 2015-01-21
2015-01-21 2530
2530Пусть требуется передать достаточно длинное сообщение, составленное из ансамбля знаков 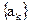 ,
, 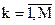 , где
, где 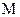 – объем первичного алфавита:
– объем первичного алфавита: 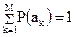 .
.
При кодировании каждому знаку первичного алфавита ставится в соответствие своя кодовая комбинация во вторичном алфавите, содержащем 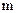 символов. Обозначим через
символов. Обозначим через 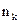 длину кодовой комбинации, соответствующей знаку
длину кодовой комбинации, соответствующей знаку 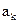 , а через
, а через 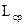 – среднюю длину кодовой комбинации при выбранном способе кодирования. Тогда:
– среднюю длину кодовой комбинации при выбранном способе кодирования. Тогда:
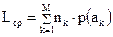 . (2.10)
. (2.10)
При эффективном кодировании стремятся к тому, чтобы 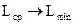 . Это значит, что при определенном объеме передаваемой информации необходимо увеличивать ее количество на каждый символ сигнала, т.е. повышать, как обычно говорят, «плотность» упаковки информации.
. Это значит, что при определенном объеме передаваемой информации необходимо увеличивать ее количество на каждый символ сигнала, т.е. повышать, как обычно говорят, «плотность» упаковки информации.
Теоретической основой для определения минимально возможной средней длины кодовых комбинаций служит теорема Шеннона о кодировании при отсутствии помех. Теорема читается так: при кодировании множества сигналов с энтропией 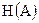 в алфавите, насчитывающем символов, при условии отсутствия помех, средняя длина кодовых комбинаций не может быть меньше частного от деления указанной энтропии на количество информации в одном символе, т.е.
в алфавите, насчитывающем символов, при условии отсутствия помех, средняя длина кодовых комбинаций не может быть меньше частного от деления указанной энтропии на количество информации в одном символе, т.е.
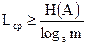 . (2.11)
. (2.11)
Справедливость теоремы Шеннона можно видеть из следующих рассуждений. Количество информации, получаемое в результате информационного обмена, как показано в п. 1.2.2, определяется выражением:
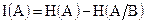 .
.
При отсутствии помех 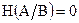 . Следовательно, среднее количество информации, передаваемое одним знаком первичного алфавита, равно:
. Следовательно, среднее количество информации, передаваемое одним знаком первичного алфавита, равно:
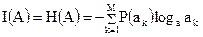 .
.
Очевидно, что кодирование будет тем эффективнее, чем большее количество информации будет приходиться на каждый символ кодовой комбинации. Так как во вторичном алфавите символов, а максимальное количество информации в символе будет в случае, когда вероятности появления символов одинаковы, то максимально возможное количество информации, приходящееся на  символ кодовой комбинации, будет равно
символ кодовой комбинации, будет равно 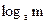 .
.
Рассуждая аналогично, можно прийти к выводу, что для эффективного кодирования длина кодовой комбинации , передающей информацию о знаке , должна приближаться к частному от деления количества информации, содержащегося в знаке , на :
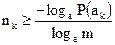 . (2.12)
. (2.12)
Если 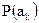 не являются целочисленными степенями , то рассчитанная таким образом величина окажется дробной. В таком случае минимальная избыточность достигается, если будет выбрано в соответствии с выражением:
не являются целочисленными степенями , то рассчитанная таким образом величина окажется дробной. В таком случае минимальная избыточность достигается, если будет выбрано в соответствии с выражением:
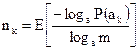 , (2.13)
, (2.13)
где 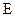 – знак округления до ближайшего большего числа. Кодирование при этом не будет оптимальным, т.е. средняя длина кодовых комбинаций будет больше минимально возможной. Однако в теории информации доказывается, что при кодировании более крупными блоками можно сколь угодно приблизиться к нижней границе.
– знак округления до ближайшего большего числа. Кодирование при этом не будет оптимальным, т.е. средняя длина кодовых комбинаций будет больше минимально возможной. Однако в теории информации доказывается, что при кодировании более крупными блоками можно сколь угодно приблизиться к нижней границе.
Из выражения (2.12) следует, что при эффективном кодировании длина конкретной кодовой комбинации тем больше, чем меньше вероятность появления знака в сообщении, и наоборот. Это значит, что часто встречающиеся знаки следует кодировать более короткими комбинациями, а редко встречающиеся – более длинными. Благодаря этому и достигается выигрыш в величине .
Дополнительное сокращение времени, затрачиваемого на передачу сообщения, можно достигнуть с помощью специального кода, позволяющего вести передачу без промежутков между кодовыми комбинациями. Чтобы на приемной стороне можно было отличить одну комбинацию от другой, т.е. чтобы код был разделимым (однозначно декодируемым), он должен строится так, чтобы ни одна более длинная кодовая комбинация не являлась продолжением более короткой. Например, при указанном кодировании нельзя применять комбинации 110 и 11010, так как вторая комбинация получена из первой путем добавления 10.
Возможность построения такого кода определяется с помощью неравенства Крафта. В нем утверждается, что такой код существует, если
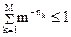 (2.14)
(2.14)
(доказательство неравенства Крафта приведено в [10]).
Итак, неравенство Крафта определяет возможность построения разделимого кода при выбранных и , а теорема Шеннона – минимально возможную среднюю длину кодовых комбинаций, отображающих буквы первичного алфавита.
2.2.3. Построение эффективного кода по методам
Шеннона-Фано и Хаффмена.
Из теоремы Шеннона следует, что для обеспечения минимальной средней длины кодовых комбинаций эффективный код должен строиться так, чтобы символы кодовых комбинаций были равновероятны и статистически независимы друг от друга. Если требования независимости и равновероятности символов по каким-либо причинам невыполнимы, то, чем лучше они выполняются, тем ближе код к оптимальному. Именно эти соображения и используются при построении эффективного кода по методикам Шеннона-Фано и Хаффмена.
Код Шеннона-Фано строится следующим образом. Буквы первичного алфавита вписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей появления знаков в каждой из групп были по возможности одинаковы. Для всех букв верхней группы в качестве первого символа кодовой комбинации принимается 1, а для букв нижней группы – 0. В дальнейшем каждая из полученных групп разбивается на две по возможности равновероятных подгруппы и символ 1 или 0 (в зависимости от подгруппы) берется вторым элементом кодовой комбинации и т.д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Пример 1.
Построить по методике Шеннона-Фано эффективный код для букв первичного алфавита, 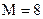 . Вероятности появления букв в сообщениях:
. Вероятности появления букв в сообщениях:
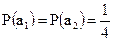 ;
; 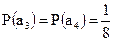 ;
;
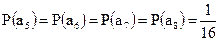 .
.
Процедура построения кода и результат приведены в таблице 2.3.
Таблица 2.3.
 Буква Буква | | Разбиения | Кодовая комбинация | | |||||||
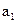 | 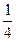 | ||||||||||
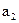 | | ||||||||||
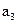 | 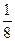 | ||||||||||
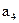 | | ||||||||||
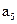 | 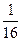 | ||||||||||
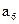 | | ||||||||||
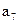 | | ||||||||||
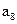 | |
Из таблицы видно, что ни одна более длинная кодовая комбинация не является продолжением более короткой, следовательно, полученный код является разделимым.
Для определения того, является ли полученный код оптимальным или нет, необходимо сравнить значения реально полученной средней длины кодовой комбинации, вычисляемой в соответствии с (2.10), с минимально достижимой по теореме Шеннона. Имеем:
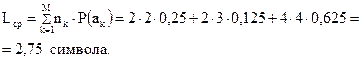
Так как вторичный код является двоичным (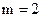 ), то минимальная средняя длина кодовой комбинации, определяемая по (2.11) и выраженная в символах, численно будет совпадать с энтропией первичного алфавита, выраженной в битах:
), то минимальная средняя длина кодовой комбинации, определяемая по (2.11) и выраженная в символах, численно будет совпадать с энтропией первичного алфавита, выраженной в битах:
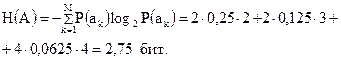
Таким образом, реально полученная средняя длина кодовой комбинации в точности равна энтропии первичного алфавита, выраженной в битах, следовательно, построенный код является оптимальным.
Для построения эффективного кода по методике Хаффмена буквы первичного алфавита вписываются в столбец в порядке убывания вероятностей (последнее не является обязательным, но желательно) и строится кодовое дерево в следующей последовательности. Сначала две буквы с наименьшими вероятностями объединяются в новую букву с вероятностью, равной сумме вероятностей объединенных букв. В дальнейшем новая буква и оставшиеся исходные буквы рассматриваются как равноценные и выполняется такая же процедура объединения. Этот процесс продолжается до тех пор, пока не получается единственная вспомогательная буква с вероятностью, равной 1.
При каждом парном объединении одна из ветвей кодового дерева обозначается символом 1, а другая 0. Код для каждой буквы представляет собой последовательности нулей и единиц, обозначающих ветви кодового дерева, по которым нужно пройти от вершины кодового дерева до данной буквы.
Пример 2.
Построить по методике Хаффмена эффективный код для букв первичного алфавита, приведенных в примере 1.
 | Считывание кода для | Знаки | Кодовые комбинации | |||||||
     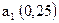 | | |||||||||
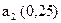 | 0,5 | | ||||||||
 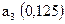 | 1,0 | |||||||||
 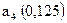 | 0,25 | | ||||||||
  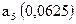 | 0,5 | | ||||||||
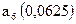 | 0,125 | | ||||||||
 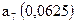 | 0,25 | | ||||||||
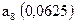 | 0,125 | | ||||||||
Сравнивая этот код с ранее полученным по методике Шеннона-Фано, можно видеть, что длины кодовых комбинаций , 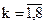 , в обоих кодах совпадают. Следовательно, код, полученный по методике Хаффмена, также является оптимальным.
, в обоих кодах совпадают. Следовательно, код, полученный по методике Хаффмена, также является оптимальным.
Если при парном объединении букв верхнюю и нижнюю ветви кодового дерева обозначить по-другому (поменять местами 0 и 1), кодовые комбинации, отображающие буквы первичного алфавита, будут другими. Однако код остается разделимым, а значения остаются прежними, что и является принципиальным.
Пример 3.
Для передачи сообщений используется алфавит из 5 знаков. Вероятность появления знаков: 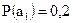 ;
; 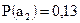 ;
; 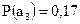 ;
; 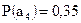 . Определить вероятность появления знака и закодировать знаки первичного алфавита эффективным кодом по методике Хаффмена.
. Определить вероятность появления знака и закодировать знаки первичного алфавита эффективным кодом по методике Хаффмена.
Решение. Эффективному кодированию подлежат только знаки, составляющие полную группу событий, т.е. 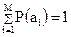 . Следовательно,
. Следовательно, 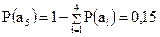 .
.
Строим кодовое дерево:
| Знаки | Кодовые комбинации | |||||||||
  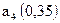 | | |||||||||
 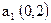 | | |||||||||
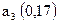 | 0,37 | 0,63 | | |||||||
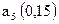 | | |||||||||
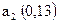 | 0,28 | | ||||||||
Проверка построенного кода на оптимальность осуществляется так же, как и в примере 1.
Для количественной оценки степени близости построенного кода к оптимальному используется коэффициент эффективности 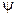 , определяемый выражением:
, определяемый выражением:
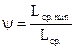 , (2.15)
, (2.15)
где 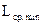 – теоретически достижимая средняя минимальная величина кодовой комбинации, определяемая выражением (2.11),
– теоретически достижимая средняя минимальная величина кодовой комбинации, определяемая выражением (2.11), 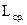 – реально достигнутая средняя длина, определяемая по формуле (2.10).
– реально достигнутая средняя длина, определяемая по формуле (2.10).

