необходимо, чтобы лексических замен было не слишком много: фонетические и морфологические изменения, как мы видели, мало препятствуют коммуникации, но очень большой процент лексических различий несомненно приведет к утрате взаимопонимания, скажем, между дедами и внуками. При этом меньше всего замен, по-видимому, должно быть в базисной лексике, т. е. в основном словарном составе языка, составляющем его ядро. Кроме того, базисная лексика, в отличие от прочих компонентов языка (т. е. "манеры выражаться" и культурной лексики), мало меняется в ходе языковых контактов, поэтому подсчеты, основанные на ней, позволяют вычислить именно время самостоятельного существования языка, а не степень его вовлеченности в контакты с другими языками.
III. На предположении о постоянной скорости изменений в базисной лексике построил свою теорию глоттохронологии, иногда называемой также лексикостатистикой, американский ученый Морис Сводеш. Эта теория базируется на следующих пяти постулатах (в работах самого М. Сводеша, см. [НВЛ 1960], они не сформулированы, поэтому мы приводим их по книге [Арапов, Херц 1974, 21-22, 25]):
"1. В словаре каждого языка можно выделить специальный фрагмент, который мы будем называть дальше основной, или стабильной частью.
2. Можно указать список значений, которые в любом языке обязательно выражаются словами из основной части... Будем говорить, что эти слова образуют основной список (ОС). Через N{0} обозначим число слов в ОС.
3. Доля p слов из ОС, которые сохранятся (не будут заменены другими словами) на протяжении интервала времени {Dд} t... постоянна (то есть зависит только от величины выбранного промежутка, но не от того, как он выбран или какие слова какого языка рассматриваются).
4. Все слова, составляющие ОС, имеют одинаковые шансы сохраниться (соответственно, не сохраниться, "распасться") на протяжении этого интервала времени.
5. Вероятность для слова из ОС праязыка сохраниться в ОС одного языка-потомка не зависит от его вероятности сохраниться в аналогичном списке другого языка-потомка."
Из совокупности приведенных постулатов выводится основная математическая зависимость глоттохронологии:
N(t)= N{0}e-{l}t
где время, прошедшее от начала момента развития до некоторого последующего момента обозначается как t (и измеряется в тысячелетиях); N{0} есть исходный ОС; {l} есть "скорость выпадения" слов из N{0}; и N(t) есть доля слов исходного ОС, сохранившихся к моменту t. Зная коэффициент {l} и долю слов, сохранившихся в данном языке из списка ОС, мы можем вычислить длину прошедшего промежутка времени:
t= 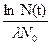
Доля слов из ОС, сохранившихся в двух языках, будет составлять соответственно:
N{2}(t)= 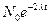 ,
,
а время, разделяющее их, будет вычисляться как:
t= 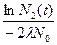
IV. Несмотря на простоту и элегантность данного математического аппарата, уже давно было замечено, что он не очень хорошо работает. Так, К. Бергсланд и Х. Фогт [Bergsland, Vogt 1962], рассматривая материал скандинавских языков, показали, что скорость распадения лексики в исландском языке за последнюю тысячу лет равнялась всего {=~} 0,04, а в литературном норвежском (риксмоле) — {=~} 0,2 (и это при том, что М. Сводеш в качестве константы {l} предлагал величину 0,14!). Соответственно, получались вполне нелепые результаты: для исландского языка около 100-150 лет, а для риксмола — около 1400 лет развития — при том, что оба языка возникли из одного источника и развивались независимо в течение около 1000 лет. В большинстве случаев применение теории Сводеша давало явно "умоложенные" даты по сравнению с теми, которые можно было предположить на основании реальной истории языков. Все это заставило большинство исследователей поставить под сомнение всю глоттохронологическую методику.
Несмотря на это, глоттохронология продолжает существовать. Дело в том, что есть непреложный эмпирический факт, с которым приходится считаться: чем ближе друг к другу языки, тем больше между ними совпадений в области базисной лексики. Так, все индоевропейские языки (из разных подгрупп: немецкий и русский, хинди и польский, болгарский и румынский) имеют между собой около 30% совпадений; все балто-славянские языки (литовский и русский, латышский и чешский) имеют между собой примерно 45-50% совпадений; все славянские языки (русский и польский, чешский и болгарский), а также все германские языки (немецкий и шведский, голландский и исландский) имеют между собой примерно 75-85% совпадений. Налицо, таким образом, явная корреляция между степенью родства и количеством совпадений в базисной лексике. Глоттохронологию, по-видимому, нельзя сбрасывать со счетов, хотя нужен пересмотр некоторых ее постулатов.
V. Здесь следует отметить четыре момента:
1) В случае активных контактов между языками возникают многочисленные заимствования, в том числе и в базисной лексике. Следует, однако, представлять себе, что замена исконного слова на исконное же имеет несколько иной механизм, чем замена исконного слова на заимствование. Замены первого типа происходят постепенно, вне зависимости от культурно-исторического контекста, и только для них можно предполагать некоторую постоянную скорость. Замены второго типа могут происходить в течение краткого времени (при активизации культурных контактов) и, таким образом, как бы нарушают естественный ход развития лексики. Неучет различия этих двух типов замен может привести к серьезным искажениям результатов глоттохронологии. Заметим, что подавляющее большинство "неудачных" результатов глоттохронологических подсчетов, приводивших к искаженным классификациям и неверным датировкам, обусловлено именно неразличением этих двух типов лексических замен. Так, упомянутый выше случай с исландским языком и риксмолом легко объясняется, если учесть, что в исландском вовсе нет заимствований (в силу его изолированного существования), в то время как стословный список риксмола включает в себя 11 датских, 3 шведских и 2 немецких заимствования. Число исконных замен в исландском и норвежском, таким образом, оказывается вполне сопоставимо — однако их не 14%, как это должно было бы быть по Сводешу, а около 5% за последнюю тысячу лет. Аналогичную цифру мы получаем и для других языков, чья история зафиксирована на протяжении нашей эры (японского, китайского, романских и др.).
2) Вероятность для слова из любого списка базисной лексики сохраниться в одном из языков-потомков становится зависимой от того, сохранилось ли оно в другом языке-потомке, при наличии между этими языками-потомками интенсивных контактов (в ту эпоху, когда они были заметно родственными): в активно взаимодействующих заметно родственных языках имеется тенденция к сохранению и/или выпадению из базисной лексики одних и тех же слов (при этом далеко не всегда можно говорить о заимствовании); иногда такие контакты могут вызывать "подскок" доли совпадений даже на 5-6%. Подобную картину мы наблюдаем, например, для белорусского и западнославянских языков, немецкого и скандинавских и пр.
В то же время наличие в языке культивируемой литературной нормы на скорость замены базисной лексики, по-видимому, не влияет: в таких случаях разговорный язык просто отходит от нормы и изменяется сам по себе — такова ситуация во французском, чешском, персидском и многих других языках.
Существенно, однако, что, как показывают многочисленные эксперименты, средняя (по списку) вероятность выпадения слов одинакова для любых языков.
3) Третий постулат глоттохронологии, по-видимому, не вполне верен: доля p слов из ОС, которые сохранятся (не будут заменены другими словами) на протяжении интервала времени {Dд} t не постоянна, но меняется с течением времени. Чем дольше слово "прожило" в языке, тем больше шанс, что оно вскоре выпадет (известны примеры широкого распространения слова в древних языках при почти полной его утрате в современных). Коэффициент {l}, таким образом, должен зависеть от времени t.
Как показывают исследования языков с достаточной длинной письменной историей, скорость распада основного списка равна примерно 0,05 лишь на протяжении последней тысячи — полутора тысяч лет. Если же рассмотреть развитие какого-либо языка в течение, например, 2,5 тысячелетий, то скорость его развития окажется равной {=~} 0,1 (см. [Старостин С. 1989b, 10-13]).
4) С другой стороны, вызывает сомнения и четвертый постулат: все слова, составляющие ОС, имеют одинаковые шансы сохраниться на протяжении интервала времени t. На самом деле среди слов, составляющих ОС, есть более устойчивые слова, сохраняющиеся буквально на протяжении тысяч лет, а есть гораздо менее устойчивая лексика: так, шансов на выпадение из списка у слов `маленький' или `кожа' в целом значительно больше, чем у слов `я', `ты' или `ухо'. Коэффициент сохраняемости индивидуального слова может варьировать в зависимости от культурного и лингвистического окружения (так, слова `облако' и `хвост' весьма устойчивы в тюркских языках и нестабильны в германских).
В силу этих причин наблюдается следующая зависимость: по мере выпадения слов из списка скорость выпадения слов из него — коэффициент {l} — уменьшается, поскольку начинают происходить повторные замены среди менее устойчивой части списка. Таким образом, коэффициент {l} должен зависеть еще и от доли сохранившихся слов N(t).
Эти соображения приводят нас к переформулировке основной зависимости глоттохронологии в следующем виде (обозначим для простоты N(t) как c, а N{0} примем за единицу, поскольку мы имеем дело именно со стословным списком):
c= 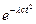
Для двух языков будем иметь:
c= 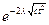
Соответственно, время разделения двух языков будет вычисляться как:
t= 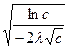
Эта формула, очевидно, является аппроксимацией сложной математической зависимости, учитывающей индивидуальные вероятности выпадения каждого отдельного слова в ОС; она, однако, довольно хорошо работает на всем известном нам языковом материале при принятии {l} = 0,05.
VI. Рассмотрим стословные списки нескольких германских языков:
Таблица 2.1.1
| Слово | Нем. | Англ. | Голл. | Исл. | Норв. (гьестал) | Швед. | Дат. |
| весь | all 1 | all 1 | al(le) 1 | allir 1 | adle 1 | all 1 | al 1 |
| пепел | Asche 2 | ashes 2 | as 2 | aska 2 | {Oc}ska 2 | aska 2 | aske 2 |
| кора | Rinde 3 | bark -1 | bast 4 | b{o:}rkur 5 | b{Oc}rk 5 | bark 5 | bark 5 |
| живот | Bauch 6 | belly 7 | buik 6 | magi 8 | maie 8 | buk 6 | mave 8 |
| живот | kvi{dh=}ur 9 | mage 8 | |||||
| большой | gro{sz} 10 | big 11 | groot 10 | st{o/}r 15 | store 15 | stor 15 | stor 15 |
| большой | mikill 16 | ||||||
| птица | Vogel 17 | bird 18 | vogel 17 | fugl 17 | fogg(e)l 17 | f{ao}gel 17 | fugl 17 |
| кусать | bei{sz}en 19 | bite 19 | bijten 19 | b{i/}ta 19 | bida 19 | bita 19 | bide 19 |
| черный | schwarz 20 | black 21 | zwart 20 | svartur 20 | svarte 20 | svart 20 | sort 20 |
| кровь | Blut 22 | blood 22 | bloed 22 | bl{o/}{dh=} 22 | blo 22 | blod 22 | blod 22 |
| кость | Knochen 23 | bone 24 | been 24 | bein 24 | b{a:}in 24 | ben 24 | ben 24 |
| грудь | Brust 25 | breast 25 | borst 25 | brj{o/}st 25 | br{o:}st 25 | br{o_}st 25 | bryst 25 |
| жечь | brennen 26 | burn 26 | branden 26 | brenna 26 | brenna 26 | br{a:}nna 26 | br{ae}nde 26 |
| ноготь | Nagel 27 | nail 27 | nagel 27 | nagl 27 | negl 27 | nagel 27 | negl 27 |
| облако | Wolke 28 | cloud 155 | wolk 28 | sk{y/} 29 | sjya 29 | sky 29 | sky 29 |
| холодный | kalt 31 | cold 31 | koud 31 | kaldur 31 | kalle 31 | kall 31 | kold 31 |
| приходить | kommen 32 | come 32 | komen 32 | koma 32 | k{Oc}ma 32 | komma 32 | komme 32 |
| умирать | sterben 33 | die -2 | sterven 33 | deyja 34 | d{o:}y 34 | d{o:} 34 | d{o#/} 34 |
| собака | Hund 35 | dog 36 | hond 35 | hundur 35 | honn 35 | hund 35 | hund 35 |
| пить | trinken 37 | drink 37 | drinken 37 | drekka 37 | drikka 37 | dricka 37 | drikke 37 |
| сухой | trocken 38 | dry 38 | droog 38 | {tp}urr 39 | torre 39 | torr 39 | t{o#/}r 39 |
| ухо | Ohr 40 | ear 40 | oor 40 | eyra 40 | {o:}yra 40 | {o:}ra 40 | {o#/}re 40 |
| земля | Erde 41 | earth 41 | aarde 41 | j{o:}r{dh=} 41 | jor 41 | jord 41 | jord 41 |
| земля | mold 42 | m{Oc}ll 42 | |||||
| есть | essen 43 | eat 43 | eten 43 | bor{dh=}a 44 | eda 43 | {a:}ta 43 | spise -1 |
| яйцо | Ei 45 | egg 45 | ei 45 | egg 45 | egg 45 | {a:}gg 45 | {ae}gg 45 |
| глаз | Auge 46 | eye 46 | oog 46 | auga 46 | aua 46 | {o:}ga 46 | {o#/}je 46 |
| жир | Fett -1 | fat 47 | vet 47 | fita 47 | feitt 47 | fett 47 | fedt 47 |
| перо | Feder 48 | feather 48 | veer 48 | fj{o:}{dh=}ur 48 | fj{o:}r 48 | fj{a:}der 48 | fjeder, fjer 48 |
| огонь | Feuer 49 | fire 49 | vuur 49 | eldur 50 | ell 50 | eld 50 | ild 50 |
| рыба | Fisch 51 | fish 51 | vis 51 | fiskur 51 | fisk 51 | fisk 51 | fisk 51 |
| летать | fliegen 52 | fly 52 | vliegen 52 | flj{u/}ga 52 | fjoga 52 | flyga 52 | flyve 52 |
| нога | Fu{sz} 53 | foot 53 | voet 53 | f{o/}tur 53 | fod 53 | fot 53 | fod 53 |
| полный | voll 54 | full 54 | vol 54 | fullur 54 | fodle 54 | full 54 | fuld 54 |
| давать | geben 55 | give 55 | geven 55 | gefa 55 | je 55 | giva 55 | give 55 |
| хороший | gut 56 | good 56 | goed 56 | g{o/}{dh=}ur 56 | goe 56 | god 56 | god 56 |
| зеленый | gr{u:}n 57 | green 57 | groen 57 | gr{a:}nn 57 | gr{o:}ne 57 | gr{o:}n 57 | gr{o#/}n 57 |
| волосы | Haar 58 | hair 58 | haar 58 | h{a/}r 58 | h{Oc}r 58 | h{ao}r 58 | h{ao}r 58 |
| рука | Hand 59 | hand 59 | hand 59 | h{o:}nd 59 | h{Oc}nn 59 | hand 59 | h{ao}nd 59 |
| голова | Kopf -2 | head 60 | hoofd 60 | h{o:}fu{dh=} 60 | h{Oc}ve 60 | huvud 60 | hoved 60 |
| слышать | h{o:}ren 61 | hear 61 | horen 61 | heyra 61 | h{o:}yra 61 | h{o:}ra 61 | h{o#/}re 61 |
| сердце | Herz 62 | heart 62 | hart 62 | hjarta 62 | jerta 62 | hjerta 62 | hjerte 62 |
| рог | Horn 63 | horn 63 | hoorn 63 | horn 63 | h{Oc}dd(e)n 63 | horn 63 | horn 63 |
| я | ich 64 | I 64 | ik 64 | {e/}g 64 | {a:}g 64 | jag 64 | jeg 64 |
| убивать | t{o:}ten 65 | kill 66 | doden 65 | drepa 67 | dreba 67 | dr{a:}pa 67 | dr{ae}be 67 |
| убивать | d{o:}da 65 | ||||||
| колено | Knie 68 | knee 68 | knie 68 | hn{e/} 68 | kne 68 | kn{a:} 68 | kn{ae} 68 |
| знать | kennen 69 | know 69 | kennen 69 | vita 70 | veda 70 | k{a:}nna 69 | kende 69 |
| знать | wissen 70 | weten 70 | veta 70 | vide 70 | |||
| лист | Blatt 71 | leaf 72 | blad 71 | bla{dh=} 71 | bla 71 | blad 71 | blad 71 |
| лист | (laufbla{dh=}) 72 + 71 | l{o:}f 72 | |||||
| лежать | liegen 73 | lie 73 | liggen 73 | liggja 73 | liddja 73 | ligga 73 | ligge 73 |
| печень | Leber 74 | liver 74 | lever 74 | lifur 74 | livr 74 | lever 74 | lever 74 |
| длинный | lang 75 | long 75 | lang 75 | langur 75 | lange 75 | l{ao}ng 75 | lang 75 |
| вошь | Laus 76 | louse 76 | luis 76 | l{u/}s 76 | lus 76 | lus 76 | lus 76 |
| мужчина | Mann 77 | man 77 | man 77 | ma{dh=}ur 77 | mann 77 | man 77 | mand 77 |
| много | viel 78 | many 79 | veel 78 | margur 79 | mye 16 | mycket 16 | meget 16 |
| много | much 16 | miki{dh=} 16 | mange 79 | m{ao}nga 79 | mange 79 | ||
| мясо | Fleisch 80 | meat 81 | vlees 80 | kj{Oc}t 83 | kj{o:}d 83 | k{o:}tt 83 | k{o#/}d 83 |
| луна | Mond 84 | moon 84 | maan 84 | tungl 85 | m{Oc}ne 84 | m{ao}ne 84 | m{ao}ne 84 |
| луна | m{a/}ni 84 | ||||||
| гора | Berg 86 | mountain -3 | berg 86 | fjall 87 | fjedd(e) 87 | berg 86 | bjerg 86 |
| гора | fjeld 87 | ||||||
| рот | Mund 88 | mouth 88 | mond 88 | munnur 88 | monn 88 | mun 88 | mund 88 |
| имя | Name 89 | name 89 | naam 89 | nafn 89 | nabbn 89 | namn 89 | navn 89 |
| шея | Hals 90 | neck 91 | hals 90 | h{a/}ls 90 | hals 90 | hals 90 | hals 90 |
| шея | nek 91 | ||||||
| новый | neu 92 | new 92 | nieuw 92 | n{y/}r 92 | nye 92 | ny 92 | ny 92 |
| ночь | Nacht 93 | night 93 | nacht 93 | n{o/}tt 93 | n{Oc}tt 93 | natt 93 | nat 93 |
| нос | Nase 94 | nose 94 | neus 94 | nef 95 | nase 94 | n{a:}sa, nos 94 | n{ae}se 94 |
| не | nicht 96 | not 96 | niet 96 | ekki 97 | ikke 97 | icke, ej 97 | ikke 97 |
| один | ein 98 | one 98 | een 98 | einn 98 | enn 98 | en 98 | en 98 |
| человек | Mensch 77 | man 77 | mens, man 77 | ma{dh=}ur, manneskja 77 | mennesje 77 | menniska 77 | menneske 77 |
| дождь | Regen 99 | rain 99 | regen 99 | rigna 99 | regne 99 | regn 99 | regn 99 |
| красный | rot 100 | red 100 | rood 100 | rau{dh=}ur 100 | raue 100 | r{o:}d 100 | r{o#/}d 100 |
| дорога | Weg 101 | road 102 | weg 101 | vegur 101 | veg 101 | v{a:}g 101 | vei 101 |
| дорога | way 101 | ||||||
| корень | Wurzel 103 | root 103 | wortel 103 | r{o/}t 103 | rod 103 | rot 103 | rod 103 |
| круглый | rund -3 | round -4 | rond -1 | kringl{o/}ttur 104 | ronne -1 | rund -1 | rund -1 |
| песок | Sand 105 | sand 105 | zan 105 | sandur 105 | sand 105 | sand 105 | sand 105 |
| сказать | sagen 106 | say 106 | zeggen 106 | segja 106 | seia 106 | s{a:}ga 106 | sige 106 |
| видеть | sehen 107 | see 107 | zien 107 | sj{a/} 107 | sj{Oc} 107 | se 107 | se 107 |
| семя | Same 108 | seed 108 | zaa 108 | fr{a:} 109 | fr{a:} 109 | fr{o:} 109 | fr{o#/} 109 |
| сидеть | sitzen 110 | sit 110 | zitten 110 | sitja 110 | sidja 110 | sitta 110 | sidde 110 |
| кожа | Haut 111 | skin -5 | huid 111 | h{u/}{dh=} 111 | sjinn 168 | hud 111 | hud 111 |
| кожа | vel 112 | skinn 168 | skinn 168 | ||||
| спать | schlafen 113 | sleep 113 | slapen 113 | sofa 114 | s{Oc}va 114 | sova 114 | sove 114 |
| маленький | klein 115 | small 116 | klein 115 | l{i/}till 117 | lid(e)n 117 | liten 117 | lille, liden 117 |
| маленький | little 117 | sm{a/}r 116 | sm{ao} 116 | ||||
| дым | Rauch 118 | smoke 169 | rook 118 | reykur 118 | r{o:}yg 118 | r{o:}k 118 | r{o#/}g 118 |
| стоять | stehen 119 | stand 119 | staan 119 | standa 119 | st{Oc} 119 | st{ao} 119 | st{ao} 119 |
| звезда | Stern 120 | star 120 | ster 120 | stjarna 120 | sj{o:}dna 120 | stjern(a) 120 | stjerne 120 |
| камень | Stein 121 | stone 121 | steen 121 | steinn 121 | steid(e)n 121 | sten 121 | sten 121 |
| солнце | Sonne 122 | sun 122 | zon 122 | s{o/}l 122 | sol 122 | sol 122 | sol 122 |
| плавать | schwimmen 123 | swim 123 | zwemmen 123 | synda 124 | s{o:}mja 123 | simma 123 | sv{o#/}mme 123 |
| хвост | Schwanz 125 | tail 126 | staart 127 | hali 128 | hale 128 | stjert 127 | hale 128 |
| хвост | skott 129 | ||||||
| тот | jener 130 | that 131 | die 131 | {tp}essi 131 | denn, d{a:} 131 | den 131 | den 131 |
| тот | s{a/} 170 | hin,hint 172 | |||||
| этот | dieser 131 | this 131 | deze 131 | {tp}essi 131 | dette 131 | detta 131 | dette 131 |
| ты | du 132 | you 133 | jij, je 133 | {tp}{u/} 132 | du 132 | du 132 | du 132 |
| язык | Zunge 134 | tongue 134 | tong 134 | tunga 134 | tonga 134 | tunga 134 | tunge 134 |
| зуб | Zahn 135 | tooth 135 | tand 135 | t{o:}nn 135 | t{Oc}nn 135 | tand 135 | tand 135 |
| дерево | Baum 136 | tree 137 | boom 136 | tr{e/} 137 | tre 137 | tr{a:}d 137 | tr{ae} 137 |
| два | zwei 138 | two 138 | twee 138 | tveir 138 | to 138 | tv{ao} 138 | to 138 |
| идти | gehen 139 | go 139 | gaan 139 | fara 250 | g{Oc} 139 | g{ao} 139 | g{ao} 139 |
| теплый | warm 140 | warm 140 | warm 140 | hl{y/}r 141 | varme 140 | varm 140 | varm 140 |
| вода | Wasser 142 | water 142 | water 142 | vatn 142 | vatt(e)n 142 | vatten 142 | vand 142 |
| мы | wir 143 | we 143 | wij 143 | vi{dh=} 143 | me 211 | vi 143 | vi 143 |
| что | was 144 | what 144 | wat 144 | hva{dh=} 144 | ka 144 | hvad 144 | hvad 144 |
| белый | wei{sz} 145 | white 145 | wit 145 | hv{i/}tur 145 | kvide 145 | hvit 145 | hvid 145 |
| кто | wer 144 | who 144 | wie 144 | hver 144 | kenn 144 | hvem 144 | hvem 144 |
| женщина | Frau 146 | woman 147+77 | vrouw 146 | kona 148 | kvinn 148 | qvinna 148 | kvinde 148 |
| женщина | Weib 147 | ||||||
| желтый | gelb 149 | yellow 149 | geel 149 | gulur 149 | gule 149 | gul 149 | gul 149 |
В приведенной таблице все корни пронумерованы в соответствии с их этимологиями. Выбирается по возможности основное слово для данного значения в данном языке; однако разрешается учитывать и близкие синонимы, если они имеются и оба являются употребительными (случаи типа little и small для значения `маленький' в английском и т. п.). Особо нужно оговорить заимствованную лексику: заимствованные слова помечены в таблице отрицательными номерами (при этом их этимологические связи не отмечаются), и они не учитываются при подсчете совпадений, то есть, например, пара нем. wir — англ. we засчитывается как совпадение, пара нем. Vogel — англ. bird — как несовпадение, а пара нем. Haut — англ. skin вовсе не учитывается, то есть основной список в данном случае как бы уменьшается на единицу (точно так же мы поступаем и в тех случаях, когда соответствующее слово в языке просто неизвестно — к сожалению, довольно частая ситуация со списками малоизученных и древних языков). Особенно сложна ситуация с отделением заимствованной лексики от исконной в английском языке, поэтому оговорим специально, что разметка английского списка произведена в соответствии со словарем [Skeat 1968]. В качестве представителя "норвежского" языка выбран диалект гьестал, поскольку оба литературных норвежских языка - букмол и нюнорск - изобилуют заимствованиями, причем для многих слов отнесение их к числу исконных или заимствованных спорно.
Подсчет этимологических совпадений (отметим еще раз, что "этимологическими совпадениями" считаются слова, имеющие один и тот же корень, морфологические различия не учитываются) дает нам следующий результат:
Таблица 2.1.2
| Язык | Нем. | Англ. | Голл. | Исл. | Норв. | Швед. | Дат. |
| Нем. | - | 0.82 | 0.95 | 0.74 | 0.77 | 0.82 | 0.80 |
| Англ. | 1.49 | - | 0.85 | 0.75 | 0.78 | 0.81 | 0.80 |
| Голл. | 0.74 | 1.31 | - | 0.76 | 0.79 | 0.85 | 0.82 |
| Исл. | 1.86 | 1.84 | 1.79 | - | 0.94 | 0.93 | 0.96 |
| Норв. | 1.71 | 1.68 | 1.64 | 0.80 | - | 0.97 | 0.98 |
| Швед. | 1.46 | 1.53 | 1.34 | 0.87 | 0.56 | - | 0.99 |
| Дат. | 1.57 | 1.59 | 1.50 | 0.65 | 0.46 | 0.32 | - |
В этой таблице верхний треугольник содержит доли совпадений между каждой парой языков, а нижний — вычисленные по этим долям времена расхождения (в тысячелетиях). Так, между английским и немецким 82% совпадений, что соответствует глубине дивергенции приблизительно в 1500 лет. Минимальный процент совпадений здесь — 74% между исландским и немецким, что соответствует времени дивергенции примерно 1800-1900 лет. Легко убедиться, что приведенные доли совпадений и датировки в целом вполне соотносятся с обычными представлениями о глубине германской семьи языков и ее классификации (ниже, см. Гл. 2.2, мы еще поговорим о классификационном аспекте лексикостатистики).
Необходимо особо оговорить то, как при данной глоттохронологической методике следует обращаться с материалом древних языков. Используемый метод исходит из того, что скорость распада основного списка фактически не является постоянной величиной, а зависит от времени, отделяющего язык от праязыка. Следовательно, один и тот же процент совпадений, полученный для двух пар родственных языков, из которых одну пару составляют два современных языка, а вторую – два древних, зафиксированных, скажем, в V веке н. э., будет соответствовать различным периодам дивергенции. Чтобы вычислить соответствующую датировку, необходимо использовать метод табличной коррекции (см. Табл. 2.1.3; c — доля сохранившейся лексики в одном языке, c{2} — доля сохранившейся лексики в двух языках, t — время в тысячелетиях):
Таблица 2.1.3
| c | c{2} | t |
| 0,99 | 0,99 | 0,3 |
| 0,97 | 0,94 | 0,8 |
| 0,95 | 0,9 | |
| 0,9 | 0,81 | 1,5 |
| 0,85 | 0,72 | |
| 0,8 | 0,64 | 2,4 |
| 0,75 | 0,56 | 2,8 |
| 0,7 | 0,49 | 3,2 |
| 0,65 | 0,42 | 3,7 |
| 0,6 | 0,36 | 4,1 |
| 0,55 | 0,3 | 4,7 |
| 0,5 | 0,25 | 5,3 |
и т. д.
Предположим, что мы сравниваем списки двух языков, один из которых (A) засвидетельствован в V в. н. э., а другой (B) — в XII, и получаем 80% совпадений. Поскольку язык A отделен от нашего времени периодом в 1,5 тысяч лет, а язык B — периодом в 0,8 тысяч лет, их современные потомки имели бы 0,8*0,9*0,97 = 0,7, то есть 70% совпадений, что соответствует дивергенции приблизительно в 1900 лет.
После этих предварительных замечаний рассмотрим данные древних германских языков — древнеанглийского, древневерхненемецкого, древнеисландского и готского.
Таблица 2.1.4
| Слово | Готский | Др.-исл. | Др.-англ. | Д.-в.-н. |
| весь | alls 1 | allr 1 | eall 1 | all 1 |
| пепел | azgo 2 | aska 2 | {ae}sce 2 | asca, asga 2 |
| кора | — | b{Oc}rkr 5 | rinde 3 | rinta 3 |
| живот | wamba 13 | magi 8 | wamb 13 | wamba 13 |
| живот | v{Oc}mb 13 | href 14 | ||
| большой | mikils 16 | st{o/}rr 15 | micel, mycel 16 | mihhil 16 |
| большой | mikill 16 | {3Z}r{e_}at 10 | ||
| птица | fugls 17 | fugl 17 | fu{3Z}ol 17 | fogal 17 |
| кусать | beitan 19 | b{i/}ta 19 | b{i_}tan 19 | b{i_}zzan 19 |
| черный | swarts 20 | svartr 20 | bl{ae}c 21 | swarz 20 |
| черный | bl{a/}r 21 | sweart 21 | ||
| кровь | blo{tp} 22 | bl{o/}{dh=} 22 | bl{o_}d 22 | bluot 22 |
| кость | — | bein 24 | b{a_}n 24 | bein 24 |
| грудь | brusts 25 | brj{o/}st 25 | br{e_}ost 25 | brust 25 |
| жечь | brinnan 26 | brenna 26 | byrnan 26 | brennen 26 |
| ноготь | — | nagl 27 | n{ae}{3Z}el 27 | nagal 27 |
| облако | milhma 150 | sk{y/} 29 | wolcen 28 | wolcan 28 |
| холодный | kalds 31 | kaldr 31 | ceald 31 | kalt 31 |
| приходить | qiman 32 | koma 32 | cuman 32 | queman 32 |
| умирать | swiltan 151 | deyja 34 | steorfan 33 | sterban 33 |
| умирать | divan 34 | svelta 151 | sweltan 151 | touen 34 |
| собака | hunds 35 | hundr 35 | hund 35 | hund 35 |
| пить | trigkan 37 | drekka 37 | drincan 37 | trinkan 37 |
| сухой | {tp}airs- 39 | {tp}urr 39 | dry{3Z}e 38 | trokkan 38 |
| ухо | auso 40 | eyra 40 | {e_}are 40 | {o_}ra 40 |
| земля | a{i/}r{tp}a 41 | mold 42 | eor{dh=}e 41 | erda 41 |
| земля | j{Oc}r{dh=} 41 | |||
| есть | itan 43 | eta 43 | etan 43 | e{z}{z}an 43 |
| есть | matjan 153 | |||
| яйцо | — | egg 45 | {ae}{3Z} 45 | ei 45 |
| глаз | augo 46 | auga 46 | {e_}a{3Z}e 46 | ouga 46 |
| жир | sma{i/}r{tp}r 154 | fita 47 | f{ae}t 47 | feizzit 47 |
| перо | — | fj{Oc}{dh=}r 48 | fe{dh=}er 48 | federa 48 |
| огонь | fon, funa 49 | eldr 50 | f{y_}r 49 | fuir, fiur 49 |
| рыба | fisks 51 | fiskr 51 | fisc 51 | fisc 51 |
| летать | — | flj{u/}ga 52 | fl{e_}o{3Z}an 52 | fliogan 52 |
| нога | fotus 53 | f{o/}tr 53 | f{o_}t 53 | fuo{z} 53 |
| полный | fulls 54 | fullr 54 | ful(l) 54 | fol 54 |
| давать | giban 55 | gefa 55 | {3Z}iefan 55 | geban 55 |
| хороший | gods 56 | g{o/}{dh=}r 56 | {3Z}{o_}d 56 | guot 56 |
| зеленый | - | groen 57 | {3Z}r{e_}ne 57 | gruoni 57 |
| волосы | tagl 126 | h{a/}r 58 | h{e_}r 58 | h{a_}r 58 |
| рука | handus 59 | h{Oc}nd 59 | hand 59 | hand 59 |
| голова | haubi{tp} 60 | h{Oc}fu{dh=} 60 | heafod 60 | houbit 60 |
| слышать | hausjan 61 | heyra 61 | h{i_}eran 61 | h{o_}ren 61 |
| сердце | ha{i/}rto 62 | hjarta 62 | heorte 62 | herza 62 |
| рог | haurn 63 | horn 63 | horn 63 | horn 63 |
| я | ik 64 | ek 64 | ic 64 | ih 64 |
| убивать | dau{tp}jan 65 | drepa 67 | cwellan 66 | t{o_}den 65 |
| колено | kniu 68 | kn{e/} 68 | cn{e_}o(w) 68 | knio 68 |
| знать | kunnan 69 | kenna, kunna 69 | cn{a_}wan 69 | kennen 69 |
| знать | witan 70 | vita 70 | witan 70 | wi{z}{z}an 70 |
| лист | laufs 72 | lauf 72 | l{e_}af 72 | blat 71 |
| лист | loub 72 | |||
| лежать | ligan 73 | liggja 73 | lic{3Z}an 73 | liggen 73 |
| печень | — | lifr 74 | lifer 74 | lebara 74 |
| длинный | laggs 75 | langr 75 | lan{3Z} 75 | lang 75 |
| вошь | — | l{u/}s 76 | l{u_}s 76 | lus 76 |
| мужчина | manna 77 | verr 156 | wer 156 | man 77 |
| мужчина | wair 156 | man(n)77 | wer 156 | |
| много | filu 78 | margr 79 | fe(a)la 78 | filu 78 |
| много | manags 79 | m{ae}ni{3Z} 79 | manag 79 | |
| мясо | leik 157 | kj{Oc}t 83 | fl{ae_}sc 80 | fleisk 80 |
| мясо | mimz 158 | |||
| луна | mena 84 | m{a/}ni 84 | m{o_}na 84 | m{a_}no 84 |
| луна | tungl 85 | |||
| гора | fairguni 159 | fjall 87 | beor{3Z} 86 | berg 86 |
| рот | mun{tp}s 88 | munnr 88 | m{u_}{dh=} 88 | mund 88 |
| имя | namo 89 | nafn 89 | nama 89 | namo 89 |
| шея | hals 90 | hals 90 | heals 90 | hals 90 |
| шея | sw{e_}ora 161 | |||
| новый | niujis 92 | n{y/}r 92 | neowe 92 | niuwi 92 |
| ночь | nahts 93 | n{o/}tt 93 | niht 93 | naht 93 |
| нос | — | nasar 94 | n{o_}su 94 | nasa 94 |
| не | ni, niu 96 | eigi, ekki 97 | n{e_} 96 | ni, ne 96 |
| один | ains 98 | einn 98 | {a_}n 98 | ein 98 |
| человек | manna 77 | ma{dh=}r 77 | man(n) 77 | mennisco 77 |
| человек | guma 162 | gumi 162 | {3Z}uma 162 | gomo 162 |
| дождь | rign 99 | regn 99 | re{3Z}n 99 | regan 99 |
| красный | rauds 100 | rau{dh=}r 100 | r{e_}ad 100 | r{o_}t 100 |
| дорога | wigs 101 | vegr 101 | we{3Z} 101 | weg 101 |
| дорога | staiga 163 | stigr 163 | st{i_}{3Z} 163 | |
| корень | waurds 103 | r{o/}t 103 | wyrt 103 | wurz 103 |
| круглый | — | kringl{o/}ttr 104 | — | sinw{e_}l 165 |
| песок | malma 166 | sandr 105 | sand 105 | sant 105 |
| сказать | qi{tp}an 167 | segja 106 | sec{3Z}an 106 | sag{e_}n 106 |
| сказать | kve{dh=}a 167 | cwe{dh=}a 167 | ||
| видеть | saihwan 107 | sj{a/} 107 | s{e_}on 107 | sehan 107 |
| семя | fraiw 109 | frj{o/} 109 | s{ae_}d 108 | s{a_}mo 108 |
| сидеть | sitan 110 | sitja 110 | sittan 110 | sizzen 110 |
| кожа | — | h{u/}{dh=} 111 | h{y_}d 111 | h{u_}t 111 |
| кожа | skinn 168 | |||
| спать | slepan 113 | sofa 114 | sl{ae_}pan 113 | sl{a_}ffan 113 |
| маленький | leitils 117 | l{i/}till 117 | l{y_}tel 117 | luzzil 117 |
| маленький | smals 116 | sm{a/}r 116 | sm{ae}l 116 | |
| дым | — | reykr 118 | r{e_}c 118 | rouh 118 |
| дым | smoca 169 | |||
| стоять | standan 119 | standa 119 | standan 119 | stantan, st{a_}n 119 |
| звезда | sta{i/}rno 120 | stjarna 120 | steorra 120 | stern 120 |
| камень | stains 121 | steinn 121 | st{a_}n 121 | stein 121 |
| солнце | sunna, sauil 122 | s{o/}l, sunna 122 | sunne 122 | sunna 122 |
| плавать | — | svimma 123 | swimman 123 | swimman 123 |
| хвост | — | hali 128 | t{ae}{3Z}(e)l 126 | zagel 126 |
| тот | jains 130 | sa 170 | se, s{e_} 170 | jen{e_}r 130 |
| тот | {tp}at 131 | |||
| этот | sa 170 | {tp}essi, {tp}etta 131 | {tp}es 131 | deser 131 |
| этот | {tp}iz- 131 | |||
| ты | {tp}u 132 | {tp}{u/} 132 | {tp}{u_} 132 | {tp}{u_} 132 |
| язык | tuggo 134 | tunga 134 | tun{3Z}e 134 | zunga 134 |
| зуб | tun{tp}us 135 | t{Oc}nn 135 | t{o_}{dh=} 135 | zan(d) 135 |
| дерево | triu 137 | tr{e/} 137 | tr{e_}o(w) 137 | boum 136 |
| дерево | bagms 136 | |||
| два | twai 138 | tveir 138 | tw{e_}{3Z}en 138 | zw{e_}ne 138 |
| идти | gaggan 139 | ganga 139 | {3Z}{a_}n 139 | gangan, g{e_}n 139 |
| теплый | warm- 140 | varmr 140 | wearm 140 | warm 140 |
| вода | vato 142 | vatn 142 | w{ae}ter 142 | wa{z}{z}ar 142 |
| вода | ahwa 171 | |||
| мы | weis 143 | v{e/}r 143 | w{e_} 143 | wir 143 |
| что | hwa 144 | hvat 144 | hw{ae}t 144 | hwa{z} 144 |
| белый | hweits 145 | hv{i/}tr 145 | hw{i_}t 145 | hw{i_}{z} 145 |
| кто | hwas 144 | hverr 144 | hw{a_} 144 | hwe 144 |
| женщина | qens 148 | kona 148 | cw{e_}n 148 | w{i_}b 147 |
| женщина | w{i_}f 147 | |||
| желтый | — | gulr 149 | {3Z}eolo 149 | gelo 148 |
Прочерк в таблице означает, что в письменных памятниках данного языка соответствующее слово не зафиксировано. С дефисом приведены корни, сохранившиеся только в производных словах.
Теперь приведем сводную таблицу долей совпадений и датировок по всем германским языкам:
Таблица 2.1.5
| Язык | Нем. | Англ. | Голл. | Исл. | Норв. | Швед. | Дат. | Гот. | Др.-исл. | Др.-англ. | Д.-в.-н. |
| Нем. | - | 0.82 | 0.95 | 0.74 | 0.77 | 0.82 | 0.80 | 0.83 | 0.78 | 0.91 | 0.95 |
| Англ. | 1.49 | - | 0.85 | 0.75 | 0.78 | 0.81 | 0.80 | 0.78 | 0.82 | 0.92 | 0.86 |
| Голл. | 0.74 | 1.31 | - | 0.76 | 0.79 | 0.85 | 0.82 | 0.80 | 0.80 | 0.89 | 0.92 |
| Исл. | 1.86 | 1.84 | 1.79 | - | 0.94 | 0.93 | 0.96 | 0.81 | 0.95 | 0.81 | 0.78 |
| Норв. | 1.71 | 1.68 | 1.64 | 0.80 | - | 0.97 | 0.98 | 0.81 | 0.98 | 0.81 | 0.82 |
| Швед. | 1.46 | 1.53 | 1.34 | 0.87 | 0.56 | - | 0.99 | 0.85 | 0.98 | 0.85 | 0.86 |
| Дат. | 1.57 | 1.59 | 1.50 | 0.65 | 0.46 | 0.32 | - | 0.82 | 0.99 | 0.84 | 0.85 |
| Гот. | 1.86 | 2.08 | 2.00 | 1.95 | 1.95 | 1.80 | 1.91 | - | 0.87 | 0.87 | 0.86 |
| Др.-исл. | 1.83 | 1.66 | 1.77 | 1.02 | 0.84 | 0.84 | 0.77 | 1.87 | - | 0.89 | 0.83 |
| Др.-англ. | 1.32 | 1.28 | 1.41 | 1.78 | 1.78 | 1.6 | 1.65 | 1.92 | 1.60 | - | 0.94 |
| Д.-в.-н. | 1.05 | 1.48 | 1.21 | 1.87 | 1.69 | 1.51 | 1.56 | 1.93 | 1.82 | 1.39 | - |
Ниже (Гл. 2.2) мы увидим, как полученную матрицу можно преобразовать в генеалогическое древо; а пока заметим, что полученные датировки в целом довольно хорошо совпадают с историческими данными. Отделение готского языка приходится на I‑II вв. до н. э.; отделение западногерманских языков от скандинавских — на начало н. э.; отделение англосаксонской ветви — на IV‑V вв. н. э.; разделение скандинавских языков датируется X‑XI в. н. э.; разделение верхне- и нижненемецкого — примерно VIII в. н. э.
Разумеется, получаемые датировки довольно приблизительны, и каждая отдельная пара языков может показывать довольно существенные отклонения (в пределах статистической погрешности). Тем не менее, во всех известных нам случаях (а аналогичные подсчеты проводились на материале очень многих языковых семей) результаты получаются правдоподобными, и можно сказать, что в целом глоттохронологическая методика вполне пригодна для использования.
Отметим специально, что эти даты соответствуют не тому времени, когда потомки праязыка уже стали разными языками, а моменту разделения носителей праязыка на две общности, относительно обособленные друг от друга, — именно с этого момента между идиомами-потомками праязыка (в то время еще даже не диалектами, а в лучшем случае говорами) начинают накапливаться независимые различия. Для того, чтобы в стословнике заменилось хотя бы одно слово, два идиома должны развиваться отдельно друг от друга в течение примерно 300 лет. Сами же идиомы при этом, естественно, будут являться диалектами одного и того же языка. Таким образом, время расхождения языков, вычисляемое по методу глоттохронологии, всегда будет более ранним, чем время, начиная с которого можно наблюдать заметные различия между разошедшимися языками.
VII. Еще один способ определения временн{о/}й глубины дивергенции языков — так называемая этимологическая статистика (этимостатистика) или корневая глоттохронология. Эта методика (разработанная одним из авторов данного курса — С.А. Старостиным, см. [Старостин С. 1989b]) исходит из того принципа, что корни, как и слова, имеют определенный срок жизни в языке и некоторую стабильную скорость выпадения, а также из того, что в любом тексте мы можем встретить фиксированное число наиболее частотных в данный момент времени корней. Выделив такие списки корней (а их в принципе может быть произвольное количество, поскольку объем текстов не ограничен), мы можем посчитать процент этимологических совпадений с ними в другом родственном языке и таким образом также измерить расстояние между сравниваемыми языками. Данная методика имеет как свои плюсы, так и свои минусы:
1) С одной стороны, мы не ограничены каким-то заранее заданным списком значений и не должны выбирать "основное" слово, выражающее данное значение в данном языке. Совпадение между нем. Hund `собака' и англ. hound (`охотничий пес') будет достаточным для того, чтобы установить факт тождества: главное в этимостатистической методике — это чтобы корень сохранялся в обоих сравниваемых языках, и требование полного совпадения значений не является обязательным.
Это чрезвычайно существенное достоинство, поскольку если для некоторого значения в языке существует несколько синонимов, то различия в выборе представителя данного значения в стословном списке могут привести к разным датировкам.
Кроме того, этимостатистический анализ позволяет повысить надежность выводов, давая возможность получить для каждой пары сравниваемых языков серию результатов (для которых можно вычислить математическое ожидание и возможные пределы отклонений) любой длины, поскольку количество текстов в принципе неограничено.
Еще одно важное достоинство этимостатистического метода состоит в том, что он позволяет получить более надежные, чем глоттохронология, результаты при датировке распада праязыков макросемей: отдаленно-родственные языки насчитывают лишь 5-10% совпадений по стословнику (что близко к статистической погрешности), доля же совпадающих корней значительно выше — около 15-20%.
2) С другой стороны, для применения этимостатистики требуется хорошо разработанная сравнительная фонетика и этимология сравниваемых языков; необходимым является наличие хороших этимологических словарей. Поэтому для мало изученных и неполно описанных языков данная методика фактически неприменима — в отличие от классической глоттохронологии, для которой достаточно гораздо меньшей степени изученности.
Отметим, впрочем, что изложенная выше методика глоттохронологии также предполагает предварительное установление соответствий между языками — хотя бы для того,