 2015-01-30
2015-01-30 979
979Вспомним кратко этапы компиляции программы и возможности оптимизации генерируемого кода на каждом из них.
"Типичный" компилятор состоит из двух частей:
- парсер (сканер и синтаксический анализатор), представляющий собой в значительной мере процессорно-независимую часть компилятора (front-end). Этот блок выполняет семантический и синтаксический анализ исходной программы на языке высокого уровня, проверяет правильность конструкций программы. Если программа составлена корректно, генерируется машинно-независимый код на промежуточном языке, определяемом разработчиком компилятора. Одна из составляющих этого этапа – разделение кода на часть, зависящую только от конкретного языка программирования, и часть, зависящую от архитектуры процессора;
- генератор программного кода (back-end) получает в качестве входных данных программный код на промежуточном языке и генерирует объектный код для конкретной архитектуры процессора. Обычно вначале выполняется целый ряд алгоритмов глобальной оптимизации промежуточного кода с учетом особенностей процессора и параметров компиляции, например, числа доступных регистров. Затем генерируется объектный код, после которого вновь выполняется набор процедур оптимизации, но уже нацеленных на повышение эффективности сгенерированного ассемблерного кода. Эта пост-оптимизация может быть как глобальной, так и локальной. Back-end компилятор включает в себя несколько этапов, показанных на рис.1.
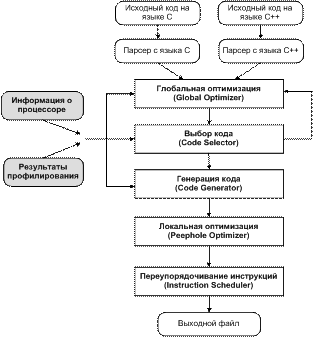
Рис.1. Этапы компиляции и генерации программного кода
Фактически оптимизация выполняется на каждом из этапов, но наибольшее значение имеет глобальная оптимизация. Global Optimizer выполняет "высокоуровневый" анализ программы и ряд общих оптимизаций. Эти общие оптимизации еще называют оптимизациями по базе данных (database-driven) или параметрическими (parameter-driven) оптимизациями: например, оптимизатор использует нечто вроде базы данных, чтобы определить количество доступных регистров для заданной модели процессора.
Блоки выбора и генерации кода (Code Selector и Code Generator) используют базу данных похожую на базу данных "глобального оптимизатора" для выбора ассемблерных инструкций, реализующих ту или иную конструкцию промежуточного языка. На этапе выбора кода резервируются рабочие (Scratch) регистры для хранения временных переменных. Основная задача генератора кода – окончательно "утвердить" распределение регистров таким образом, чтобы все неиспользуемые scratch-регистры хранили бы значения переменных (переменные, для которых не хватило места в регистрах, придется считывать из памяти).
После распределения регистров становятся очевидными зависимости между инструкциями. На этом этапе запускается локальный (peephole) оптимизатор, который сначала устраняет очевидные избыточности, а затем анализирует и оптимизирует явно неэффективные последовательности команд. Он работает совместно с блоком Instruction Scheduler для переупорядочивания инструкций таким образом, что снизить вероятность появления "заторов" (run-time pipeline stalls) в конвейере (например, когда инструкции в одном конвейере не могут продвигаться дольше до окончания выполнения какой-то из команд в другом конвейере – "обычная" проблема для суперскалярных процессоров).








