 2014-02-02
2014-02-02 3564
3564Сначала стали использовать иерархические даталогические модели. Простота
организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности.
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом, как на новую технологию БД, так и на новую технику.
ИМ - Модель организации данных, представляющая собой древовидный граф, состоящий из ряда типов записей (типов данных) и. связей между ними (отношений иди характеристик отношений), причем один из типов записей определяется, как корневой или входной, а остальные связаны с ним или друг с другом отношениями "один-ко-многим" или (реже) "один-к-одному". При этом запись, идентифицируемая элементом "один", рассматривается как исходная, а соответствующая элементу "много" - как порожденная. Каждая запись может быть порожденной только в одной связи, следовательно, ей соответствует только одна исходная запись. Однако каждая запись может' быть исходной во многих связях. Корневая запись может быть только исходной.
Пример иерархической модели приведен на рис. 1.
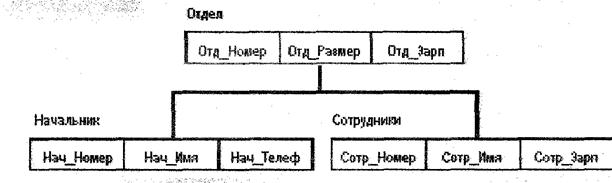
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи. Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Общая схема иерархической модели БД:
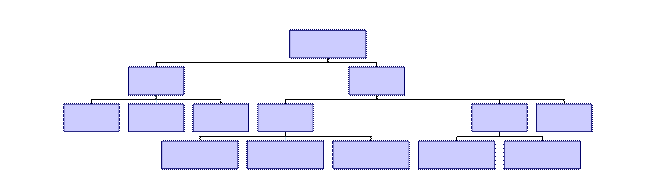
В иерархической модели структура информации имеет форму дерева. На самом верхнем (первом) уровне находится только одна вершина, которая называется корнем. Эта вершина имеет связи с вершинами второго уровня, вершины второго уровня имеют связи только с вершинами третьего уровня и т.д.
Учебный вопрос №6. Сетевая модель (структура) данных
Типичным представителем является Integrated Database Management System (IDMS) компании Cutlinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task. Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages' (CODASYL), организации, ответственной за определение языка программирования Ко-бол. Отчет DBTG был опубликован в 1971 г., а в 70-х годах появилось несколько систем, среди которых IDMS.
СМ - модель организации данных, подобная иерархической, но отличающаяся от нее тем, что каждая запись может вступать в любое количество поименованных связей с другими записями и как исходная, и как порожденная, или как то и другое.
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; к сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей и набора, связей между этими записями Пример сетевой модели приведен на рис. 2.
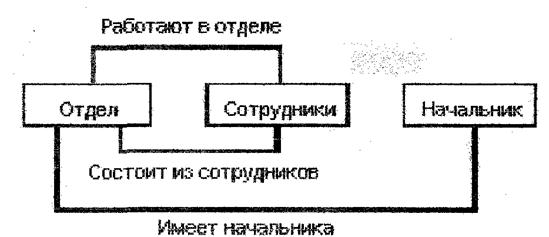
Общая схема сетевой модели:
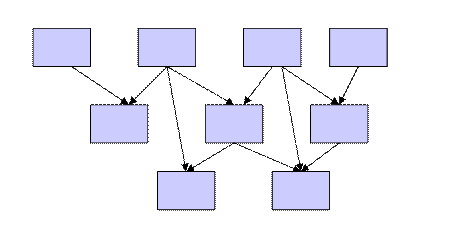
n В сетевой модели основная структура представления информации имеет форму сети, в которой каждая вершина может иметь связь с любой другой.
Недостатки ИМ и СМ:
Слишком сложно пользоваться;
Фактически необходимы знания о физической организации;
Прикладные системы зависят от этой организации;
Их логика перегружена деталями, организации доступа к БД.
Учебный вопрос №7. Реляционная модель (структура) данных.
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных моделей данных, т.е. возможности использования привычных и естественных способов представления данных.
Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э.Кодда (Codd E.F., A Relational Model of Data for Large Shared Data Banks. CACM 13:6, June 1970), где, вероятно, впервые был применен термин "реляционная модель данных".
Будучи математиком по образованию Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение - relation-
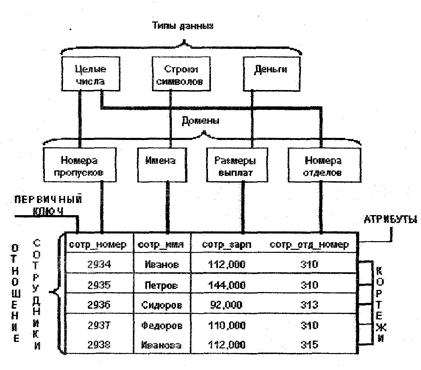
Отношения включают атрибуты и кортежи, составляющие соответственно столбцы и строки: таблицы. Количество атрибутов в отношении соответствует количеству содержащихся в нем элементов данных, количество кортежей - числу экземпляров (реализаций) записей. Порядок следования атрибутов и кортежей может быть произвольным. Значения атрибутов определяются из доменов. Наличие доменов обеспечивает связи между разными отношениями.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации.
Наименьшая единица данных реляционной модели - это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой - как три различных значения.
Отношение - таблица реляционной модели данных. Доменом называется множество атомарных значений одного и того же типа.
Атрибут - в реляционных моделях баз данных - столбец отношения (таблицы), содержащий реализации записей одного типа данных.
Кортеж - В реляционных моделях баз данных - строка отношения (таблицы), содержащая реализацию записей взаимосвязанных значений атрибутов.
Сущность - То же, что тип объекта: обобщенное наименование множества однотипных объектов, называемых экземплярами.
Каждый экземпляр обладает набором свойств (атрибутов), отличающих его от всех остальных. Примеры сущности: автомобиль, самолет, врач и т. д. Примеры экземпляров: автомобиль ВАЗ-2106, самолет ТУ-104, врач. Петров Иван Федорович и т. д.
 |
Учебный вопрос №8. Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной, интервал).
Ключ или возможный ключ - это минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Каждая сущность обладает хотя бы одним возможным ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать предпочтение несоставным ключам или ключам, составленным из минимального числа атрибутов- Нецелесообразно также использовать ключи с длинными текстовыми значениями (предпочтительнее использовать целочисленные атрибуты). Не допускается, чтобы первичный ключ стержневой сущности (любой атрибут, участвующий в первичном ключе) принимал неопределенное значение. Иначе возникнет противоречивая ситуация: появится не обладающий, индивидуальностью, и, следовательно не существующий экземпляр стержневой сущности. По тем же причинам необходимо обеспечить уникальность первичного ключа.
Потенциально в реляционной модели может быть организовано очень большое количество связей между данными, значительная часть которых является избыточными (неиспользуемыми). Поэтому разработаны формы (варианты) нормализации отношений: первая (1НФ), вторая (2НФ), третья (ЗНФ) и четвертая (4НФ).
Краткое изложение темы:
1. База данных — организованная совокупность блоков информационных элементов, представленных, на машиночитаемых носителях предназначенных и пригодных для решения различных задач с использованием средств вычислительной техники.
СУБД — программа, с помощью которой реализуется централизованное управление данными, хранимыми в базе, а также доступ к ним, поддержка их в актуальном режиме.
Характеристиками СУБД являются:
· производительность;
· обеспечение целостности данных на уровне баз данных;
· обеспечение безопасности данных;
· возможность работы в многопользовательских средах;
· возможность импорта и экспорта данных;
· возможность составления запросов;
· наличие инструментальных средств разработки прикладных программ.
Безопасность данных достигается: шифрованием прикладных программ; шифрованием данных; защитой данных паролем; ограничением доступа к базе данных.
Обеспечение целостности данных подразумевает наличие средств, позволяющих удостовериться, что информация в базе данных всегда остается корректной и полной. Целостность данных должна обеспечиваться независимо от того, каким образом данные заносятся в память (в интерактивном режиме, посредством импорта или с помощью специальной программы).
Система управления базами данных управляет данными во внешней памяти. Обеспечивает надежное хранение данных и поддержку соответствующих языков базы данных. Важной функцией СУБД является функция управления буферами оперативной памяти.
Известны три типа баз данных:
· иерархическая;
· сетевая;
· реляционная.
Основное различие между ними состоит в характере описания взаимосвязей и взаимодействия между объектами и атрибутами базы данных.
Иерархическая модель предполагает использование для описания базы данных древовидных структур, состоящих из определенного числа уровней. "Дерево" представляет собой иерархию элементов, называемых узлами. Под элементами понимаются список, совокупность, набор атрибутов, элементов, описывающих объекты.
Сетевая модель описывает элементарные данные и отношения между ними в виде ориентированной сети. Это такие отношения между объектами, когда каждый порожденный элемент имеет более одного исходного и может быть связан с любым другим элементом структуры.
Реляционная модель имеет в своей основе понятие "отношения" и ее данные формируются в виде таблиц. Отношение — это двумерная таблица, имеющая свое название, в которой минимальным объектом действий, сохраняющим ее структуру, является строка таблицы (кортеж), состоящая из ячеек таблицы — полей. Каждый столбец таблицы соответствует только одному компоненту этого отношения. С логической точки зрения реляционная база данных представляется множеством двумерных таблиц различного предметного наполнения.
Справочно-правовые системы как разновидность информационных систем
Всю документированную правовую информацию можно разделить на официальную и неофициальную. К официальной правовой информации относятся сведения и данные о праве или законодательстве в широком смысле слова, то есть обо всех действующих и уже прекративших действие нормативных актах. В автоматизированных системах, основанных на официальной правовой информации, большую роль играет ее классификация по источникам права: законы РФ, нормативные акты правительства страны, министерств и ведомств страны и республик и местных органов государственной власти и государственного управления, общественных организаций и т.п.
В качестве неофициальной правовой информации, лежащей в основе функционирования автоматизированных систем правовой информации (АСПИ), рассматриваются все сведения и данные о праве и связанных с ним явлениях, которые отражены в юридической научной литературе, не являющейся официальной (юридических монографиях, учебниках, статьях, обзорах, докладах, справочниках и др. материалах), и сведения, содержащиеся в материалах, полученных от предприятий, учреждений, общественных организаций, граждан и др. источников.
ВАЖНО: Информация, полученная в результате работы автоматизированной системы, хранящей и обрабатывающей официальную информацию, не будет являться официальной. Исключение составляет система «Собрание законодательства РФ», разработанная Центром новых компьютерных технологий научно-технического центра Федерального агентства правительственной связи и информации при Президенте РФ (ФАПСИ). Тексты правовых актов в машиночитаемом виде в этой системе являются официальными.
Большое значение, с точки зрения создания и функционирования автоматизированных информационных систем (АИС), имеет классификация информации по степени доступа на открытую и ограниченного доступа. Использование подобного рода информации в автоматизированных системах требует организации технической и программной защиты ее от несанкционированного доступа.
Существуют классификации АСПИ по виду используемых технических (на каком классе вычислительных машин функционируют), программных (под управлением какой операционной системы работают, с помощью каких программных средств созданы), лингвистических средств, а также логико-математических методов, лежащих в основе процесса обработки информации. Кроме того, автоматизированные системы правовой информации можно классифицировать по требованию к уровню подготовки пользователей (для специалистов, для широкого круга пользователей).
Опыт практического применения АИС показал, что наиболее точной, соответствующей самому назначению АИС следует считать классификацию по степени сложности технической, вычислительной, аналитической и логической обработки используемой информации. При таком подходе к классификации можно наиболее тесно связать АИС и соответствующие информационные технологии.
Соответственно, можно выделить следующие виды АИС:
– автоматизированные системы обработки данных (АСОД);
– автоматизированные информационно-поисковые системы (АИПС);
– автоматизированные информационно-справочные системы (АИСС);
– автоматизированные информационно-логические системы (АИЛС);
– автоматизированные рабочие места (АРМ);
– автоматизированные системы управления (АСУ);
– автоматизированные системы информационного обеспечения (АСИО);
– экспертные системы и системы поддержки принятия решений.
Рассмотрим эти типы АИС подробнее.
Автоматизированные системы обработки данных (АСОД) предназначены для решения хорошо структурированных задач, по которым имеются входные данные, известны алгоритмы и стандартные процедуры обработки. АСОД применяют в целях автоматизации повторяющихся рутинных операций управленческого труда персонала невысокой квалификации. Как самостоятельные информационные системы АСОД в настоящее время практически не используются, но, вместе с тем, они являются обязательными элементами большинства сложных информационных систем, таких, как АИСС, АРМ, АСУ. В частности, ОВД АСОД используются для статистической обработки информации по заданным формам отчетности.
Под автоматизированной информационно-поисковой системой (АИПС) в области права будем понимать автоматизированную информационно-правовую систему, предназначенную для сбора, систематизации, хранения и поиска правовой информации по запросам пользователей.
Наиболее известными системами, относящимися к данному виду, являются: ИПС «Эталонный банк правовой информации», созданная Государственным правовым управлением Президента РФ; база данных по законодательству «Эталон», разработанная научным центром правовой информации; система Центра новых компьютерных технологий научно-технического центра ФАПСИ «Собрание законодательства РФ»; юридическая справочная информационная система АРМ-юрист агентства «Intralex»; справочная правовая система «Гарант», разработанная научно-производственным объединением «Гарант-Сервис» (МГУ); информационно-правовая система «Кодекс», созданная в «Центре компьютерных разработок» (Санкт-Петербург); справочно-правовые системы «КонсультантПлюс», созданные АО «КонсультантПлюс» и др.
АИПС используются для накопления и постоянного корректирования больших массивов информации о лицах, фактах и предметах, представляющих интерес. Эти системы работают преимущественно по принципу «запрос-ответ», поэтому обработка информации в них связана в основном не с преобразованием первичных данных, а с их поиском.

