 2015-03-22
2015-03-22 1865
1865H=4.36
L=4.4
П р и меч а н и е. При поблочном кодировании данный код будет еще ближе к оптимальному. По мере укрупнения блоков в нем будет устраняться избыточность. вызванная взаимозависимостью соседних букв.
Задача 5.45. Пользуясь приложением 5, построить оптимальный код для английского алфавита.
Задача 5.46. Пользуясь приложениями 5 и 7, построить оптимальный код Морзе, соответствующий украинскому алфавиту.
Задача 5.47. Построить 4 варианта равноценных оптимальных кодов для передачи сообщений, составленных из алфавита со сле- дующим распределением вероятностей: А1=А2=А3= А4 = 0,18; А5= = 0,1; А6 = А7 = 0,09. Чему равна средняя длина кодового слова для всех случаев?
Задача 5.48. Построить методом Хаффмена оптимальный код для алфавита со следующим распределением вероятностей появления букв в тексте: А = 0,5; В = 0,15; С =- 0,12; D= 0,1; Е = 0,04; F = 0,04; G= 0,03; Н = 0,02.
Р е ш е н и е. Сначала находят буквы с наименьшими вероятностями 0,02 (Н) и 0,03 (G), затем про водят от них линию к точке, в которой вероятность появления буквы Н либо буквы G равна 0,05. Затем берут две наименьшие вероят ности 0,04 (Р) и 0,04 (Е) и полу- чают новую точку с вероятностью 0,08. Теперь наименьшими вероят ностями обладают точки, соответствующие вспомогательным симво лам с вероятностями 0,05 и 0,08. Соединяем их линией с новой точкой, соответствующей вспомогательному символу с вероятностью 0,13. Продолжаем в том же духе до тех пор, пока линии от основных и вспомогательных символов не сольются в точке, дающей суммарную вероятность, равную 1. Обозначим каждую верхнюю линию рис. 3 цифрой 1, а нижнюю – цифрой 0. Получим ОНК, который для каждого слова представляет собой последовательность нулей и единиц, которые встречаются по пути к данному слову от конечной точки (1,00). Полученные коды представлены в таблице:
| Буква | Вероятность | Онк | Число знаков в кодовом слове | 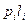 |
| A | 0,50 | 0,50 | ||
| B | 0,15 | 0,45 | ||
| C | 0,12 | 0,36 | ||
| D | 0,10 | 0,30 | ||
| E | 0,04 | 0,20 | ||
| F | 0,04 | 0,20 | ||
| G | 0,03 | 0,15 | ||
| H | 0,02 | 0,10 |
п р и м е ч а н и е. Нетрудно убедиться в том, что, кодируя по методу Шеннона – Фано, мы получила бы ту же среднюю длину кодового слова. При этом полученные слова имели бы вид: 0; 100; 101; 110; 11100; 11101; 11110; 11111.
Полученные коды могут быть однозначно декодированы на приемном конце благодаря тому, что ни один из кодов не является началом другого. Более того такой код может автоматически восстановить правильное содержание даже в том случае, когда декодирование началось не с начала сообщения или код был принят с ошибкой.
Задача 5.49. Построить ОНК по методу Шеннона – Фано и по методу Хаффмена, если символы источника сообщений появляются с вероятностями: А1 = А2 = А3 = А4 =0,19; А5 = А6 = А7 =0 08. Сравнить, насколько полученные коды близки к оптимальному.
3адача 5.50. Закодировать методом Хаффмена блоки со следующими вероятностями появления в тексте: запятая – 0,37; товарищ – 0,13; свою – 0,125; и – 0,08; труд – 0,06; бой – 0,05; отчизна – 0,05; хранить – 0,023; в – 0,11; беззаветно – 0,002. Построить во вторичном алфавите сообщение: “Товарищ, товарищ, в труде и в бою храни беззаветно Отчизну свою”. Чему равна средняя длина кодовых слов полученного ОНК?
3адача 5.51. Определить емкость бинарного канала связи для передачи оптимального кода, построенного из алфавита А, Б, В, Г, Д, Е, Я, 3, если вероятности появления букв равны соответственно: 0,06; 0,15; 0,15; 0,07; 0,05; 0,3; 0,18; 0,04,' а время передачи одной буквы – 0,1 сек.
Решение. Строим оптимальный код:
| Буква | Вероятность появления буквы | Кодовое слово | Число знаков в кодовом слове | |
| Е | 0,3 | 0,6 | ||
| Ж | 0,18 | 0,36 | ||
| Б | 0,15 | 0,45 | ||
| В | 0,15 | 0,45 | ||
| Г | 0,07 | 0,28 | ||
| А | 0,06 | 0,24 | ||
| Д | 0,05 | 0,2 | ||
| З | 0,04 | 0,16 | ||








