 2015-10-13
2015-10-13 1105
1105Не получилось? Прождал полтора часа, а бряк так и не наступил? Ну значит где то у тебя косяк, зациклило прогу. Жми паузу и смотри где переклинило процессор. Можешь пошагово потрейсить и посмотреть в каком именно месте оно крутится. А дальше уже думать. Отработка больших циклов, может быть очень длительной. Например, задержка длительностью в двадцать секунд, эмулируется в Студии порядка пяти минут!!! (на моем древнем Athlon 950) так что если у тебя где то тупит, то не помешает глянуть на показания StopWatch - может на самом деле все еще нормально, просто подождать надо. Чтобы не тупить на таких циклах я их на время отладки закомменчиваю или меняю предделитель таймера с 1024, на 1. На логику же это не влияет, так что можно проскочить их по быстрому.
Бряки бывают разные. Добавляются Брейкпоинты из меню Debug -> New Breakpoint их там два вида. Programm Breakpoint - это тупо точки останова на конкретном месте. Их проще расставлять не отсюда, а прям в коде на нужной строке. А вот ;Data Breakpoint это уже куда интересней. Погляди на выпадающий список - есть где развернуться. Тут тебе и совпадение битов, и равенство нужному числу, и просто обращение к адресу/регистру/памяти. Причем можно указывать сразу битовую маску. А в разделе Location выбрать любой байт памяти или регистр конфигурации. Мало того, в настройках брейка можно выбрать после скольких событий должен сработать этот бряк. Например, ты поставил брейк на начало цикла, нужно тебе поглядеть что происходит на какой-нибудь 140 итерации. Не будешь же ты тыкать пока оно там все 140 раз не прокрутится. Ставим в свойствах бряка число хитов которые он должен пропустить - 140 и на 140 итерации он тормознет программу. Удобно, черт возьми!
Все брейкпоинты видны в окне Breakpoint and tracepoint. Которое возникает внизу, там же где и сообщения об ошибках, в виде закладки. Оттуда им можно менять свойства, там же можно вывести отображение числа хитов и другие свойства бряка.
Работа с портами, эмуляция кнопок и прочего внешнего оборудования.
Есть в отладке AVR Studio одно небольшое западло, точнее особенность. Когда ты устанавливаешь порт на вход, делая подтяжку на резистор:
DDR= 0
PORT=1
То вывод виртуального МК остается равен нулю!!! Таким образом, все кнопки в отладчике AVR Studio по дефолту оказываются нажатыми! Нужно вручную выставить значение PIN, протыкав соответствующие галочки. Неудобно, но так.
А еще можно заказать вывод лога из порта или заливку туда данных извне! Вот это ваще мега фича. Во время отладки, в меню Debug->Simulation Options в разделе Stimuli&Loggin можно выбрать на какой порт, повесить либо логгер, либо же загнать дамп нужных циферок. Входные данные задаются в файле *.sti в формате такого вида [номер таката]:[значение] примерно так:
000000006:01
000000010:02
000000014:03
000000018:04
000000022:05
000000026:06
000000030:07
Можно задавать его вручную, можно написать программу в той же студии, которая тебе его сгенерит:)))) А можно применить одну зашибенную программку stimuligenerator_net20, которую написал широко известный в узких кругах товарищь ARV обитающий на сайте arv.radioliga.com Кстати, рекомендую к посещению, достойный ресурс.
Программка проста как мычание - выставляешь нужные биты по времени, не забыв указать частоту принимающего МК (чтобы такты выставило правильно). Опа и никаких забот:) Для работы программка правда требует.NET окружение, поэтому вначале придется скачать 30МБ.Net Frame Work если ты его себе еще не поставил.
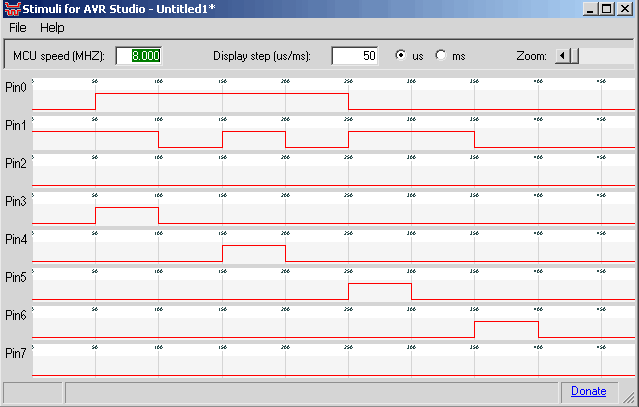 |
Выходящий лог можно наблюдать в Студии в окне Message (вкладка рядом с сообщениями об ошибках компиляции) и потом поглядеть в файле. Формат там такой же (номер такта:значение порта). Такты идут по порядку при старте процессора, с нуля. Его же можно также открыть stimuligenerator‘ом. Короче, программа Must Have.
Работа с прерываниями
Ну тут все просто, хочешь прерывание - ткни вручную бит ее флага, мол вот оно, и прерывание начнется. Особенно это актуально для всяких внешних источников. Вроде UART или INT. После ручного вызова, например, RX прерывания не грех будет взять и вбить ручками в нужный регистр якобы принятое значение. Опа и словно так и было:)))))
Перед изучением системы команд микроконтроллера надо бы разобраться в инструментарии. Плох тот плотник который не знает свой топор. Основным инструментом у нас будет компилятор. У компилятора есть свой язык — макроассемблер, с помощью которого жизнь программиста упрощается в разы. Ведь гораздо проще писать и оперировать в голове командами типа MOV Counter,Default_Count вместо MOV R17,R16 и помнить что у нас R17 значит Counter, а R16 это Default_Count. Все подстановки с человеческого языка на машинный, а также многое другое делается средствами препроцессора компилятора. Его мы сейчас и рассмотрим.
Комментарии в тексте программы начинаются либо знаком “; “, либо двойными слешами “ // “, а еще AVR Studio поддерживает Cишную нотацию комментариев, где коменты ограничены “колючей проволокой” /* коммент */.
Оператор.include позволяет подключать в тело твоей программы кусок кода из другого текстового файла. Что позволяет разбить большую исходник на кучу мелких, чтобы не загромождать и не мотать туда сюда огромную портянку кода. Считай куда ты воткнул .include туда и вставился кусок кода из другого файла. Если надо подключать не весь файл, а только его часть, то тебе поможет директива .exit дойдя до которой компилятор выйдет из файла.
Оператор.def позволяет привязать к любому слову любое значение из ресурсов контроллера — порт или регистр. Например сделал я счетчик, а считаемое значение находится в регистре R0, а в качестве регистра-помойки для промежуточных данных я заюзал R16. Чтобы не запутаться и помнить, что в каком регистре у меня задумано я присваиваю им через .def символические имена.
| 12 | .def schetchik = R0.def pomoika = R16 |
И теперь в коде могу смело использовать вместо официального имени R0 неофицальную кличку schetchik
Одному и тому же регистру можно давать кучу имен одновременно и на все он будет честно откликаться.
Также есть оператор .undef после которого компилятор напрочь забывает, что данной переменной что либо соответствовало. Иногда бывает удобно. Когда одно и то же символическое имя хочется присвоить разным ресурсам.
| 1 | .undef pomoika |
Оператор.equ это присвоение выражения или константы какой либо символической метке.
Например, у меня есть константа которая часто используется. Можно, конечно, каждый раз писать ее в коде, но вдруг окажется, что константа выбрана неверно, а значит придется весь код шерстить и везде править, а если где-нибудь забудешь, то получишь такую махровую багу, что задолбаешься потом ее вылавливать. Так что нафиг, все константы писать надо через
.equ! Кроме того, можно же присвоить не константу, а целое выражение. Которое при компиляции посчитается препроцессором, а в код пойдет уже исходное значение. Надо только учитывать, что деление тут исключительно целочисленное. С отбрасыванием дробной части, без какого-либо округления, а значит 1/2 = 0, а 5/2 = 2
| 123 | .equ Time = 5.equ Acсelerate = 4.equ Half_Speed = (Accelerate*Time)/2 |
Директивы сегментации. Как я уже рассказывал в посте про архитектуру контроллера AVR память контроллера разбита на независимые сегменты - данные (ОЗУ), код (FLASH), EEPROM
Чтобы указать компилятору, что где находится применяют директивы сегментации и адресации.
.CSEG сегмент кода, он же флеш. После этой директивы идет тело программы, комманды процессора. Тут же можно засунуть какие нибудь данные которые не меняются, например таблицу с заранее посчитаными значениями, статичный текст или таблицу символов для знакогенератора.
В сегменте кода уместны директивы:
Адресная метка. Любое слово, не содержащее пробелов и не начинающееся с цифры, главное, чтобы после него стояло двоеточие.
| 123 | .CSEGlabel: LDI R16,'A' RJMP label |
В итоге, после компиляции вместо label в код подставится адрес команды перед которой стоит эта самая метка, в данном случае адрес команды LDI R16,’A’
Адресными метками можно адресовать не только код, но и данные, записанные в любом сегменте памяти. Об этом чуть ниже.
.ORG address означет примерно следующее “копать отсюда и до обеда”, т.е. до конца памяти. Данный оператор указывает с какого адреса пойдет собственно программа. Обычно используется для создания таблицы прерываний.
| 12345678910111213141516171819202122 | .CSEG.ORG 0x0000 RJMP Start ;перепрыгиваем таблицу векторов.. ORG INT0addr; External Interrupt0 Vector Address RJMP INT0_expection.ORG INT1addr; External Interrupt1 Vector Address RETI.ORG OC2addr; Output Compare2 Interrupt Vector Address RJMP PWM_1.ORG OVF2addr; Overflow2 Interrupt Vector Address RETI.ORG ICP1addr ;Input Capture1 Interrupt Vector Address RETI.ORG 0х0032; Начало основной программы Start: LDI R16,0x54; и понеслась |
Статичные данные пихаются в флеш посредством операторов
.db массив байтов.
.dw массив слов - два байта.
.dd массив двойных слов - четыре байта
.dq массив четверных слов - восем байт.
| 123 | Constant:.db 10; или 0хAh в шестнадцатеричном коде Message:.db "Привет лунатикам"Words:.dw 10, 11, 12 |
В итоге, во флеше вначале будет лежать число 0А, затем побайтно будут хекскоды символов фразы “привет лунатикам”, а дальше 000A, 000B, 000С.
Последнии числа, хоть сами и невелики, но занимают по два байта каждое, так как обьявлены как .dw.
.DSEG сегмент данных, оперативка. Те самые жалкие считанные байты. Сюда не зазорно пихать перменные, делать тут буффера, тут же находится стек.
Тут действует оператор .BYTE позволяющий указать на расположение данных в памяти.
| 12 | var1:.BYTE 1table:.BYTE 10 |
В первом случае мы указали переменную var1 состоящую из одного байта.
Во втором случае у нас есть цепочка из 10 байт и переменная table указывающая на первый байт из цепочки. Адрес остальных вычисляется смещением.
Указывать размеры перменных нужно для того, чтобы компилятор их правильно адресовал и они не налезали друг на друга.
.EESEG сегмент EEPROM, энергонезависимая память. Можно писать, можно считывать, а при пропаже питания данные не повреждаются.
Тут действуют те же директивы что и в flash — db, dw, dd, dq.
MACRO - оператор макроподстановки. Вот уж реально чумовая вещь. Позволяет присваивать имена целым кускам кода, мало того, еще параметры задавать можно.
| 1234 | .MACRO SUBI16; Start macro definition subi @1,low(@0); Subtract low byte sbci @2,high(@0); Subtract high byte. ENDM; End macro definition |
@0, @1, @2 это параметры макроса, они нумеруются тупо по порядку. А при вызове подставляются в код.
Вызов выглядит как обычная команда:
| 1 | SUBI16 0x1234,r16,r17 |
После имени через запятую передаются параметры, которые подставятся в код.
Макросы позволяют насоздавать себе удобных команд на все случаи жизни, по сути создать свой язык. Но надо помнить, что каждый макрос это тупо кусок кода, поэтому если макрос получается большой, то его лучше оформить в виде процедуры или функции - будет резкая экономия места в памяти, но выполняться будет чуток медленней.
Макроассемблер это мощнейшая штука. По ходу пьесы я буду вводить разные макросы и показывать примеры работы макроопределений.
Итак, прежде чем что то делать надо понять как вообще выполняется программа в контроллере, как работает ядро процессора. Для этого нам хватит AVR Studio и его эмулятора. Не очень интересно, может даже занудно, но если этот шаг пропустить, то дальнейшие действия будут как бег в темноте.
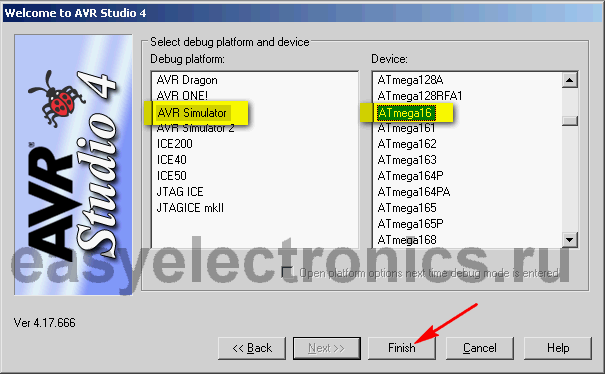
Поскольку в демоплате Pinboard используется процессор ATmega16, то рассматривать мы будем именно его. Впрочем, как я уже говорил, для других контроллеров AVR это также будет справедливо. Отличия, конечно, есть, но они не существенные.
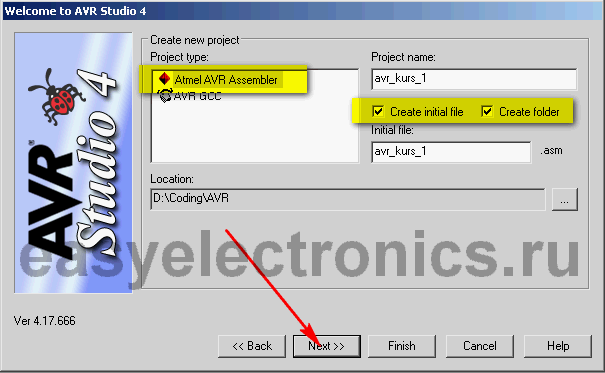
Запускаем AVR Studio (далее просто студия) и в выскочившем мастере сразу же создаем проект:
 |
 |
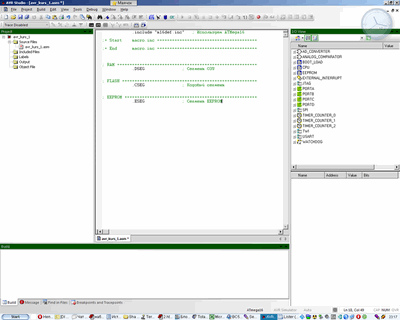
Откроется окно:
 |
Увеличить
Оно может выглядеть чуток не так. Дело в том, что интерфейс студии очень легко конфигурируется и перекраивается под себя. Так что можно перетащить панели как нам удобно. Что я и сделал.
Систему команд хорошо бы распечатать себе на листочке. Их там всего около 130, кратким списком (тип команды, что делает и какие операнды) занимает пару листов формата А4. Учить не надо, прочитать раз на десять, чтобы помнить знать что у нас есть. Даже я периодически подглядываю в систему команд, хотя пишу на ассемблере уже много лет.
Я же команды которые буду использовать буду описывать по мере появления.
В центральном окне пишем код:
| 123456789101112131415161718 | .include "m16def.inc"; Используем ATMega16;= Start macro.inc ========================================; Тут будут наши макросы, потом.;= End macro.inc ========================================; RAM =====================================================. DSEG; Сегмент ОЗУ; FLASH ===================================================. CSEG; Кодовый сегмент; EEPROM ==================================================. ESEG; Сегмент EEPROM |
Это вроде шаблона для начала любого проекта. Правда кода тут 0 байт:) Только директивы.
Обрати также внимание на оформление кода. Дело в том, что в ассемблере нет никаких структурных
элементов — весь код плоский, тупо в столбик. Так что поэтому чтобы он был читабелен его надо в обязательно порядке разбивать на блоки, активно пользоваться табуляцией и расставлять комментарии. Иначе уже через пару дней ты не сможешь понять, что вообще написал.
В коде будут активно использоваться макросы. Поначалу они будут писаться в основном файле, в секции macro.inc, но потом я их вынесу в отдельный файл, чтобы не мешались. Так удобней.
Как я уже говорил, в микроконтроллере куча раздельных видов памяти. И тут используется гарвардская архитектура. Т.е. исполняемый код в одном месте, а переменные в другом. Причем это разные адресные пространства. Т.е. адрес 0000 в сегменте данных это не то же что и адрес 0000 в сегменте кода. Это дает большое преимущество в том, что данные не могут испортить код, но не дает писать полиморфные программы. Такая архитектура является традиционной для микроконтроллеров.
У обычного PC компа используется другая архитектура - Фон Неймановская. Там данные и код находятся в одном адресном пространстве. Т.е., скажем, с адреса 0000 по 0100 идет код, а с 100 до FFFF данные.
В нашей же программе и код и данные располагаются на одном листе, но чтобы компилятор понял где у нас что они выделяются директивами сегментации. Пока нас интересуют директива.CSEG после нее начинается исполняемый код. Там и будем писать нашу программу.
Возьмем и напишем:
| 12345 | ; FLASH ===================================================. CSEG; Кодовый сегмент NOP NOP NOP |
Что мы сделали? А ничего! Команда NOP это команда затычка. Она не делает ничего, просто занимает 2 байта и 1 такт.
Речь не о команде NOP (там и обсуждать то нечего), а о том как оно все будет выполняться.
Запускай симуляцию (Ctrl+F7) когда пробежит прогресс бар компиляции/симуляции и возле первого NOP возникнет стрелочка нажми ALT+O — выскочит диалог настройки симуляции. Там тебе надо там только выставить частоту 8Мгц. Почему 8Мгц? Просто на Pinboard частота главного проца по дефолту 8Мгц. Если у тебя свои идеи на этот счет — можешь поправить как угодно. На симуляцию это не влияет.
Вернемся к нашей симуляции. Давай посмотрим как выглядит наша программа с точки зрения машинных кодов, как размещается в памяти. Интерес, по большей части, чисто теоретический, редко когда пригождается и по этому во многих учебных курсах по AVR на это даже внимание не заостряют. А зря! Т.к. упускается глубинное ощущение кода. Открой окно просмотра программ. View - Memory или Alt+4.
Там выбери тип памяти Programm. Это и есть наш Flash сегмент. Выставим в списке cols две колонки, чтобы было наглядней.
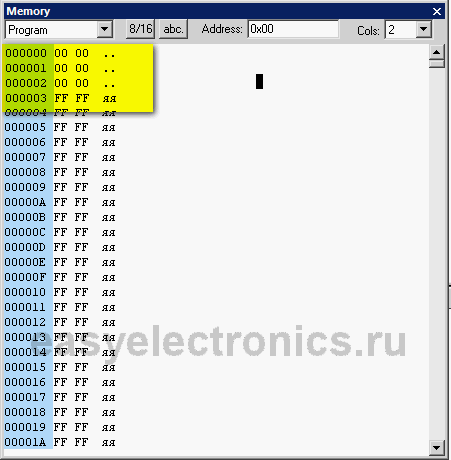 |
Это наша память программ. На голубом фоне идут адреса, они, как видишь, в словах. Т.е. двум байтам соответствует один адрес. Но, на самом деле это интерпретация адресации компилятором, микроконтроллер же может оперировать в памяти программ с точностью до байта.
0000 это код команды NOP. У нас три команды, поэтому шесть нулей.
Обрати внимание на то, что команды идут с адреса 0000. Это потому, что мы не указали ничего иного. А кодовый сегмент начинается с адреса 0000.
Теперь смотрим на программный счетчик Programm Counter, он показывает адрес инструкции которая будет выполнена.
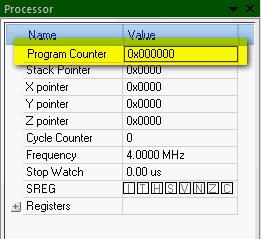 |
Поскольку мы только стартанули, то он равен нулю — нулевая инструкция. Нажми F11, процессор сделает шаг, программный счетчик изменится на 1 и покажет следующую инструкцию. И так до тех пор, пока не дойдет до третьего NOP, а что у нас после него? А после него у нас FF до конца памяти. FF это несуществующая инструкция, на ней виртуальный контроллер перезагрузится с ошибкой invalid opcode, а реальный контроллер ее проигнорирует, пробежав по ним, как по NOP, до конца памяти.
Сбрось симуляцию микроконтроллера (Shift+F5) и вручную выстави в Program Counter адрес 0×000002 — проц сам перепрыгнет на последнюю команду NOP. Если менять Program Counter то проц будет выполнять те команды, которые мы ему укажем. Но как это сделать в реальном контроллере? В него то мышкой не залезешь!
Программный счетчик меняется командами переходов. Их много (условные, безусловные, относительные), о них я расскажу подробней чуть позже, пока же приведу один пример.
Добавим в наш код команду JMP и ее аргумент — адрес 0×000001.
| 12345 | .CSEG; Кодовый сегмент NOP NOP NOP JMP 0x000001 |
Команда JMP, как и все команды перехода, работает просто — записывает в Program Counter свой аргумент. В нашем случае — 0×000001.
Перекомпиль проект и посмотри на то, как меняется Program Counter (далее буду звать его PC) и вообще как теперь идет процесс выполнения программы. Видишь, после JMP в программный счетчик заносится новый адрес и процессор сразу же перепрыгивает в начало кода, но не на первую, а на вторую инструкцию. Программа зациклилась.
Это называется абсолютный переход. Он может сигануть куда угодно, в любую область памяти программ. Но за такую дальнобойность приходится платить. Если заглянешь в память, то увидишь там такую картину:
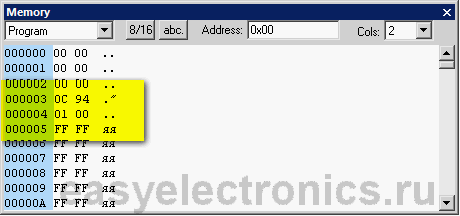 |
OC 94 - это код нашей комады, а 01 00 адрес перехода. Длина команды стала четыре байта. Два байта ушло на адрес. Вот, кстати, особенность памяти в том, что там данные записываются зеркально, т.е. младший байт числа по младшему адресу (порядок little-endian).
Но поскольку дальнобойные команды применяются редко, основной командой перехода в AVR является относительный переход RJMP. Основное отличие тут в том, что в PC не записывается не точный адрес куда надо перейти, а просто к PC прибавляется смещение. Вот так:
| 123456789 | .CSEG; Кодовый сегмент NOP NOP NOP RJMP PC+2 NOP NOP RJMP PC-6 NOP |
По идее, должно работать напрямую, т.е. RJMP +2. Но компилятор такую запись не понимает, он оперирует абсолютными адресами, приводя их потом в нужные смещения машинного кода. Поэтому применим макроопределение PC - это текущее значение счетчика в данном месте программы. Т.е.
| 1 | JMP PC |
Наглухо зациклит программу в этой строчке.
Благодаря относительному переходу, смещение можно запихать в те же два байта, что занимает команда. При этом код относительного перехода выглядит так Сх хх, где ххх это смещение от +/-2047 команд. Что обычно хватает с лихвой. В памяти же команда перехода выглядит как хх Сх, то есть байты переставлены.
Таким образом, длина команды у относительного перехода составляет 2 байта, против четырех у абсолютного. Экономия!!! Учитывая что в обычной программе подобные переходы на каждом шагу.
Вот только что же, каждый раз самому вручную высчитывать длину перехода? Ладно тут программка в три команды, а если их сотни? Да если дописал чуток то все переходы заново высчитывать?
Угу. Когда то давно, когда компиляторов еще не было так и делали. Cейчас же все куда проще — компилятор все сделает сам. Ему только надо указать откуда и куда. Делается это с помощью меток.
| 123456789 | .CSEG; Кодовый сегмент M1: NOP NOP NOP RJMP M2 NOPM2: NOP RJMP M1 NOP |
Метки могут быть из букв или цифр, без пробелов и не начинаться с цифр. Заканчиваются двоеточием. По факту, метка означает текущий адрес в словах. Так что ее можно использовать и в операциях. Надо только помнить, что она двубайтная, а наш контроллер однобайтный. Разобрать двубайтное значение по байтам можно с помощью директивы компилятора Low и High
Например,
| 1234567891011121314 | .CSEG; Кодовый сегмент M1: NOP NOP LDI ZL,low(M2); Загрузили в индекс LDI ZH,High(M2) IJMP NOP NOP NOPM2: NOP RJMP M1 NOP |
Команда LDI загружает непосредственное значение в регистр старшей (от R16 до R31) группы. Например, LDI R17,3 и в R17 будет число 3. А тут мы в регистры R30 (ZL) загрузили младший байт адреса на который указывает метка М2, а в R31 (ZH) старший байт адреса. Если протрассируешь выполнение (F11) этого кода, то увидишь как меняются значения регистров R30 и R31 (впрочем 31 может и не поменяться, т.к. там был ноль, а мы туда ноль и запишем — адрес то мал). Смену значений регистров можно поглядеть в том же окне где и Program Counter в разделе Registers.
Команда IJMP это косвенный переход. Т.е. он переходит не по адресу который заложен в коде операции или идет после него, а по адресу который лежит в индексной регистровой паре Z. Помните я говорил, что шесть последних регистров старшей регистровой группы образуют три регистровые пары X,Y,Z используются для адресации? Вот это я и имел ввиду.
После IJMP мы переходим на нашу же М2, но хитровывернутым способом. Зачем вообще так? Не проще ли применить RJMP и JMP. В этом случае да, проще.
Но вот благодаря косвенному переходу мы можем программно менять точку перехода. И это просто зверский метод при обработке всяких таблиц и создании switch-case структур или конечных автоматов. Примеры будут позже, пока попробуйте придумать сами.
Давай подвинем нашу кодовую конструкцию в памяти на десяток байт. Добавь в код директиву ORG
| 123456789101112131415161718 | ; FLASH ===================================================. CSEG; Кодовый сегмент NOP.ORG 0x0010M1: NOP NOP LDI ZL,low(M2); Загрузили в индекс LDI ZH,High(M2) IJMP NOP NOP NOPM2: NOP RJMP M1 NOP |
Скомпиль и запусти. Открой память и увидишь что в точке с адресом 0000 у нас стоит наш NOP (Точка входа должна быть, иначе симулятор скукожит от такого когнитивного диссонанса. А вот дальше сплошные FF FF и лишь начиная с нашего адреса 0×0010 пошли коды остальных команд.
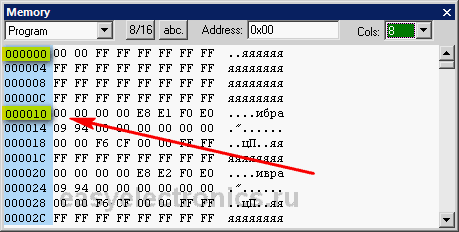 |
То есть мы разбили код, заставив директивой ORG компилятор перетащить его дальше, начиная с 0×0010 адреса.
Зачем это нам потребовалось? Ну, в первую очередь, это требуется чтобы перешагнуть таблицу векторов прерываний. Она находится в первых адресах.
Во-вторых, такая мера нужна чтобы записать код в конец флеша, при написании бутлоадеров (о них тоже дальше в курсе будет).
А еще таким образом можно прятать в коде данные, перемешивая данные с кодом. Тогда дизассемблирование такой программы превратится в ад =) своего рода, обфускация публичной прошивки, сильно затрудняющая реверс инженеринг.
Да, у кристалла есть биты защиты. Выставил которые и все, программу можно считать только спилив крышку кристалла с помощью электронных микроскопов, что очень и очень недешево. Но иногда надо оставить прошивку на виду, но не дать сорцов. И вот тогда превращение прошивки в кашу очень даже поможет =)
Ну или написать ее на Си;))))))) (Есть вариант шифровки прошивки и дешифровки ее на лету бутлоадером, но это отдельная тема. О ней может быть расскажу)
Еще, там, в студии, же где и программный счетчик, есть ряд интересных параметров.
Во-первых, там отдельно вынесены наши индексные пары X,Y,Z и можно не лазать на дно раздела Registers.
Во-вторых, там есть Cycle counter — он показывает сколько машинных циклов протикал наш контроллер. Один машинный цикл в AVR равен одному такту. Frequency содержит частоту контроллера в данный момент, но мы задаем ее вручную.
А в-третьих, есть Stop Watch который показывает время выполнения. В микросекундах. Но можно переключить и в миллисекунды (пошарь в контекстном меню).
Если тебе кажется, что все слишком просто и я чрезмерно все разжевываю. Хы, не расслабляйся, у меня сложность растет по экспоненте. Скоро пойдет работа на прерываниях, а потом будем писать свою операционную систему:))))))
Так, с работой ядра на предмет переходов и адресации разобрались. Пора обратить свой взор в другую область — память.
Ее тут два вида (EEPROM не в счет т.к. она вообщет переферия, а о ней потом):
- RAM - оперативка
- ROM - ПЗУ, она же flash, она же память программ
Так как архитектура у нас Гарвардская, то у оперативы своя адресация, а у флеша своя. В даташите можно увидеть структуру адресации ОЗУ.
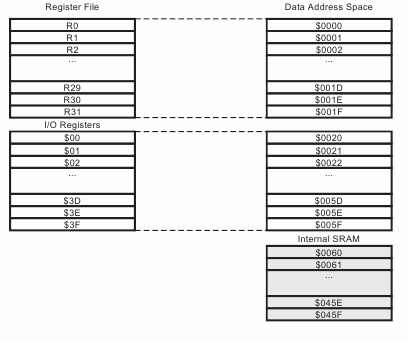 |
Сразу обратите внимание на адреса! РОН и регистры периферии, а также ОЗУ находятся в одном адресном пространстве. Т.е. адреса с 0000 по 001F занимают наши регистры, дальше вплоть до адреса 005F идут ячейки ввода-вывода — порты. Через порты происходит конфигурирование всего, что есть на борту контроллера. И только потом, с адреса 0060 идет наше ОЗУ, которое мы можем использовать по назначению.
Причем обратите внимание, что у регистров I/O есть еще своя адресация — адресное пространство регистров ввода-вывода (от 00 до 3F), она указана на левой части рисунка. Блок IO/Register Эта адресация работает ТОЛЬКО в командах OUT и IN Из этого вытекает интересная особенность.
К регистрам периферии можно обратиться двумя разными способами:
- Через команды IN/OUT по короткому адресу в пространстве адресов ввода-вывода
- Через группу команд LOAD/STORE по полному адресу в пространстве адресов RAM
Пример. Возьмем входной регистр асинхронного приемопередатчика UDR он имеет адрес 0×0C(0х2С) в скобках указан адрес в общем адресном пространстве.
| 1234567 | LDI R18,10; Загрузили в регистр R18 число 10. Просто так OUT UDR,R18; Вывели первым способом, компилятор сам; Подставит вместо UDR значение 0х0С STS 0x2C,R18; Вывели вторым способом. Через команду Store; Указав адрес напрямую. |
Оба метода дают идентичные результаты. НО! Те что работают адресацией в пространстве ввода-вывода (OUT/IN) на два байта короче. Это и понятно - им не нужно хранить двубайтный адрес произвольной ячейки памяти, а короткий адрес пространства ввода–вывода влезает и в двухбайтный код команды.
Правда тут возникает еще один прикол. Дело в том, что с каждым годом появляются все новые и новые камни от AVR и мяса в них все больше и больше. А каждой шкварке нужно свои периферийные регистры ввода-вывода. И вот, дожили, в ATMega88 (что пришла на замену Mega8) периферии уже столько, что ее регистры ввода-вывода уже не умещаются в лимит адресного пространства 3F.
Опаньки, приплыли. И вот тут у тех кто пересаживается с старых камней на новые начинаются недоуменные выражения — с чего это команды OUT/IN на одних периферийных регистрах работают, а на других нет?
А все просто — разрядности не хватило.
А ядро то единое, его уже не переделать. И вот тут ATMELовцы поступили хитро — они ввели так называемые memory mapped регистры. Т.е. все те регистры, что не влезли в лимит 3F доступны теперь только одним способом — через Load/Store.
Вот такой прикол. Если открыть какой нибудь m88def.inc то там можно увидеть какие из регистров ввода-вывода “правильные” а какие memory mapped.
Будет там бодяга вот такого вида:
| 12345678910111213141516171819202122232425 | ; ***** I/O REGISTER DEFINITIONS *****************************************; NOTE:; Definitions marked "MEMORY MAPPED"are extended I/O ports; and cannot be used with IN/OUT instructions. equ UDR0 = 0xc6; MEMORY MAPPED. equ UBRR0L = 0xc4; MEMORY MAPPED. equ UBRR0H = 0xc5; MEMORY MAPPED. equ UCSR0C = 0xc2; MEMORY MAPPED. equ UCSR0B = 0xc1; MEMORY MAPPED. equ UCSR0A = 0xc0; MEMORY MAPPED бла бла бла, и еще много такого.equ OSCCAL = 0x66; MEMORY MAPPED. equ PRR = 0x64; MEMORY MAPPED. equ CLKPR = 0x61; MEMORY MAPPED. equ WDTCSR = 0x60; MEMORY MAPPED. equ SREG = 0x3f ;<------ А тут пошли обычные. equ SPL = 0x3d.equ SPH = 0x3e.equ SPMCSR = 0x37.equ MCUCR = 0x35.equ MCUSR = 0x34.equ SMCR = 0x33.equ ACSR = 0x30 |
Вот такие пироги.
И на этой ниве понимаешь, что в сторону кроссмодельной совместимости ассемблерного кода летит летит большой мохнатый орган с целью наглухо его накрыть. Ведь одно дело подправить всякие макроопределения и дефайны, описывающие регистры, а другое сидеть и, аки Золушка, отделять правильные порты от неправильных.
Впрочем есть решение. Макроязык! Не нравится система команд? Придумай свою с блекджеком и шлюхами!
Сварганим свою собственную команду UOUT типо универсальный OUT
| 1234567 | .macro UOUT.if @0 < 0x40 OUT @0,@1.else STS @0,@1.endif.endm |
Если значение входного параметра @0 меньше 0х40 значит это “правильный” регистр. Если больше - memory_mapped.
Дальше везде, не думая, используем UOUT вместо OUT и не парим себе мозг извратами адресации. Компилятор сам подставит нужную инструкцию.
| 1 | UOUT UDR,R18 |
Аналогично и для команды IN Вообще, такими вот макросами можно ОЧЕНЬ сильно разнообразить ассемблер, превратив его в мощнейший язык программирования, рвущий как тузик тряпку всякие там Си с Паскалями.
Ну так о чем я… а о ОЗУ.
Итак, с адресацией разобрались. Адреса памяти, откуда начинаются пользовательские ячейки ОЗУ теперь ты знаешь где смотреть — в даташите, раздел Memory Map. Но там для справки, чтобы знать.
А в нашем коде оперативка начинается с директивы.DSEG Помните наш шаблончик?
| 12345678910111213141516171819 | .include "m16def.inc"; Используем ATMega16;= Start macro.inc ===============================; Макросы тут;= End macro.inc =================================; RAM =============================================. DSEG; Сегмент ОЗУ; FLASH ===========================================. CSEG; Кодовый сегмент; EEPROM ==========================================. ESEG; Сегмент EEPROM |
Вот после.DSEG можно задавать наши переменные. Причем мы тут имеем просто прорву ячеек — занимай любую. Указал адрес и радуйся. Но зачем же вручную считать адреса? Пусть компилятор тут думает.
Поэтому мы возьмем и зададим меточку
| 123 | .DSEGVariables:.byte 3Variavles2:.byte 2 |
Директива.byte зарезервирует нам столько байт, сколько мы ей указали. Таким образом, на Variables у нас будет три байта, а на Variables2 два байта.
Если считаем, что у нас Atmega16, а у ней адреса RAM начинаются с 0х0060, то компилятор посчитает адреса так:
Variables = 0×0060
Variables2 = 0×0063
А в памяти это будет лежать следующим образом (приведу в виде линейного списка):
| 123456 | 0x0060 ## ;Variables 0x0061 ##0x0062 ##0x0063 ## ;Variables2 0x0064 ##0x0065 ## ;Тут могла бы начинаться Variables4 |
В качестве ## любой байт. По дефолту FF. Разумеется ни о какой типизации переменных, начальной инициализации, контроля за переполнениями и прочих буржуазных радостей говорить не приходится. Это Спарта! В смысле, ассемблер. Все ручками.
Если провести аналогию с Си, то это как работа с памятью через одни лишь void указатели. Сишники поймут. Поймут и ужаснутся. Т.к. мир этот жесток и коварен. Чуть просчитался с индексом — затер другие данные. И хрен ты эту ошибку поймаешь если она сразу не всплывет.
Так что внимание, внимание и еще раз внимание. Все операции с памятью прогоняем через трассировку и ничего у нас не вылезет и не переполнится.
В сегменте данных работает также директива.ORG Работает точно также — переносит адреса, в данном случае меток, от сих и до конца памяти. Одна лишь тонкость — ORG 0000 даст нам самое начало ОЗУ, а это R0 и прочие регистры. А нулевой километр ОЗУ на примере Мега16 даст ORG 0×0060. А в других контроллерах еще какое-нибудь значение. Каждый раз в даташит лазать лениво, поэтому есть такое макроопределение как SRAM_START указывающее на начало ОЗУ для конкретного МК.
Вообще полезно почитать файл m16def.inc на предмет символических имен разных констант.
Так что если хотим начало ОЗУ, скажем 100 байт оставить под какой нибудь мусорный буффер, то делаем такой прикол.
| 1234 | .DSEG.ORG SRAM_START+100 Variables:.byte 3 |
Готово, расчистили себе буфферную зону от начала до 100.
Ладно, с адресацией разобрались. Как работать с ячейками памяти? А для этих целей существует две группы команд. LOAD и STORE самая многочисленная группа команд.
Дело в том, что с ячейкой ОЗУ ничего нельзя сделать кроме как загрузить в нее байт из РОН, или выгрузить из нее байт в РОН.
Записывают в ОЗУ команды Store (ST**), а считываю команды Load (LD**).
Чтение идет в регистр R16…R31, а адрес ячейки задается либо непосредственно в команде. Вот простой пример. Есть трехбайтная переменная Variables, ее надо увеличить на 1. Т.е. сделать операцию Variables++
| 123456789101112131415161718192021 | .DSEGVariables:.byte 3Variavles2:.byte 1.CSEG; Переменная лежит в памяти, сначала надо ее достать. LDS R16, Variables; Считать первый байт Variables в R16 LDS R17, Variables+1; Считать второй байт Variables в R17 LDS R18, Variables+2; Ну и третий байт в R18; Теперь прибавим к ней 1, т.к. AVR не умеет складывать с константой, только; вычитать, приходиться извращаться. Впрочем, особых проблем не доставляет. SUBI R16,(-1); вообще то SUBI это вычитание, но -(- дает + SBCI R17,(-1); А тут перенос учитывается. Но об этом потом. SBCI R18,(-1); Математика в ассемблере это отдельная история STS Variables,R16; Сохраняем все как было. STS Variables+1,R17 STS Variables+2,R18 |
А можно применить и другой метод. Косвенную запись через индексный регистр.
| 123456789101112131415161718192021222324 | .DSEGVariables:.byte 3Variavles2:.byte 1.CSEG; Берем адрес нашей переменной LDI YL,low(Variables) LDI YH,High(Variables); Переменная лежит в памяти, сначала надо ее достать. LD R16, Y+; Считать первый байт Variables в R16 LD R17, Y+; Считать второй байт Variables в R17 LD R18, Y+; Ну и третий байт в R18; Теперь прибавим к ней 1, т.к. AVR не умеет складывать с константой, только; вычитать, приходиться извращаться. Впрочем, особых проблем не доставляет. SUBI R16,(-1); вообще то SUBI это вычитание, но -(- дает + SBCI R17,(-1); А тут перенос учитывается. Но об этом потом. SBCI R18,(-1); Математика в ассемблере это отдельная история ST -Y,R18; Сохраняем все как было. ST -Y,R17; Но в обратном порядке ST -Y,R16 |
Тут уже заюзаны операции с постинкрементом и преддекрементом. В первой сначала читаем, потом прибавляем к адресу 1. Во второй вначале вычитаем из адреса 1, а потом сохраняем.
Подобными инкрементальными командами удобно перебирать массивы в памяти или таблицы какие.
А там есть еще и косвенная относительная запись/чтение LDD/STD и еще варианты на все три вида индексов (X,Y,Z). В общем, кури даташит и систему команд.
Стек
О, стек это великая вещь. За что я его люблю, так это за то, что срыв стека превращает работоспособную программу в полную кашу. За то что стековые операции требуют повышенного внимания, за то что если где то стек сорвет и сразу не отследишь, то фиг это потом отловишь… В общем, прелесть, а не штуковина.
Почему люблю? Ну дык, если Си это тупое ремесло, быстро и результативно, то Ассемблер это филигранное искусство. Как маньяки вроде Jim’a из бумаги и только из бумаги клепают шедевры, хотя, казалось бы, купи готовую сборную модель и клей себе в удовольствие. Так и тут — от самого процесса прет нипадецки. В том числе и от затраха с отладкой:))))
Так вот, о стеке. Что это такое? А это область памяти. Работает по принципу стопки. Т.е. какую последнюю положил, ту первой взял.
У стека есть указатель, он показывает на вершину стека. За указатель стека отвечает специальный регистр SP, а точнее это регистровая пара SPL и SPH. Но в микроконтроллерах с малым обьемом ОЗУ, например в Тини2313, есть только SPL
При старте контроллера, обычно, первым делом инициализируют стек, записывая в SP адрес его дна, откуда он будет рости. Обычно это конец ОЗУ, а растет он к началу.
Делается это таким вот образом, в самом начале программы:
| 12345 | LDI R16,Low(RAMEND) OUT SPL,R16 LDI R16,High(RAMEND) OUT SPH,R16 |
Где RAMEND это макроопределение указывающий на конец ОЗУ в текущем МК.
Все, стек готов к работе. Данные кладутся в стек командой PUSH Rn, а достаются через POP Rn.
Rn - это любой из РОН.
Еще со стеком работают команды CALL, RCALL, ICALL, RET, RETI и вызов прерывания, но об этом чуть позже.
Давай-ка поиграемся со стеком, чтобы почувствовать его работу, понять как и куда он движется.
Вбей в студию такой код:
| 1234567891011121314151617181920212223242526272829303132333435363738394041 | .CSEG; Кодовый сегмент LDI R16,Low(RAMEND); Инициализация стека OUT SPL,R16 LDI R16,High(RAMEND) OUT SPH,R16 LDI R17,0; Загрузка значений LDI R18,1 LDI R19,2 LDI R20,3 LDI R21,4 LDI R22,5 LDI R23,6 LDI R24,7 LDI R25,8 LDI R26,9 PUSH R17; Укладываем значения в стек PUSH R18 PUSH R19 PUSH R20 PUSH R21 PUSH R22 PUSH R23 PUSH R24 PUSH R25 PUSH R26 POP R0; Достаем значения из стека POP R1 POP R2 POP R3 POP R4 POP R5 POP R6 POP R7 POP R8 POP R9 |
А теперь запускай студию в пошаговое выполнение и следи за тем как будет меняться SP. Stack Pointer можно поглядеть в студии там же, где и Program Counter.
Вначале мы инициализируем стек и загрузим регистры данными. В результате получится следующая картина:
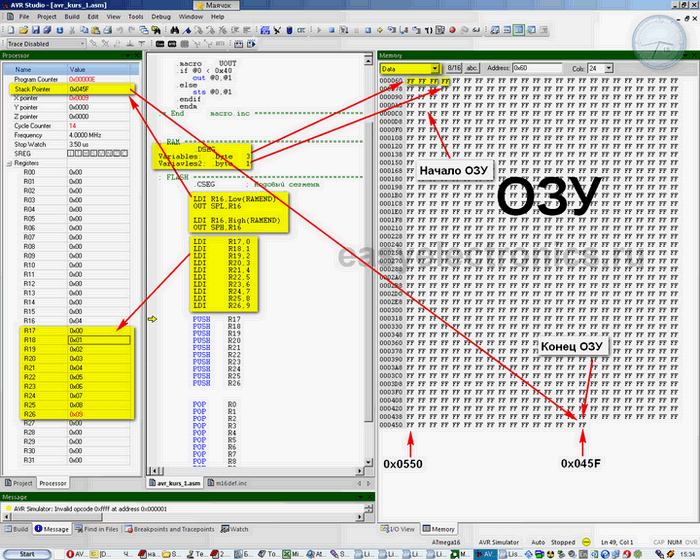 |
увеличить
Затем начнем по одному пихать данные в стек. При этом будет видно, как данные заполняют память начиная от конца, к началу. А SP меняется в сторону уменьшения. Указывая на следующую ячейку.
После всех команд PUSH наши данные окажутся в памяти:
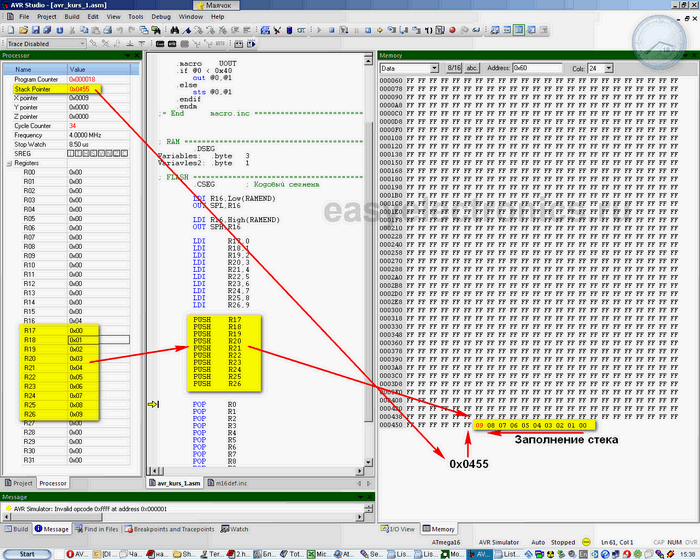 |
увеличить
Дальше, командой POP, мы достаем данные из стека. Обрати внимание на то, что нам совершенно не важно откуда мы положили данные в стек и куда мы их будем сгружать. Главное порядок укладки! Ложили мы из старших регистров, а достанем в младшие. При этом указатель стека будет увеличиваться.
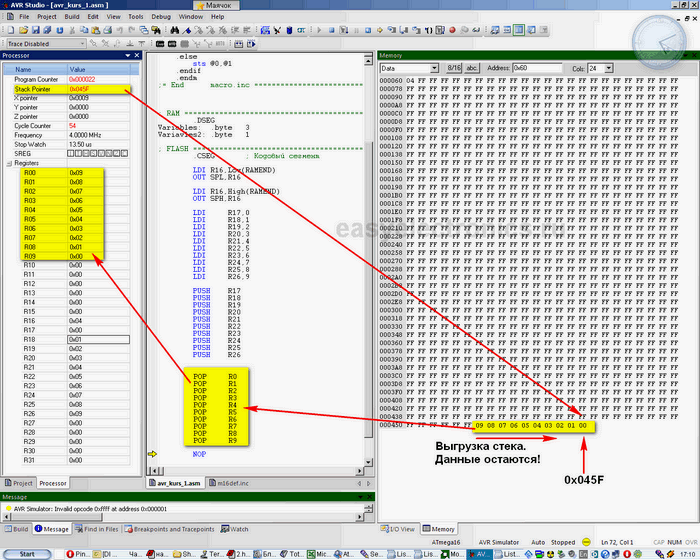 |
увеличить
Да, еще немаловажный момент. Данные при этом никуда из памяти не деваются, так и остаются висеть в памяти. При следующем заполнении стека их просто перепишет и все.
Как пользоваться стеком?
Ну во первых, стек используют команды вызовов и возвратов (CALL, RCALL, ICALL, RET, RETI), а еще это удобное средство по быстрому свапить или сохранять байты.
Вот, например, надо тебе обменять содержимое двух регистров R17 и R16 местами. Как сделать это без использования третьего регистра? Самое простое - через стек. Положим из одного, достанем в другой.
| 1234 | PUSH R16 PUSH R17 POP R16 POP R17 |
Или сохранить какой нибудь значение регистра, пока его используем в другом месте.
Например, я уже говорил про ограничение младших РОН — они не дают записать в себя число напрямую. Только через регистры старшей группы. Но это же неудобно!
Проблема решается с помощью макроса. Я назвал его LDIL - LDI low
| 123456 | .MACRO LDIL PUSH R17; Сохраним значение одного из старших регистров в стек. LDI R17,@1; Загрузим в него наше непосредственное значение MOV @0,R17; перебросим значение в регистр младшей группы. POP R17; восстановим из стека значение старшего регистра.. ENDM |
Теперь можно легко применять нашу самодельную команду.
| 1 | LDIL R0,18 |
Со временем, файл с макросами обрастает такими самодельными командами и работать становится легко и приятно.
Стековые ошибки
Стек растет навстречу данным, а теперь представьте что у нас в памяти есть переменная State и расположена она по адресу, например, 0х0450. В опасной близости от вершины стека. В переменной хранится, например, состояние конечного автомата от которого зависит дальнейшая логика работы программы. Скажем если там 3, то мы идем делать одно, если 4 то другое, если 5 то еще что-то и так до 255 состояний. И по логике работы после 3 должна идти 4ре, но никак не 10
И вот было там 3. И тут, в один ужасный момент, условия так совпали, что стек разросся и его вершина дошла до этой переменной, вписав туда значение, скажем 20, а потом борзо свалила обратно. Оставив гадость — классический пример переполнения стека. И логика программы вся нахрен порушилась из-за этого.
Либо обратный пример — стек продавился до переменных, но в этот момент переменные обновились и перезаписали стековые данные. В результате, со стека снялось что-то не то (обычно кривые адреса возврата) и программе сорвало крышу. Вот такой вариант, кстати, куда более безобидный, т.к. в этом случае косяк видно сразу и он не всплывает ВНЕЗАПНО спустя черт знает сколько времени.
Причем эта ошибка может то возникать, то исчезать. В зависимости от того как работает программа и насколько глубоко она прогружает стек. Впрочем, такое западло чаще встречается когда пишешь на Си, где не видно насколько активно идет работа со стеком. На асме все гораздо прозрачней. И тут такое может возникнуть из-за откровенно кривого алгоритма.
На долю ассемблерщиков часто выпадают другие стековые ошибки. В первую очередь забычивость. Что то положил, а достать забыл. Если дело было в подпрограмме или в прерывании, то искажается адрес возврата (о нем чуть позже), стек срывает и прога мгновенно рушится. Либо невнимательность — сохранял данные в одном порядке, а достал в другом. Опа и содержимое регистров обменялось.
Чтобы избегать таких ошибок нужно, в первую очередь, следить за стеком, а во вторых грамотно планировать размещение переменных в памяти. Держа наиболее критичные участки и переменные (такие как состояния конечных автоматов или флаги логики программы) подальше от стековой вершины, поближе к началу памяти.
У некоторых возникнет мысль, что можно же взять и стек разместить не на самом конце ОЗУ, а где нибудь поближе, оставив за ним карман для критичных данных. На самом деле не слишком удачная мысль. Дело в том, что стек можно продавить как вниз, командой PUSH так и вверх — командами POP. Второе хоть и случается намного реже, т.к. это больше грех кривых рук, чем громоздкого алгоритма, но тоже бывает.
Но главное это то, что стек сам по себе сверхважная структура. На ней держится весь механизм подпрограмм и функций. Так что срыв стека это ЧП в любом случае.
Стековые извраты
Моя любимая тема. =)))) Несмотря на то, что стековый указатель сам вычисляется при командах PUSH и POP, никто не мешает нам выковырять его из SP, да использовать его значения для ручного вычисления адреса данных лежащих в стеке. Либо подправить стековые данные как нам угодно.
Зачем? Ну применений можно много найти, если напрячь мозг и начать думать нестандартно:))))
Плюс через стек, в классическом Си и Паскале на архитектуре х86 передаются параметры и работают локальные переменные. Т.е. перед вызовом функции вначале все переменные пихаются в стек, а потом, после вызова функции, в стек пихаются байты будущих локальных переменных.
После, используя SP как точку отсчета, мы можем обращаться с этими переменными как нам угодно. А при освобождении стека командой POP они аннигилируются, освобождая память.
В AVR все несколько не так (видимо связано с малым обьемом памяти, где в стек особо не насуешься, зато есть прорва РОН, но механизм этот тоже можно попробовать использовать.
Правда это уже напоминает нейрохирургию. Чуть ошибся и пациент труп.
Благодаря стеку и ОЗУ можно обходиться всего двумя-тремя регистрами, не особо испытывая напряг по поводу их нехватки.

