 2014-02-09
2014-02-09 448
448Группа текстологических методов объединяет методы извлечения знаний, основанные на изучении специальных текстов из учебников, монографий, статей, методик и других носителей профессиональных знаний.
Задачу извлечения знаний из текстов можно сформулировать как задачу понимания и выделения смысла текста. Сам текст на естественном языке является лишь проводником смысла, а замысел и знания автора лежат во вторичной структуре (смысловой структуре или макроструктуре текста), настраиваемой над естественным текстом.
При этом можно выделить две смысловые структуры:
М1 — смысл, который пытался заложить автор, это его модель мира, и М2 — смысл, который постигает читатель, в данном случае инженер по знаниям (рис. 14.4), в процессе интерпретации I. При этом Т — это словесное одеяние М1, то есть результат вербализации V.
Сложность процесса заключается в принципиальной невозможности совпадения знаний, образующих М1 и М2, из-за того что М1 образуется за счет всей совокупности представлений, потребностей, интересов и опыта автора лишь малая часть которых находит отражение в тексте Т. Соответственно, и М2 образуется в процессе интерпретации текста Т за счет привлечения всей совокупности научного и человеческого багажа читателя. Таким образом, два инженера по знаниям извлекут из одного Т две различные модели Мi1 и Мi1.
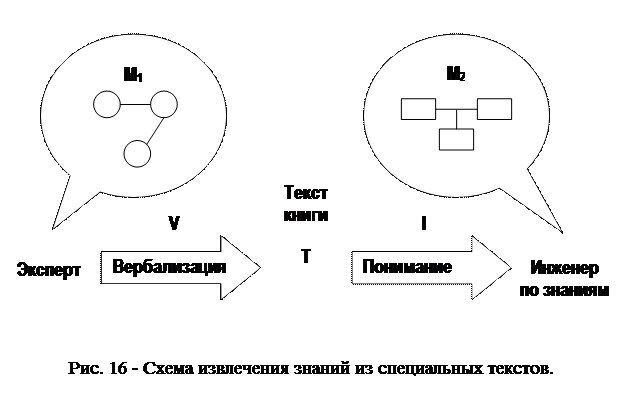
Встает задача: выяснить, за счет чего можно достичь максимальной адекватности М1 и М2, помня при этом, что понимание всегда относительно, поскольку это синтез двух смыслов «свое–чужое» [Бахтин, 1975].
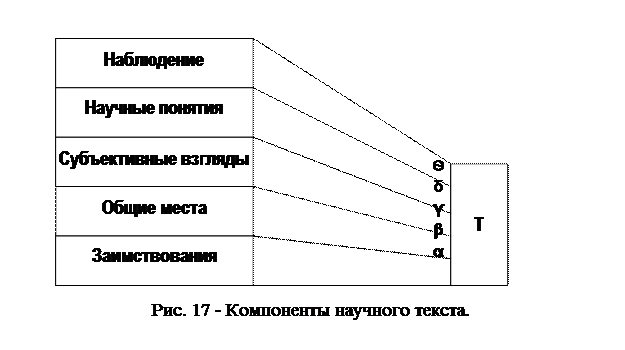
Рассмотрим подробнее, какие источники питают модель М1 и создают текст Т. В работе [Сергеев, 1987] указаны два компонента любого научного текста. Это первичный материал наблюдений α и система научных понятий β в момент создания текста. В дополнение к этому, на наш взгляд, помимо объективных данных экспериментов и наблюдений, в тексте обязательно присутствуют субъективные взгляды автора γ, результат его личного опыта, а также некоторые «общие места» или «вода» δ. Кроме этого, любой научный текст содержит заимствования из других источников (статей, монографий) и т. д. При этом все компоненты погружены в языковую среду L. Можно записать:
Т = (α, β, γ, δ, Ѳ)L.
Таким образом, компоненты научного текста можно представить в виде следующей схемы (рис. 59). При этом компоненты β, γ, часть α входят и в модель М1.
При извлечении знаний аналитику, интерпретирующему текст, приходится решать задачу декомпозиции этого текста на перечисленные выше компоненты для выделения истинно значимых для реализации базы знаний фрагментов. Сложность интерпретации научных и специальных текстов заключается еще и в том, что любой текст приобретает смысл только в контексте, где под контекстом понимается окружение, в которое «погружен» текст.
Основными моментами понимания текста являются:
1) Выдвижение предварительной гипотезы о смысле всего текста (предугадывание).
2) Определение значений непонятных слов (то есть специальной терминологии).
3) Возникновение общей гипотезы о содержании текста (о знаниях).
4) Уточнение значения терминов и интерпретация отдельных фрагментов текста под влиянием общей гипотезы (от целого к частям).
5) Формирование некоторой смысловой структуры текста за счет установления внутренних связей между отдельными важными (ключевыми словами и фрагментами, а также за счет образования абстрактных понятий, обобщающих конкретные фрагменты знаний.
6) Корректировка общей гипотезы относительно содержащихся в тексте фрагментов знаний (от частей к целому).
7) Принятие основной гипотезы, то есть формирование М2.
На процесс понимания (или интерпретации) I и модель М2 влияют следующие компоненты (рис. 18):
· экстракт компонентов (α, β, γ, Ѳ)’, почерпнутый из текста Т;
· предварительные знания аналитика о предметной области ω;
· общенаучная эрудиция аналитика ε;
· его личный опыт ϕ.
М2 = [(α, β, γ, Ѳ)’, ω, ε, ϕ].

Предложим одну из возможных практических методику анализа текстов с целью извлечения и структурирования знаний.
| Алгоритм извлечения знаний из текста 1. Составление «базового» списка литературы для ознакомления с предметной областью и чтение по списку. 2. Выбор текста для извлечения знаний. 3. Первое знакомство с текстом (беглое прочтение). Для определения значения незнакомых слов — консультации со специалистами или привлечение справочной литературы. 4. Формирование первой гипотезы о макроструктуре текста. 5. Внимательное прочтение текста с выписыванием ключевых слов и выражений, то есть выделение «смысловых вех» (компрессия текста). 6. Определение связей между ключевыми словами, разработка макроструктуры текста в форме графа или «сжатого» текста (реферата). 7. Формирование поля знаний на основании макроструктуры текста. |








