 2014-02-02
2014-02-02 885
885Одно из важнейших свойств нейронной сети – это способность к обобщению полученных знаний. Сеть, обученная на некотором множестве входных векторов, генерирует ожидаемые результаты при подаче на ее вход тестовых данных, относящихся к тому же множеству, но не участвовавших непосредственно в процессе обучения. В составе обучающих данных можно выделить определенное подмножество контрольных данных, используемых для определения точности обучения сети. В то же время, в составе обучающих данных не должно быть уникальных данных, свойства которых отличаются от ожидаемых значений. Способность сети распознавать данные из тестового подмножества характеризует ее возможности обобщения знаний.
Имеет место компромисс между точностью и обобщающей способностью сети, который можно оптимизировать посредством выбора количества скрытых нейронов для данной сети. Количество скрытых нейронов, с одной стороны, должно быть достаточным для того чтобы решить поставленную задачу, а с другой - не должно быть слишком большим, чтобы обеспечить необходимую обобщающую способность.
Не существует простого способа для определения необходимого числа скрытых элементов сети. Ряд противоречивых требований накладывается на количество весовых коэффициентов сети.
Во-первых, необходимо иметь достаточное число данных для обучения сети с выбранным числом весовых коэффициентов. Если бы целью обучения было только запоминание обучающих выборок, то их число могло быть равным числу весов. Однако такая сеть не будет обладать свойством обобщения, и сможет только восстанавливать данные. Число весов частично обусловлено числом входных и выходных элементов и, следовательно, методом кодировки входных и выходных данных.
Во-вторых, сеть должна обучаться на избыточном множестве данных, чтобы обладать свойством обобщения. При этом веса будут адаптироваться не к отдельным выборкам, а к их статистически усредненным совокупностям.
Обучение сети ведется путем минимизации целевой функции E(w), определяемой только на подмножестве обучающих данных, что обеспечивает достаточное соответствие выходных сигналов сети ожидаемым значениям из обучающей выборки.
Истинная цель обучения состоит в таком подборе архитектуры и параметров сети, которые обеспечат минимальную погрешность распознавания тестового подмножества данных, не участвовавших в обучении. Критерием правильности окончательных результатов является погрешность обобщения, вычисленная по тестовой выборке.
Со статистической точки зрения погрешность обобщения E зависит от уровня погрешности обучения H и от доверительного интервала и характеризуется отношением (3.55)[5].
 (3.55)
(3.55)
где 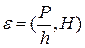 – доверительный интервал,
– доверительный интервал,  – объем обучающей выборки,
– объем обучающей выборки, 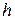 – мера Вапника-Червоненкиса.
– мера Вапника-Червоненкиса.
Мера Вапника-Червоненкиса (VC-измерение) отражает уровень сложности сети и тесно связана с количеством содержащихся в ней весов. Чем больше число различных весов, тем больше сложность сети и соответственно значение VC-измерения. Метод точного определения этой меры неизвестен, но можно определить верхнюю и нижнюю границу этой меры в виде формулы (3.56).
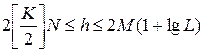 (3.56)
(3.56)
где 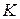 – количество нейронов в скрытом слое,
– количество нейронов в скрытом слое, 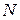 – размерность входного вектора,
– размерность входного вектора, 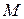 – общее количество весов сети,
– общее количество весов сети, 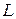 – общее количество нейронов в сети.
– общее количество нейронов в сети.
Из формулы (3.56) следует, что нижняя граница диапазона приблизительно равна числу весов, связывающих входной и выходной слои, тогда как верхняя граница превышает двукратное суммарное число всех весов сети. В качестве приближенного значения VC–измерения может быть использовано общее число весов нейронной сети.
Таким образом, на погрешность обобщения оказывает влияние отношение количества обучающих выборок к количеству весов сети. Небольшой объем обучающего подмножества при фиксированном количестве весов вызывает хорошую адаптацию сети к его элементам, однако не усиливает способности к обобщению, так как в процессе обучения наблюдается относительное превышение числа подбираемых параметров над количеством пар фактических и ожидаемых выходных сигналов сети. Эти параметры адаптируются с чрезмерной и неконтролируемой точностью к значениям конкретных выборок, а не к диапазонам, которые эти выборки должны представлять. Фактически задача аппроксимации подменяется в этом случае задачей приближенной интерполяции. В результате всякого рода нерегулярности обучающих данных и шумы могут восприниматься как существенные свойства процесса.
На основе опытных данных существуют следующие рекомендации по выбору числа скрытых нейронов:
1. Не следует выбирать число скрытых нейронов больше, чем удвоенное число входных элементов.
2. Число обучающих данных должно быть по крайней мере в 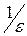 раз больше количества весов в сети, где
раз больше количества весов в сети, где 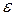 - граница ошибки обучения.
- граница ошибки обучения.
3. Следует выявить особенности нейросети, так как в этом случае требуется меньшее количество скрытых нейронов, чем входов. Если есть сведения, что размерность данных может быть уменьшена, то следует использовать меньшее количество скрытых нейронов.
4. При обучении на бесструктурных входах необходимо, чтобы количество скрытых нейронов было больше, чем количество входов. Если набор данных не имеет общих свойств, необходимо использовать больше скрытых нейронов.
5. Имеет место взаимоисключающая связь между обобщающими свойствами (меньше нейронов) и точностью (больше нейронов), которая специфична для каждого приложения.
6. Большая сеть требует большего времени для обучения.
Существуют также практические рекомендации по модификации алгоритмов конструирования сети:
1. Если ошибка обучения мала, а ошибка тестирования велика, следовательно, сеть содержит слишком много весовых коэффициентов.
2. Если и ошибка обучения, и ошибка тестирования велики, следовательно, весовых коэффициентов слишком мало.
3. Если все весовые коэффициенты очень большие, следовательно, весовых коэффициентов слишком мало.
4. Добавление весов не панацея; если известно, что весовых коэффициентов достаточно, следует подумать о других причинах ошибок, например о недостаточном количестве обучающих данных.
5. Не следует добавлять слишком много весовых коэффициентов, чтобы не переступить пределов, установленных ранее.
6. И, наконец, что очень важно, начальные весовые коэффициенты должны быть случайными и небольшими по величине (например, между +1 и –1).








