 2015-04-08
2015-04-08 936
936Если функция регрессии линейна, то говорят о линейной регрессии. Модель линейной регрессии (линейное уравнение) является наиболее распространенным (и простым) видом зависимости между экономическими переменными. Кроме того, построенное линейное уравнение может служить начальной точкой эконометрического анализа.
11 Например, Кейнсом была предложена формула такого типа для моделирования зависимости частного потребления С от располагаемого дохода I: С = С0+bI, где С0 —величина автономного потребления, b (0<b < 1) — предельная склонность к потреблению. Однако при использовании этой модели при анализе конкретных данных мы практически всегда будем иметь определенную погрешность, так как строгой функциональной зависимости между этими показателями нет. Однако никто не будет отрицать, что люди (домохозяйства) с
Методы регрессионного анализа рассчитаны, главным образом, на случай устойчивого нормального распределения, в котором изменения от опыта к опыту проявляются лишь в виде независимых испытаний.
Выделяются различные формальные задачи регрессионного анализа. Они могут быть простыми или сложными по формулировкам, по математическим средствам и трудоемкости. Перечислим и рассмотрим на примерах те из них, которые представляются основными.
Первая задача — выявить факт изменчивости изучаемого явления при определенных, но не всегда четко фиксированных условиях. В предыдущей лекции мы уже решали эту задачу с помощью параметрических и непараметрических критериев.
Вторая задача — выявить тенденцию как периодическое изменение признака. Сам по себе этот признак может быть зависим или не зависим от переменной-условия (он может зависеть от неизвестных или неконтролируемых исследователем условий). Но это не важно для рассматриваемой задачи, которая ограничивается лишь выявлением тенденции и ее особенностей.
Проверка гипотез об отсутствии или наличии тенденции может выполняться с использованием критерия Аббе. Критерий Аббе предназначен для проверки гипотез о равенстве средних значений, установленных для 4<n<60 взаимно независимых нормально распределенных выборок.
Эмпирическое значение критерия Аббе вычисляется по формуле:
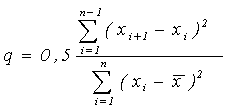 (8)
(8)
где 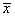 — среднее арифметическое из выборки;
— среднее арифметическое из выборки;
п – число значений в выборке.
Согласно критерию, гипотеза о равенстве средних отклоняется (принимается альтернативная гипотеза), если значение статистики 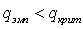 . Табличное (критическое) значение статистики определяется из таблицы для q-критерия Аббе, которая с сокращениями заимствована из книги Л.Н. Болышева и Н.В. Смирнова (см. Приложение 3).
. Табличное (критическое) значение статистики определяется из таблицы для q-критерия Аббе, которая с сокращениями заимствована из книги Л.Н. Болышева и Н.В. Смирнова (см. Приложение 3).
В качестве таких величин, для которых применим критерий Аббе, могут выступать выборочные доли или проценты, средние арифметические и другие статистики выборочных распределений, если они близки к нормальному (или предварительно нормализованы). Поэтому критерий Аббе может найти широкое применение в психолого-педагогических исследованиях. Рассмотрим пример выявления тенденции с помощью критерия Аббе.
Пример 4. В табл. 5 представлена динамика процента студентов IV курса, на «отлично» сдававших экзамены в зимние сессии на протяжении 10 лет работы одного из факультетов университета. Требуется установить, есть ли тенденция к повышению успеваемости.
Таблица 5. Динамика процента отличников четвертого курса за 10 лет работы факультета
| Учебный год | % |
| 1995-96 | 10,8 |
| 1996-97 | 16,4 |
| 1997-98 | 17,4 |
| 1998-99 | 22,0 |
| 1999-00 | 23,0 |
| 2000-01 | 21,5 |
| 2001-02 | 26,1 |
| 2002-03 | 17,2 |
| 2003-04 | 27,5 |
| 2004-05 | 33,0 |
В качестве нулевой проверяем гипотезу об отсутствии тенденции, т. е. о равенстве процентов.
Усредняем проценты, приведенные в табл. 5, находим, что =21,5. Вычисляем разности между последующими и предыдущими значениями в выборке, возводим их в квадрат и суммируем:
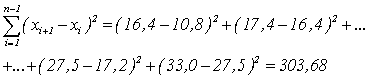
Аналогично вычисляет знаменатель в формуле (8), суммируя квадраты разностей между каждым измерением и средним арифметическим:
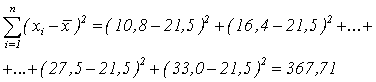
Теперь по формуле (8) получаем:
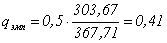
В таблице критерия Аббе из Приложения 3 находим, что при n=10 и уровне значимости 0,05 критическое значение 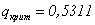 , что больше полученного нами 0,41, следовательно гипотезу о равенстве процента «отличников» приходится отклонить, и можно принять альтернативную гипотезу о наличии тенденции.
, что больше полученного нами 0,41, следовательно гипотезу о равенстве процента «отличников» приходится отклонить, и можно принять альтернативную гипотезу о наличии тенденции.
Третья задача – это выявление закономерности, выраженной в виде корреляционного уравнения (регрессии).
Пример 5. Эстонский исследователь Я. Микк [1], изучая трудности понимания текста, установил «формулу читаемости», которая представляет собой множественную линейную регрессию:
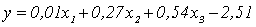 — оценка трудности понимания текста,
— оценка трудности понимания текста,
где х1 - длина самостоятельных предложений в количестве печатных знаков,
х2 - процент различных незнакомых слов,
х3 - абстрактность повторяющихся понятий, выраженных существительными.
Сравнивая между собой коэффициенты регрессии, выражающие степень влияния факторов, можно видеть, что трудность понимания текста определяется прежде всего его абстрактностью. Вдвое меньше (0,27) трудность понимания текста зависит от числа незнакомых слов и практически она совсем не зависит от длины предложении.
Лекция_9
Обзор программного обеспечения для статистического анализа данных
Потребность в средствах статистического анализа данных очень велика, что и послужило причиной для развития рынка статистических программ.
Наилучший выбор статистического пакета для анализа данных зависит от характера решаемых задач, объема обрабатываемых данных, квалификации пользователей, имеющегося оборудования.
Число статистических пакетов, получивших распространение в России, достаточно велико (несколько десятков). Из зарубежных пакетов это STATGRAPHICS, SYSTAT, STATISTICA, SPSS, SAS, CSS. Из отечественных можно назвать такие пакеты, как STADIA, ЭВРИСТА, МЕЗОЗАВР, САНИ, КЛАСС-МАСТЕР, СТАТЭксперт и др.
Для пользователей, имеющих дело со сверхбольшими объемами данных или узкоспециальными методами анализа, пока нет альтернативы использованию профессиональных западных пакетов. Среди интерактивных пакетов такого рода наибольшими возможностями обладает пакет SAS.
Если Вам необходимо обработать данные умеренных объемов (несколько сотен или тысяч наблюдений) стандартными статистическими методами, подойдет универсальный или специальный статистический пакет, надо только убедиться, что он содержит нужные методы обработки.
Пакеты STADIA и STATISTICA являются универсальными пакетами, содержащими большинство стандартных статистических методов. Пакеты SPSS и SyStat перенесены на персональные компьютеры с больших ЭВМ предыдущих поколений, поэтому, наряду с представительным набором тщательно реализованных вычислительных методов, они сохраняют и некоторые архаические элементы. Однако имеющиеся в них возможности командного языка (впрочем, очень непростые в изучении и использовании) могут быть весьма полезны для сложных задач обработки данных. Пакеты STADIA и STATISTICA исходно разработаны для ПЭВМ, а поэтому проще в обращении. Эти пакеты, пожалуй, содержат наибольшее количество методов статистического анализа.








