 2014-02-12
2014-02-12 2362
2362Оперативные, как правило, используют режим реального масштаба времени. Этот режим характеризуется жесткими ограничениями на время решения задач в системе и предполагает высокую степень автоматизации процедур ввода-вывода и обработки данных.
Наибольший интерес у исследователей всех рангов (проектировщиков, аналитиков и пользователей) вызывают структурные признаки ВС. От того, насколько структура ВС соответствует структуре решаемых на этой системе задач, зависит эффективность применения ЭВМ в целом. Структурные признаки, в свою очередь, отличаются многообразием: топология управляющих и информационных связей между элементами системы, способность системы к перестройке и перераспределению функций, иерархия уровней взаимодействия элементов. В наибольшей степени структурные характеристики определяются архитектурой системы.
Многомашинные ВС. Режимы работы. Отличия от многопроцессорных ВС
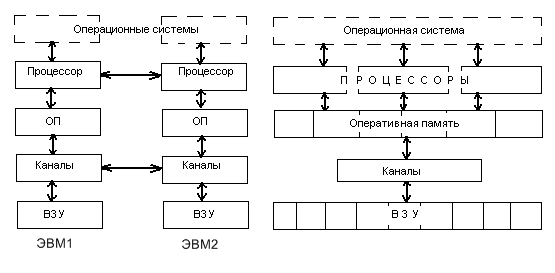
Многомашинные и многопроцессорные ВС
Многомашинные ВС используются для повышения производительности, надежности и достоверности вычислений. Исторически они появились перед многопроцессорными.
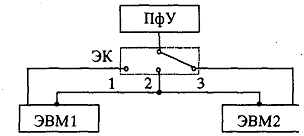
Положения 1 и 3 электронного ключа (ЭК) обеспечивали режим повышенной надежности. При этом одна из машин выполняла вычисления, а другая находилась в «горячем» или «холодном» резерве, т.е. в готовности заменить основную ЭВМ. Положение 2 электронного ключа соответствовало случаю, когда обе машины обеспечивали параллельный режим вычислений. Здесь возможны две ситуации:
а) обе машины решают одну и ту же задачу и периодически сверяют результаты решения. Тем самым обеспечивался режим повышенной достоверности, уменьшалась вероятность появления ошибок в результатах вычислений. Примерно по такой же схеме построены управляющие бортовые вычислительные комплексы космических аппаратов, ракет, кораблей. Например, американская космическая система «Шатл» содержала пять вычислительных машин, работающих по такой схеме;
б) обе машины работают параллельно, но обрабатывают собственные потоки заданий. Возможность обмена информацией между машинами сохраняется. Этот вид работы относится к режиму повышенной производительности. Она широко используется в практике организации работ на крупных вычислительных центрах, оснащенных несколькими ЭВМ высокой производительности.
Схема, представленная выше, была неоднократно повторена в различных модификациях при проектировании разнообразных специализированных ММС. Основные различия ММС заключаются, как правило, в организации связи и обмена информацией между ЭВМ комплекса. Каждая из них сохраняет возможность автономной работы и управляется собственной ОС. Любая другая подключаемая ЭВМ комплекса рассматривается как специальное периферийное оборудование. В зависимости от территориальной разобщенности ЭВМ и используемых средств сопряжения обеспечивается различная оперативность их информационного взаимодействия.
В создаваемых ВС стараются обеспечить несколько путей передачи данных, что позволяет достичь необходимой надежности функционирования, гибкости и адаптируемости к конкретным условиям работы. Эффективность обмена информацией определяется скоростью передачи и возможными объемами данных, передаваемыми по каналу взаимодействия. Эти характеристики зависят от средств, обеспечивающих взаимодействие модулей и уровня управления процессами, на котором это взаимодействие осуществляется. Сочетание различных уровней и методов обмена данными между модулями ВС в наиболее полной форме нашло свое выражение в универсальных суперЭВМ и больших ЭВМ, в которых сбалансировано использовались все методы достижения высокой производительности.
Многопроцессорные системы (МПС) строятся при комплексировании нескольких процессоров. В качестве общего ресурса они имеют общую оперативную память (ООП). Параллельная работа процессоров и использование ООП обеспечивается под управлением единой операционной системы. По сравнению с ММС здесь достигается наивысшая оперативность взаимодействия вычислителей процессоров. Многие исследователи считают, что использование МПС является основным магистральным путем развития вычислительной техники новых поколений.
Однако МПС имеет и существенные недостатки. Они в первую очередь связаны с использованием ресурсов общей оперативной памяти. При большом количестве комплексируемых процессоров возможно возникновение конфликтных ситуаций, когда несколько процессоров обращаются с операциями типа «чтение» и «запись» к одним и тем же областям памяти. Помимо процессоров к ООП подключаются все каналы (процессоры ввода-вывода), средства измерения времени и т.д. Поэтому вторым серьезным недостатком МПС является проблема коммутации абонентов и доступа их к ООП. От того, насколько удачно решаются эти проблемы, и зависит эффективность применения МПС. Это решение обеспечивается аппаратно-программными средствами. Процедуры взаимодействия очень сильно усложняют структуру ОС МПС.
Накопленный опыт построения подобных систем показал, что они эффективны при небольшом числе комплексируемых процессоров (от 2—4 до 10). В отечественных системах «Эльбрус» обеспечивалась возможность работы до 10 процессоров, до 32 модулей памяти, до 4 процессоров ввода-вывода и до 16 процессоров связи.
Создание подобных коммутаторов представляет сложную техническую задачу, тем более, что они должны быть дополнены буферами для организации очередей запросов. Для разрешения конфликтных ситуаций необходимы схемы приоритетного обслуживания. До настоящего времени в номенклатуре технических средств ЭВТ отсутствуют высокоэффективные коммутаторы общей памяти.
Уровни комплексирования в ВС
Для построения вычислительных систем необходимо, чтобы элементы или модули, комплексируемые в систему, были совместимы.
Понятие совместимости имеет три аспекта: аппаратный, или технический, программный и информационный. Техническая (Hardware) совместимость предполагает, что еще в процессе разработки аппаратуры обеспечиваются следующие условия:
1. подключаемая друг к другу аппаратура должна иметь единые стандартные, унифицированные средства соединения: кабели, число проводов в них, единое назначение проводов, разъемы, заглушки, адаптеры, платы и т.д.;
2. параметры электрических сигналов, которыми обмениваются технические устройства, тоже должны соответствовать друг другу: амплитуды импульсов, полярность, длительность и т.д.;
3. алгоритмы взаимодействия (последовательности сигналов по отдельным проводам) не должны вступать в противоречие друг с другом.
Последний пункт тесно связан с программной совместимостью. Программная совместимость (Software) требует, чтобы программы, передаваемые из одного технического средства в другое (между ЭВМ, процессорами, между процессорами и внешними устройствами), были правильно поняты и выполнены другим устройством.
Если обменивающиеся устройства идентичны друг, другу, то проблем обычно не возникает. Если взаимодействующие устройства относятся к одному и тому же семейству ЭВМ, но стыкуются разные модели (например, ПК на базе i286 и Pentium), то в таких моделях совместимость обеспечивается «снизу вверх», т.е. ранее созданные программы могут выполняться на более поздних моделях, но не наоборот. Если стыкуемая аппаратура имеет совершенно разную систему команд, то следует обмениваться исходными модулями программ с последующей их трансляцией.
Информационная совместимость комплексируемых средств предполагает, что передаваемые информационные массивы будут одинаково интерпретироваться стыкуемыми модулями ВС. Должны быть стандартизированы алфавиты, разрядность, форматы, структура и разметка файлов, томов и т.д.
В создаваемых ВС стараются обеспечить несколько путей передачи данных, что позволяет достичь необходимой надежности функционирования, гибкости и адаптируемости к конкретным условиям работы. Эффективность обмена информацией определяется скоростью передачи и возможными объемами данных, передаваемыми по каналу взаимодействия. Эти характеристики зависят от средств, обеспечивающих взаимодействие модулей и уровня управления процессами, на котором это взаимодействие осуществляется. Сочетание различных уровней и методов обмена данными между модулями ВС в наиболее полной форме нашло свое выражение в универсальных суперЭВМ и больших ЭВМ, в которых сбалансировано использовались все методы достижения высокой производительности.
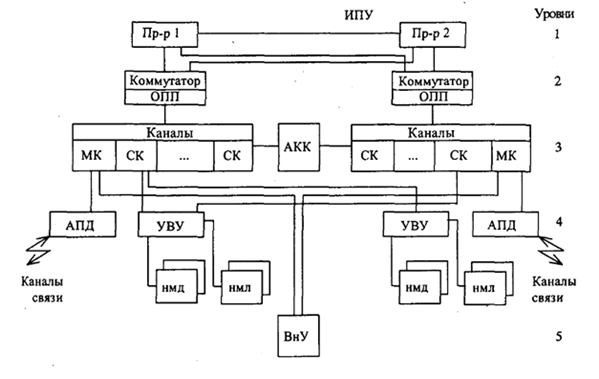
Уровни и средства комплексирования
В этих машинах предусматривались следующие уровни мультиплексирования:
1. прямого управления (процессор — процессор);
2. общей оперативной памяти;
3. комплексируемых каналов ввода-вывода;
4. устройств управления внешними устройствами (УВУ);
5. общих внешних устройств.
На каждом из этих уровней используются специальные технические и программные средства, обеспечивающие обмен информацией.
Уровень прямого управления служит для передачи коротких однобайтовых приказов-сообщений. Последовательность взаимодействия процессоров сводится к следующему. Процессор-инициатор обмена по интерфейсу прямого управления (ИПУ) передает в блок прямого управления байт-сообщение и подает команду «Прямая запись». У другого процессора эта команда вызывает прерывание, относящееся к классу внешних. В ответ он вырабатывает команду «прямое чтение» и записывает передаваемый байт в свою память. Затем принятая информация расшифровывается и по ней принимается решение.
После завершения передачи прерывания снимаются, и оба процессора продолжают вычисления по собственным программам. Видно, что уровень прямого управления не может использоваться для передачи больших массивов данных, однако оперативное взаимодействие отдельными сигналами широко используется в управлении вычисления ми. У ПЭВМ типа IBM PC этому уровню соответствует.комплексирование процессоров, подключаемых к системной шине.
Уровень общей оперативной памяти (ООП) является наиболее предпочтительным для оперативного взаимодействия процессоров. Однако в этом случае ООП эффективно работает только при небольшом числе обслуживаемых абонентов. Этот уровень широко используется в многопроцессорных серверах вычислительных сетей.
Уровень комплексируемых каналов ввода-вывода предназначается для передачи больших объектов информации между блоками оперативной памяти, сопрягаемых ЭВМ. Обмен данными между ЭВМ осуществляется с помощью адаптера «канал-канал» (АКК) и команд «Чтение» и «Запись».
Адаптер — это устройство, согласующее скорости работы сопрягаемых каналов. Обычно сопрягаются селекторные каналы (СК) машин как наиболее быстродействующие, но можно сопрягать мультиплексные каналы (МК), а также селекторный и мультиплексный. Скорость обмена данными определяется скоростью самого медленного канала. Скорость передачи данных по этому уровню составляет несколько Мбайтов/с. В ПЭВМ данному уровню взаимодействия соответствует подключение периферийной аппаратуры через контроллеры и адаптеры.
Уровень устройств управления внешними устройствами предполагает использование встроенного в УВУ двухканального переключателя и команд «Зарезервировать» и «Освободить». Двухканальный переключатель позволяет подключать УВУ одной машины к селекторным каналам различных ЭВМ. По команде «Зарезервировать» канал-инициатор обмена имеет доступ через УВУ к любым накопителям на дисках НМД или на магнитных лентах НМЛ.
Пятый уровень предполагает использование общих внешних устройств. Для подключения отдельных устройств используется автономный двухканальный переключатель.
Пять уровней комплексирования получили название логических потому, что они объединяют на каждом уровне разнотипную аппаратуру, имеющую сходные методы управления. Каждое из устройств может иметь логическое имя, используемое в прикладных программах. Этим достигается независимость программ пользователей от конкретной физической конфигурации системы. Связь логической структуры программы и конкретной физической структуры ВС обеспечивается операционной системой по указаниям-директивам пользователя, при генерации ОС и по указаниям диспетчера-оператора вычислительного центра. Различные уровни комплексирования позволяют создавать самые различные структуры ВС.
Второй логический уровень позволяет создавать многопроцессорные ВС. Обычно он дополняется и первым уровнем, что повышает оперативность взаимодействия процессоров. Вычислительные системы сверхвысокой производительности должны строиться как многопроцессорные.
Центральным блоком такой системы является быстродействующий коммутатор, обеспечивающий необходимые подключения абонентов (процессоров и каналов) к общей оперативной памяти.
Уровни 1, 3, 4, 5 обеспечивают построение разнообразных машинных комплексов. Особенно часто используется третий в комбинации с четвертым. Целесообразно их дополнять и первым уровнем.
Пятый уровень комплексирования используется в редких специальных случаях, когда в качестве внешнего объекта используется какое-то дорогое уникальное устройство. В противном случае этот уровень малоэффективен. Любое внешнее устройство — это недостаточно надежное устройство точной механики, а значит, выгоднее использовать четвертый уровень комплексирования, когда можно сразу управлять не одним, а несколькими внешними устройствами, включая и резервные.
Сочетание уровней и методов взаимодействия позволяет создавать самые различные многомашинные и многопроцессорные системы.
Ларионов, А. Вычислительные комплексы, системы и сети / А. М. Ларионов, С. А. Майоров, Г. И. Новиков. - Энергоатомиздат, 1987. - 288 с.
Хорошевский, В. Архитектура вычислительных систем / В.Г. Хорошевский. Москва: МГТУ им. Баумана, 2008. - 520 с.
Цилькер, Б. Организация ЭВМ и систем / Б.Я. Цилькер, С.А. Орлов. СПб.: Питер - 2007, 672 c.
Лекция 7. Классификация вычислительных систем. Параллельные алгоритмы
Классификация Флинна архитектур
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD = Single Instruction Single Data
MISD = Multiple Instruction Single Data
SIMD = Single Instruction Multiple Data
MIMD = Multiple Instruction Multiple Data
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи. Большое разнообразие попадающих в данный класс систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс.
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP,BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по мнению некоторых исследователей в области классификации архитектур, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Основные классы ВС
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
Можно привести следующую классификацию архитектур параллельных ВС.
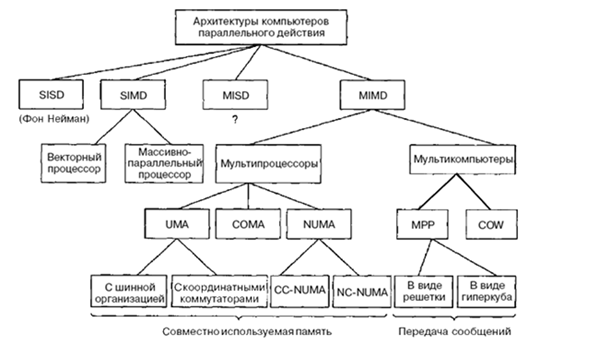
Классы вычислительных систем
Машины SIMD распались на две подгруппы. В первую подгруппу попадают многочисленные суперкомпьютеры и другие машины, которые оперируют векторами, выполняя одну и ту же операцию над каждым элементом вектора. Во вторую подгруппу попадают машины типа ILLIAC IV, в которых главный блок управления посылает команды нескольким независимым АЛУ.
В нашей классификации категория MIMD распалась на мультипроцессоры (машины с памятью совместного использования) и мультикомпьютеры (машины с передачей сообщений). Существует три типа мультипроцессоров. Они отличаются друг от друга по способу реализации памяти совместного использования. Они называются UMA (Uniform Memory Access — архитектура с однородным доступом к памяти), NUMA (NonUniform Memory Access — архитектура с неоднородным доступом к памяти) и СОМА (Cache Only Memory Access — архитектура с доступом только к кэш-памяти).
В машинах UMА каждый процессор имеет одно и то же время доступа к любому модулю памяти. Иными словами, каждое слово памяти можно считать с той же скоростью, что и любое другое слово памяти. Если это технически невозможно, самые быстрые обращения замедляются, чтобы соответствовать самым медленным, поэтому программисты не увидят никакой разницы. Это и значит «однородный». Такая однородность делает производительность предсказуемой, а этот фактор очень важен для написания эффективной программы.
Мультипроцессор NUMA, напротив, не обладает этим свойством. Обычно есть такой модуль памяти, который расположен близко к каждому процессору, и доступ к этому модулю памяти происходит гораздо быстрее, чем к другим. С точки зрения производительности очень важно, куда помещаются программа и данные. Машины СОМА тоже с неоднородным доступом, но по другой причине.
Во вторую подкатегорию машин MIMD попадают мультикомпьютеры, которые в отличие от мультипроцессоров не имеют памяти совместного использования на архитектурном уровне. Другими словами, операционная система в процессоре мультикомпьютера не может получить доступ к памяти, относящейся к другому процессору, просто путем выполнения команды LOAD. Ему приходится отправлять сообщение и ждать ответа. Именно способность операционной системы считывать слово из отдаленного модуля памяти с помощью команды LOAD отличает мультипроцессоры от мультикомпьютеров. Как мы уже говорили, даже в мультикомпьютере пользовательские программы могут обращаться к другим модулям памяти с помощью команд LOAD и STORE, но эту иллюзию создает операционная система, а не аппаратное обеспечение. Разница незначительна, но очень важна. Так как мультикомпьютеры не имеют прямого доступа к отдаленным модулям памяти, они иногда называются машинами NORMA (NO Remote Memory Access — без доступа к отдаленным модулям памяти).
Мультикомпьютеры можно разделить на две категории. Первая категория содержит процессоры МРР (Massively Parallel Processors — процессоры с массовым параллелизмом) — дорогостоящие суперкомпьютеры, которые состоят из большого количества процессоров, связанных высокоскоростной коммуникационной сетью. В качестве примеров можно назвать Cray T3E и IBM SP/2.
Вторая категория мультикомпьютеров включает рабочие станции, которые связываются с помощью уже имеющейся технологии соединения. Эти примитивные машины называются NOW (Network of Workstations — сеть рабочих станций) и COW (ClusterofWorkstattions — кластер рабочих станций).
Параллельные алгоритмы. Параллельная программа. Локальное и глобальное распараллеливание.
Понятие параллельного алгоритма (Parallel Algorithm) относится к фундаментальным в теории вычислительных систем. Это понятие, прежде всего, ассоциируется с вычислительными системами с массовым параллелизмом. Параллельный алгоритм – это описание процесса обработки информации, ориентированное на реализацию в коллективе вычислителей. Такой алгоритм, в отличие от последовательного, предусматривает одновременное выполнение множества операций в пределах одного шага вычислений и как последовательный алгоритм сохраняет зависимость последующих этапов от результатов предыдущи.
Параллельный алгоритм решения задачи составляет основу параллельной программы, которая, в свою очередь, влияет на алгоритм функционирования коллектива вычислителей. Запись параллельного алгоритма на языке программирования, доступном коллективу вычислителей, и называют параллельной программой, а сам язык – параллельным. Параллельные алгоритмы и программы следует разрабатывать для тех задач, которые недоступны для решения на средствах, основанных на модели вычислителя. Эти задачи принято называть сложными или трудоемкими.
Методы и алгоритмы обработки информации, решения задач, как правило, – последовательные. Процесс “приспособления” методов к реализации на коллективе вычислителей или процесс “расщепления” последовательных алгоритмов решения сложных задач называется распараллеливанием (Paralleling or Multisequencing).
Теоретическая и практическая деятельность по созданию параллельных алгоритмов и программ обработки информации называется параллельным программированием (Parallel or Concurrent Programming). Качество параллельного алгоритма (или его эффективность) определяется методикой распараллеливания сложных задач.
Существует два подхода при распараллеливании задач: локальное и глобальное (крупноблочное) распараллеливание. Первый подход ориентирован на расщепление алгоритма решения сложной задачи на предельно простые блоки (операции или операторы) и требует выделения для каждого этапа вычислений максимально возможного количества одновременно выполняемых блоков. Он не приводит к параллельным алгоритмам, эффективно реализуемым коллективом вычислителей. В самом деле, процесс такого распараллеливания весьма трудоемок, а получаемые параллельные алгоритмы характеризуются не только структурной неоднородностью, но и существенно разными объемами операций на различных этапах вычислений. Последнее является серьезным препятствием на пути (автоматизации) распараллеливания и обеспечения эффективной эксплуатации ресурсов коллектива вычислителей. Локальное распараллеливание позволяет оценить предельные возможности коллектива вычислителей при решении сложных задач, получить предельные оценки по распараллеливанию сложных задач.
Второй подход ориентирован на разбиение сложной задачи на крупные блоки–подзадачи, между которыми существует слабая связность. Тогда в алгоритмах, построенных на основе крупноблочного распараллеливания, операции обмена между подзадачами будут составлять незначительную часть по сравнению с общим числом операций в каждой подзадаче. Такие подзадачи называют ветвями параллельного алгоритма, а соответствующие им программы – ветвями параллельной программы.
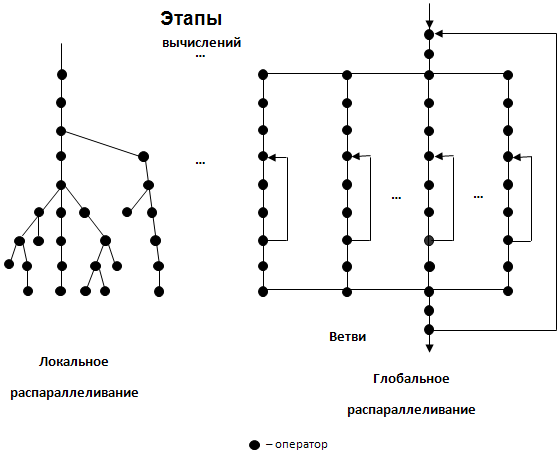
Схемы параллельных алгоритмов
Одним из конструктивных приемов крупноблочного распараллеливания сложных задач является
распараллеливание по циклам
Прием позволяет представить процесс решения задачи в виде параллельных ветвей, полученных расщеплением цикла на части, число которых в пределе равно числу повторений цикла. На входе и выходе из цикла процесс вычислений – последовательный; доля последовательных участков в общем времени решения задачи незначительна.
Как правило, последовательные участки имеют место в начале и конце параллельной программы. На начальном участке осуществляется инициирование программы и ввод исходных данных, а на конечном – вывод результатов (запись в архивные файлы). При достаточно полном воплощении принципов модели коллектива вычислителей допустимы реализации в системе параллельных ввода и вывода информации.
Последовательные участки в параллельной программе также могут иметь место, если используются негрупповые обмены информацией между ветвями (вычислителями).
Модель вычислений в виде графа «операции-операнды»
Для описания существующих информационных зависимостей в выбираемых алгоритмах решения задач может быть использована модель в виде графа «операции-операнды».
Принимается:
· время выполнения любых вычислительных операций является одинаковым и равняется 1 (в тех или иных единицах измерения).
· передача данных между вычислительными устройствами выполняется мгновенно без каких-либо затрат времени (что может быть справедливо, например, при наличии общей разделяемой памяти в параллельной вычислительной системе).
Представим множество операций, выполняемых в исследуемом алгоритме решения вычислительной задачи, и существующие между операциями информационные зависимости в виде ациклического ориентированного графа G=(V,R).
Где V={1..|V|} есть множество вершин графа, представляющих выполняемые операции алгоритма, R есть множество дуг графа (при этом дуга r=(i, j) принадлежит графу только, если операция j использует результат выполнения операции i).
Разные схемы вычислений обладают различными возможностями для распараллеливания и тем самым при построении модели вычислений может быть поставлена задача выбора наиболее подходящей для параллельного исполнения вычислительной схемы алгоритма.
Операции алгоритма, между которыми нет пути в рамках выбранной схемы вычислений, могут быть выполнены параллельно (для вычислительной схемы на рис, например, параллельно могут быть реализованы сначала все операции умножения, а затем первые две операции вычитания).
Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для параллельного выполнения вычислений необходимо задать множество (расписание)
Hp={(i, Pi, ti):i ∈ V}
в котором для каждой операции i ∈ V указывается номер используемого для выполнения операции процессора Pi , и время начала выполнения операции ti. Для того, чтобы расписание было реализуемым, необходимо выполнение следующих требований при задании множества Hp.
1) один и тот же процессор не должен назначаться разным операциям в один и тот же момент времени,
2) к назначаемому моменту выполнения операции все необходимые данные уже должны быть вычислены.
Время Tp выполнения параллельного алгоритма зависит от выбранного расписания и вычислительной схемы алгоритма. Рассмотрим основные показатели производительности параллельных алгоритмов.
Показатели эффективности параллельных вычислений: ускорение, эффективность, масштабируемость
Ускорение (speedup), получаемое при использовании параллельного алгоритма для p процессоров, по сравнению с последовательным вариантом выполнения вычислений определяется величиной Sp(n)=T1(n)/Tp(n)
т.е. как отношение времени решения задач на скалярной ЭВМ к времени выполнения параллельного алгоритма (величина n используется для параметризации вычислительной сложности решаемой задачи и может пониматься, например, как количество входных данных задачи).
Эффективность (efficiency) использования параллельным алгоритмом процессоров при решении задачи определяется соотношением Ep(n)=T1(n)/(pTp(n))=Sp(n)/p (величина эффективности определяет среднюю долю времени выполнения алгоритма, в течение которой процессоры реально используются для решения задачи).
Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p и Ep(n)=1.
При внимательном рассмотрении можно обратить внимание, что попытки повышения качества параллельных вычислений по одному из показателей (ускорению или эффективности) может привести к ухудшению ситуации по другому показателю, ибо показатели качества параллельных вычислений являются противоречивыми. Так, например, повышение ускорения обычно может быть обеспечено за счет увеличения числа процессоров, что приводит, как правило, к падению эффективности. И, обратно, повышение эффективности достигается во многих случаях при уменьшении числа процессоров (в предельном случае идеальная эффективность Ep(n)=1 легко обеспечивается при использовании одного процессора). Как результат, разработка методов параллельных вычислений часто предполагает выбор некоторого компромиссного варианта с учетом желаемых показателей ускорения и эффективности.
При выборе надлежащего параллельного способа решения задачи может оказаться полезной оценка стоимости (cost) вычислений, определяемой как произведение времени параллельного решения задачи и числа используемых процессоров.
Cp=pTp
В этой связи можно определить понятие стоимостно-оптимального (cost-optimal) параллельного алгоритма как метода, стоимость которого является пропорциональной времени выполнения наилучшего параллельного алгоритма.
Закон Амдала
Достижению максимального ускорения может препятствовать существование в выполняемых вычислениях последовательных расчетов, которые не могут быть распараллелены. Пусть f есть доля последовательных вычислений в применяемом алгоритме обработки данных, тогда в соответствии с законом Амдала (Amdahl) ускорение процесса вычислений при использовании p процессоров ограничивается величиной
Sp ≤1/(f+(1-f)/p) ≤S*=1/f
Так, например, при наличии всего 10% последовательных команд в выполняемых вычислениях, эффект использования параллелизма не может превышать 10-кратного ускорения обработки данных.
Данное замечание характеризует одну из самых серьезных проблем в области параллельного программирования (алгоритмов без определенной доли последовательных команд практически не существует). Однако часто доля последовательных действий характеризует не возможность параллельного решения задач, а последовательные свойства применяемых алгоритмов. Как результат, доля последовательных вычислений может быть существенно снижена при выборе более подходящих для распараллеливания алгоритмов;
Следует отметить также, что рассмотрение закона Амдала происходит при предположении, что доля последовательных расчетов f является постоянной величиной и не зависит от параметра n, определяющего вычислительную сложность решаемой задачи. Однако для большого ряда задач доля f=f(n) является убывающей функцией от n, и в этом случае ускорение для фиксированного числа процессоров может быть увеличено за счет увеличения вычислительной сложности решаемой задачи.
Кроме этого, существует понятие «парадокса параллелизма» – достижение ускорения и эффективности параллельного алгоритма, превышающих значения 1/f и 1, соответственно. Говоря другими словами, « парадокс параллелизма » - это более чем линейный рост производительности параллельной ВС с увеличением числа её вычислителей.
«Парадокс параллелизма» по сути не является таковым, а неравенства объясняются следующими факторами:
1. эффектом памяти,
2. возможностью применения (априори параллельных) методов решения задач, реализация которых затруднительна на последовательной ЭВМ (например, снова из-за оперативной памяти, точнее ее ограниченного объема).
Литература:
Гергель, В. Теория и практика параллельных вычислений / В.П. Гергель. - Бином. Лаборатория знаний, 2007. - 424 с.
Хорошевский, В. Архитектура вычислительных систем / В.Г. Хорошевский. Москва: МГТУ им. Баумана, 2008. - 520 с.
Цилькер, Б. Организация ЭВМ и систем / Б.Я. Цилькер, С.А. Орлов. СПб.: Питер - 2007, 672 c.
Лекция 8. Параллельные вычисления
Алгоритмы маршрутизации. Методы передачи данных. Латентность и пропускная способность сети
Алгоритмы маршрутизации определяют путь передачи данных от процессора-источника сообщения до процессора, к которому сообщение должно быть доставлено. Среди возможных способов решения данной задачи различают:
· оптимальные, определяющие всегда наикратчайшие пути передачи данных, и неоптимальные алгоритмы маршрутизации;
· детерминированные и адаптивные методы выбора маршрутов (адаптивные алгоритмы определяют пути передачи данных в зависимости от существующей загрузки коммуникационных каналов).
К числу наиболее распространенных оптимальных алгоритмов относится класс методов покоординатной маршрутизации (dimension-ordered routing), в которых поиск путей передачи данных осуществляется поочередно для каждой размерности топологии сети коммуникации. Так, для двумерной решетки такой подход приводит к маршрутизации, при которой передача данных сначала выполняется по одному направлению (например, по горизонтали до достижения вертикали процессоров, в которой располагается процессор назначения), а затем данные передаются вдоль другого направления (данная схема известна под названием алгоритма XY-маршрутизации).
Для гиперкуба покоординатная схема маршрутизации может состоять, например, в циклической передаче данных процессору, определяемому первой различающейся битовой позицией в номерах процессоров, на котором сообщение располагается в данный момент времени и на который сообщение должно быть передано.

