 2020-01-14
2020-01-14 439
439
Работа генетического алгоритма представляет собой итерационный процесс, который продолжается до тех пор, пока не выполнятся заданное число поколений или какой-либо иной критерий останова. На каждом поколении генетическим алгоритмом реализуется отбор пропорционально приспособленности, кроссовер и мутация.
Схематичное описание функционирования генетического алгоритма (Рисунок 1):
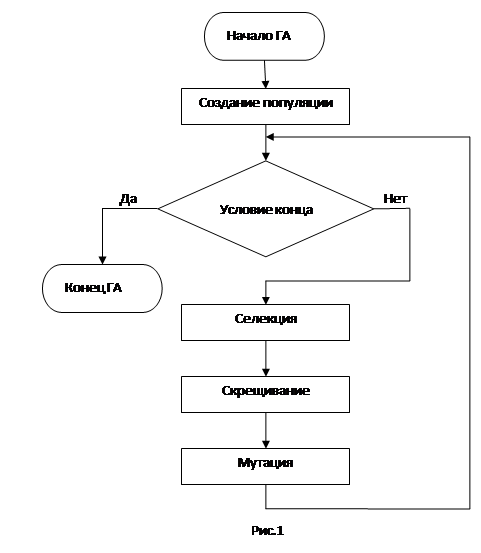
Рисунок 1 Алгоритм работы классического генетического алгоритма
Функционирование генетического алгоритма можно описать следующими шагами:
Инициировать начальный момент времени t=0. Случайным образом сформировать начальную популяцию, состоящую из k-особей.
Вычислить приспособленность каждой особи и популяции в целом. Значение этой функции определяет насколько хорошо подходит особь, описанная данной хромосомой, для решения задачи.
1. Выбрать особь из популяции;
2. С определенной вероятностью (вероятностью кроссовера) выбрать вторую особь из популяции и произвести оператор кроссовера;
3. С определенной вероятностью (вероятностью мутации) выполнить оператор мутации;
4. С определенной вероятностью (вероятностью инверсии) выполнить оператор инверсии;
5. Поместить полученную хромосому в новую популяцию;
6. Выполнить операции, начиная с пункта 3, k-раз;
7. Увеличить номер текущей эпохи t=t+1;
8. Если выполнилось условие остановки, то завершить работу, иначе переход на шаг 2;
Распишем более подробно следующие этапы:
1. Выбор родительской пары:
Первый подход самый простой – это случайный выбор родительской пары, когда обе особи, которые составят родительскую пару, случайным образом выбираются из всей популяции, причем любая особь может стать членом нескольких пар. Несмотря на простоту, такой подход универсален для решения различных классов задач. Однако он достаточно критичен к численности популяции, поскольку эффективность алгоритма, реализующего такой подход, снижается с ростом численности популяции.
Второй способ выбора особей в родительскую пару - так называемый селективный. Его суть состоит в том, что "родителями" могут стать только те особи, значение приспособленности которых не меньше среднего значения приспособленности по популяции, при равной вероятности таких кандидатов составить брачную пару. Такой подход обеспечивает более быструю сходимость алгоритма. Однако из-за быстрой сходимости селективный выбор родительской пары не подходит тогда, когда ставиться задача определения
нескольких экстремумов, поскольку для таких задач алгоритм, как правило, быстро сходится к одному из решений.
Другие два способа формирования родительской пары – инбридинг и аутбридинг. Оба эти метода построены на формировании пары на основе близкого и дальнего "родства" соответственно. Под "родством" здесь понимается расстояние между членами популяции как в смысле геометрического расстояния особей в пространстве параметров. В связи с этим различают генотипный и фенотипный (или географический) инбридинг и аутбридинг. Под инбридингом понимается такой метод, когда первый член пары выбирается случайно, а вторым с большей вероятностью будет максимально близкая к нему особь. Аутбридинг же, наоборот, формирует брачные пары из максимально далеких особей. Использование генетических инбридинга и аутбридинга оказалось более эффективным по сравнению с географическим для всех тестовых функций при различных параметрах алгоритма. Наиболее полезно применение обоих представленных методов для многоэкстремальных задач. Однако два этих способа по-разному влияют на поведение генетического алгоритма. Так инбридинг можно охарактеризовать свойством концентрации поиска в локальных узлах, что фактически приводит к разбиению популяции на отдельные локальные группы вокруг подозрительных на экстремум участков ландшафта, напротив аутбридинг как раз направлен на предупреждение сходимости алгоритма к уже найденным решениям, заставляя алгоритм просматривать новые, неисследованные области. [10]
2. Механизм отбора:
Обсуждение вопроса о влиянии метода создания родительских пар на поведение генетического алгоритма, невозможно вести в отрыве от реализуемого механизма отбора при формировании нового поколения. Наиболее эффективные два механизма отбора элитный и отбор с вытеснением, которые были рассмотрены в предыдущем пункте.
В последние годы, реализовано много генетических алгоритмов и в большинстве случаев они мало похожи на алгоритм, представленный на рис.5. По этой причине в настоящее время под термином "генетические алгоритмы" скрывается не одна модель, а достаточно широкий класс алгоритмов.[2]
Вывод к Главе 1
При рассмотрении общих теоретических аспектов по теме «Генетические алгоритмы», выяснилось, что идея создания алгоритмов, которые могли бы решать разного рода задачи, в том числе и оптимизационные, принадлежит Джону Холланду. В 1975 году им был предложен первый генетический алгоритм. Холланд занимался разработкой алгоритмов, которые могли бы использовать механизмы естественного отбора при решении задач.
В общих чертах работу генетического алгоритма можно описать так: он создает популяцию особей, каждая из которых является решением задачи, а затем эти особи эволюционируют по принципу «выживает сильнейший», то есть остаются лишь самые оптимальные решения. Каждую особь описывает хромосома, хромосома состоит из генов, которые располагаются в определенных позициях хромосомы, т.е. вся наследственная информация, или генотип, хранится в хромосомах.
Работа генетического алгоритма имитирует естественную жизнь, только сильно упрощенную.
Генетические алгоритмы создавались как еще один метод решения задач, альтернативный уже существующим. Чаще всего генетические алгоритмы используют для решения оптимизационных задач, особенно, если традиционными способами эти задачи решить очень трудно, практически невозможно. В следующей главе будут рассмотрены оптимизационные задачи и то, каким образом их можно решить с помощью генетического алгоритма.








