 2017-12-14
2017-12-14 548
548Итак, распознавание тупика может быть основано на анализе модели распределения ресурсов. Один из алгоритмов, основанный на методе обнаружения замкнутой цепи запросов, был разработан сотрудниками фирмы IBM; этот алгоритм использовался в одной из ОС этой компании. Он использует информацию о состоянии системы, содержащуюся в двух таблицах: таблице текущего распределения (назначения) ресурсов RATBL и «таблице» заблокированных процессов PWTBL (для каждого вида ресурса может быть свой список заблокированных процессов). При каждом запросе на получение или освобождении ресурсов содержимое этих таблиц модифицируется, а при запросе – анализируется в соответствии со следующим алгоритмом, который описан по пунктам.
1. Запрос от процесса J на занятый ресурс I.
2. Поместить номер ресурса I в PWTBL в строке с номером процесса J.
3. Использовать I в качестве смещения в RATBL, чтобы найти номер процесса К, который владеет ресурсом.
4. Использовать К в качестве смещения в PWTBL.
5 Проверить, ждёт ли процесс К освобождения какого-либо ресурса I’. Если нет, то перейти к шагу 6, в противном случае – к шагу 7.
|
|
|
6 Перевести Jв состояние ожидания и выйти из алгоритма.
7 Использовать I’ в качестве смещения в RATBL, чтобы найти номер блокирующего его процесса К'.
8 Проверить К' = J. Если нет, то перейти к шагу 9, в противном случае – к шагу 11.
9 Проверить, вся ли таблица PWTBL просмотрена. Если да, то перейти к шагу 6, в противном случае – к шагу 10.
10 Присвоить К:= К' и перейти к шагу 4.
11 Вывод о наличии тупика с последующим восстановлением.
12 Конец алгоритма.
Для иллюстрации описанного алгоритма распознавания тупика рассмотрим следующую последовательность событий:
1 Процесс Р1 занимает ресурс R1.
2 Процесс Р2 занимает ресурс R3.
3 Процесс РЗ занимает ресурс R2.
4 Процесс Р2 занимает ресурс R4.
5 Процесс Р1 занимает ресурс R5.
В результате таблица распределения ресурсов (RATBL) имеет следующий вид:
Таблица 7.3. Таблица распределения ресурсов RATBL
| Ресурсы | Процессы |
1 Пусть процесс Р1 пытается занять ресурс R3, поэтому в соответствии с описанным алгоритмом J = 1, I= 3, К = 2. Процесс К не ждёт никакого ресурса I’, поэтому процесс Р1 блокируется по ресурсу R3.
2 Далее, пусть процесс Р2 пытается занять ресурс R2.
J = 3, I= 2, К = 3.
Процесс К не ждёт никакого ресурса, поэтому процесс Р2 блокируется по ресурсу R2.
3 И наконец, пусть процесс РЗ пытается обратиться к ресурсу R5.
J= 3,I= 5, К = 1,I’ = 3, К’ = 2,K'< >J, поэтому берём К = 2,I’ = 2, К' = 3.
В этом случае К' = J, то есть тупик определён. Таблица заблокированных процессов (PWTBL) теперь имеет следующий вид.
Таблица 7.4, Таблица заблокированных процессов PWTBL
|
|
|
| Процесс | Ресурс |
Равенство J= К' означает, что существует замкнутая цепь взаимоисключающих и ожидающих процессов, то есть выполняются все четыре условия существования тупика.
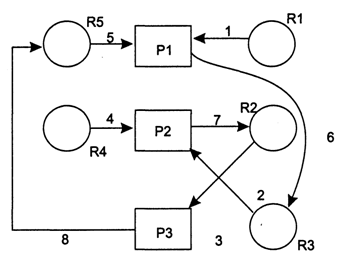
описанного нами примера можно построить модель Холта; её изображение приведено на рис. 7.14. На этом рисунке пронумерованы дуги запросов, которые процессы последовательно генерировали в соответствии с нашим примером. Из рисунка сразу видно, что в результате такой последовательности запросов образовалась замкнутая цепочка: (8, 5, 6, 2, 7, 3), что и говорит о существовании тупика.
Рис. 7.14. Граф распределения ресурсов
Распознавание тупика требует дальнейшего восстановления.
Восстановление можно интерпретировать как запрет постоянного пребывания в опасном состоянии. Существуют следующие методы восстановления:
¨ принудительный перезапуск системы, характеризующийся потерей информации обо всех процессах, существовавших до перезапуска;
¨ принудительное завершение процессов, находящихся в тупике;
¨ принудительное последовательное завершение процессов, находящихся в тупике, с последующим вызовом алгоритма распознавания после каждого завершения до исчезновения тупика;
¨ перезапуск процессов, находящихся в тупике, с некоторой контрольной точки, то есть из состояния, предшествовавшего запросу на ресурс;
¨ перераспределение ресурсов с последующим последовательным перезапуском процессов, находящихся в тупике.
Основные издержки восстановления составляют потери времени на повторные вычисления, которые могут оказаться весьма существенными. К сожалению, в ряде случаев восстановление может стать невозможным: например, исходные данные, поступившие с каких-либо датчиков, могут уже измениться, а предыдущие значения будут безвозвратно потеряны.








