 2015-04-12
2015-04-12 670
670В основе средств обеспечения отказоустойчивости дисковой памяти лежит общий для всех отказоустойчивых систем принцип избыточности, и дисковые подсистемы RAID (Redundant Array of Inexpensive Disks, дословно — «избыточный массив недорогих дисков») являются примером реализации этого принципа. Идея технологии RAID-массивов состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске. Организация совместной работы нескольких централизованно управляемых дисков позволяет придать их совокупности новые свойства, отсутствовавшие у каждого диска в отдельности.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. В Windows NT, например, таким драйвером является FtDisk — драйвер отказоустойчивой дисковой подсистемы. Существуют также различные модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Дисковый массив RAID представляется для пользователей и прикладных программ единым логическим диском. Такое логическое устройство может обладать различными качествами в зависимости от стратегии, заложенной в алгоритмы работы средств централизованного управления и размещения информации на всей совокупности дисков. Это логическое устройство может, например, обладать повышенной отказоустойчивостью или иметь производительность, значительно большую, чем у отдельно взятого диска, либо обладать обоими этими свойствами. Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
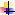 степень избыточности хранимой информации (или тесно связанная с этим критерием стоимость хранения единицы информации);
степень избыточности хранимой информации (или тесно связанная с этим критерием стоимость хранения единицы информации);
производительность операций чтения и записи; Q степень отказоустойчивости.
В логическом устройстве RAID-0 (рис. 8.12) общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается
на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0 могут отличаться размерами блоков данных, например в наборах с чередованием, представляющих собой программную реализацию RAID-0 в Windows NT, на диски поочередно записываются полосы данных (strips) по 64 Кбайт. При чтении контроллер мультиплексирует блоки данных, поступающие со всех дисков, и передает их источнику запроса.
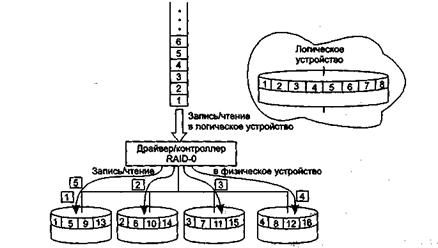
Рис. 8.12. Организация массива RAID-0
Пo сравнению с одиночным диском, в котором данные записываются и считываются с диска последовательно, производительность дисковой конфигурации RAID-0 значительно выше за счет одновременности операций записи/чтения по всем дискам массива.
вровень RAID-0 не обладает избыточностью данных, а значит, не имеет возможности повысить отказоустойчивость. Если при считывании произойдет сбой, то данные будут безвозвратно испорчены. Более того, отказоустойчивость даже снижается, поскольку если один из дисков выйдет из строя, то восстанавливать придется все диски массива. Имеется еще один недостаток — если при работе с.AID-0 объем памяти логического устройства потребуется изменить, то сделать это путем простого добавления еще одного диска к уже имеющимся в RAID-массиве дискам невозможно без полного перераспределения информации по всему изменившемуся набору дисков.
Уровень RAID-1 (рис. 8.13) реализует подход, называемый зеркальным копированием (mirroring). Логическое устройство в этом случае образуется на основе одной или нескольких пар дисков, в которых один диск является основным, а другой диск (зеркальный) дублирует информацию, находящуюся на основном диске. Если основной диск выходит из строя, зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная отказоустойчивость логического устройства. За это приходится платить избыточностью — все данные хранятся на логическом устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется лишь на 50 %.
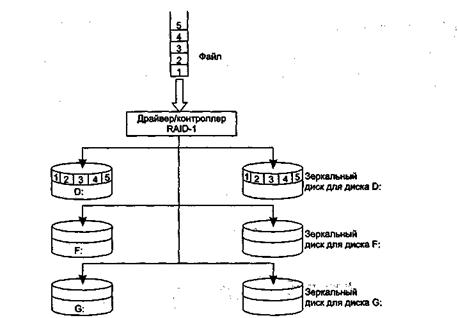
Рис. 8.13. Организация массива RAID-1
При внесении изменений в данные, расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом дублирование операций абсолютно прозрачно для пользователя и приложений. Удвоение количества операций записи снижает, хотя и не очень значительно, производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием дисков дублируются и их контроллеры. Такое дублирование (duplexing) помимо повышения скорости операций записи обеспечивает большую надежность системы — данные на зеркальном диске останутся доступными не только при сбое диска, но и в случае сбоя дискового контроллера.
Некоторые современные контроллеры (например, SCSI-контроллеры) обладают способностью ускорять выполнение операций чтения с дисков, связанных в зеркальный набор. При высокой интенсивности ввода-вывода контроллер распределяет нагрузку между двумя дисками так, что две Операции чтения могут быть выполнены одновременно. В результате распараллеливания работы по считыванию данных между двумя дисками время выполнения операции чтения может быть снижено в два раза! Таким образом, некоторое снижение производительности, возникающее при выполнении операций записи, с лихвой компенсируется повышением скорости выполнения операций чтения.
Уровень RAID-2 расщепляет данные побитно: первый бит записывается на первый диск, второй бит — на второй диск и т. д. Отказоустойчивость реализуется в RAID-2 путем использования для кодирования данных корректирующего кода Хэмминга, который обеспечивает исправление однократных ошибок и обнаружение двукратных ошибок. Избыточность обеспечивается за счет нескольких дополнительных дисков, куда записывается код коррекции ошибок. Так, массив с числом основных дисков от 16 до 32 должен иметь три дополнительных диска для хранения кода коррекции. RAID-2 обеспечивает высокую производительность и надежность, но он применяется в основном в мэйнфреймах и суперкомпьютерах. В сетевых файловых серверах этот метод в настоящее время практически не используется из-за высокой стоимости его реализации.
В массивах RAID-3 используется расщепление (stripping) данных на массиве дисков с выделением одного диска на весь набор для контроля четности. То есть если имеется массив из N дисков, то запись на N-1 из них производится параллельно с побайтным расщеплением, а N-й диск используется для записи контрольной информации о четности. Диск четности является резервным. Если какой-либо диск выходит из строя, то данные остальных дисков плюс данные о четности резервного диска позволяют не только определить, какой из дисководов массива вышел из строя, но и восстановить утраченную информацию. Это восстановление может выполняться динамически, по мере поступления запросов, или в результате выполнения специальной процедуры восстановления, когда содержимое отказавшего диска заново генерируется и записывается на резервный диск.
Рассмотрим пример динамического восстановления данных. Пусть массив RAID-3 состоит из четырех дисков: три из них — ДИСК 1, ДИСК 2 и ДИСК 3 — хранят данные, а ДИСК 4 хранит контрольную сумму по модулю 2 (XOR). И пусть на логическое устройство, образованное этими дисками, записывается последовательность байт, каждый из которых имеет значение, равное его порядковому номеру в последовательности. Тогда первый байт 0000 0001 попадет на ДИСК 1, второй байт 0000 0010 - на ДИСК 2, а третий по порядку байт - на ДИСК 3. На четвертый диск будет записана сумма по модулю 2, равная в данном случае 0000 0000 (рис. 8.14). Вторая строка таблицы, приведенной на рисунке, соответствует следующим трем байтам и их контрольной сумме и т. д. Представим, что ДИСК 2 вышел из строя.
| ДИСК 1 | ДИСК 2 | Диск 3 | ДИСК 4 |
Рис. 8.14. Пример распределения данных по дискам массива RAID-3
При поступлении запроса на чтение, например, пятого байта (он выделен жирным шрифтом) контроллер дискового массива считывает данные, относящиеся к этой строке со всех трех оставшихся дисков — байты 0000 0100, 0000 ОНО, 0000 0111 — и вычисляет для них сумму по модулю 2. Значение контрольной суммы 0000 0101 и будет являться восстановленным значением потерянного из-за неисправности пятого байта.
Если же требуется записать данные на отказавший диск, то эта операция физически не выполняется, вместо этого корректируется контрольная сумма — она получает такое значение, как если бы данные были действительно записаны на этот диск.
Однако динамическое восстановление данных снижает производительность дисковой подсистемы. Для полного восстановления исходного уровня производительности необходимо заменить вышедший из строя диск и провести регенерацию всех данных, которые хранились на отказавшем диске.
Минимальное количество дисков, необходимое для создания конфигурации RAID-3, равно трем. В этом случае избыточность достигает максимального значения — 33 %. При увеличении числа дисков степень избыточности снижается, так, для 33 дисков она составляет менее 1 %.
Уровень RAID-3 позволяет выполнять одновременное чтение или запись данных на несколько дисков для файлов с длинными записями, однако следует подчеркнуть, что в каждый момент выполняется только один запрос на ввод-вывод, то есть RAID-3 позволяет распараллеливать ввод-вывод в рамках только одного процесса (рис. 8.15). Таким образом, уровень RAID-3 повышает как надежность, так и скорость обмена информацией.
Рис. 8.15. Организация массива RAID-3
Организация RAID-4 аналогична RAID-3, за тем исключением, что данные распределяются на дисках не побайтно, а блоками. За счет этого может происходить независимый обмен с каждым диском. Для хранения контрольной информации также используется один дополнительный диск. Эта реализация удобна для файлов с очень короткими записями и большей частотой операций чтения по сравнению с операциями записи, поскольку в этом случае при подходящем размере блоков диска возможно одновременное выполнение нескольких операций чтения.
Однако по-прежнему допустима только одна операция записи в каждый момент времени, так как все операции записи используют один и тот же дополнительный диск для вычисления контрольной суммы. Действительно, информация о четности должна корректироваться каждый раз, когда выполняется операция записи. Контроллер должен сначала считать старые данные и старую контрольную информацию, а затем, объединив их с новыми данными, вычислить новое значение контрольной суммы и записать его на диск, предназначенный для хранения контрольной информации. Если требуется выполнить запись в более чем один блок, то возникает конфликт по обращению к диску с контрольной информацией. Все это приводит к тому, что скорость выполнения операций записи в массиве RAID-4 снижается.
В уровне RAID-5 (рис. 8.16) используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по всем дискам массива. При выполнении операции записи требуется в три раза больше оперативной памяти. Каждая команда записи инициирует ту же последовательность «считывание—модификация—запись» в нескольких дисках, как и в методе RAID-4. Наибольший выигрыш в производительности достигается при операциях чтения. Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, скорость записи по сравнению с уровнем RAID-4 увеличивается, однако она все еще гораздо ниже скорости отдельного диска метода RAID-1 «или RAID-3.
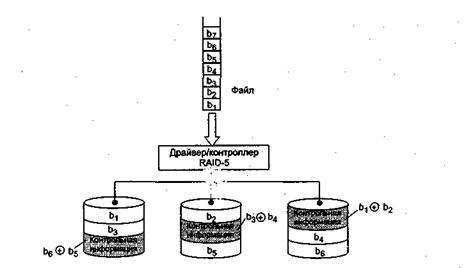
Рис. 8.16. Организация массива RAID-5
Кроме рассмотренных выше имеются еще и другие варианты организации совместной работы избыточного набора дисков, среди них можно особо отметить технологию RAID-10, которая представляет собой комбинированный способ, при котором данные «расщепляются» (RAID-0) и зеркально копируются (RAID-1) без вычисления контрольных сумм. Обычно две пары «зеркальных» массивов объединяются и образуют один массив RAID-0. Этот способ целесообразно применять при работе с большими файлами.
В табл. 8.2 сведены основные характеристики для некоторых конфигураций избыточных дисковых массивов.

Таблица 8.2. Характеристики уровней RAID
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Дайсон П. Овладеваем пакетом Norton Utilites 6: Пер. с англ. М.: Мир, 1993.
2. Дунаев С. UNIX SYSTEM V. Release 4.2. Общее руководство. М.: ДИАЛОГ–МИФИ, 1995.
3. Дженнингс Р. Windows 95 в подлиннике: Пер. с англ. СПб.: BHV – Санкт-Петербург, 1995.
4. Зубанов Ф. Windows NT Server: администрирование и надежность. М:. Издательский отдел «Русская Редакция» ТОО «Channel Trading Ltd.», 1996.
5. Ричард Петерсен, Linux: Руководство по операционной системе. Дюссельдорф – Киев – Москва. СПб: BHV, 1997.
6. Гантер Д., Барнет С., Гантер Р. Интеграция Windows NT и UNIX. Дюссельдорф – Киев – Москва. СПб: BHV, 1998.
7. Хьюз Джефри Ф., Томас Блейер В. Руководство от Novell. Сети NetWare.: Пер. с англ. М.: Издательский дом «Вильямс», 2000.
8. Андреев А. Г. и др. Microsoft Windows 2000: Server и Professional. Русские версии. СПб.: БХВ-Петербург, 2001.
9. Олифер В. Г., Олифер Н.А. Сетевые операционные системы. СПб.: Питер, 2002.
ОТВЕТЫ НА ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1. Заменяет реальные машинные команды командами высокого уровня.
2. Создание и уничтожение процессов, распределение процессорного времени, обеспечение процессов ресурсами, синхронизация и межпроцессное взаимодействие.
3. Использование объемов памяти больших размеров, чем наличной физической памяти.
4. Преобразует символьные имена файлов в физические адреса данных на диске, организует совместный доступ к данным, защищает данные от несанкционированного доступа.
5. Логический вход в систему, назначение прав доступа к файлам и принтерам, ограничение на выполнение системных действий, аудит со-бытий.
24. Экранирует от пользователя все низкоуровневые аппаратные интерфейсы.
25. Сетевая надстройка к операционной системе.
26. Интерфейс между потребителем и поставщиком услуг (службой).
27. Да.
35. Структурная организация ОС на основе различных программных модулей.
36. Аппаратура, ядро, утилиты и приложения.
37. Согласовать прикладной программный интерфейс с функциями операционной системы.
38. Большая часть кода пишется на языке, трансляторы которого имеются на всех машинах, аппаратно-зависимый код изолируется в нескольких модулях
50. В привилегированном режиме остается небольшая часть ОС, соответствующая базовым механизмам, работа которых в пользовательском режиме невозможна.
51. Микроядро использует механизмы, аналогичные взаимодействию клиента и сервера путем обмена сообщениями.
52. Возможность ОС выполнять приложения, написанные для дру-гих ОС.
53. Библиотечные функции одной ОС подготавливаются в среде другой ОС. За счет выполнения этих функций на родном процессоре скорость работы приложения существенно повышается.
64. Количество задач, выполняемых системой в единицу времени; интерактивная работа пользователя; способность системы выдерживать заранее заданные интервалы времени между запуском задачи и получением результатов.
65. Нет.
66. Квант времени, выдаваемый системой каждому процессу.
67. Выдерживание заданного интервала времени между запуском задачи и получением результата.
74. В мультипрограммной среде в каждый момент времени выполняется только одна задача, а в мультипроцессорной – несколько, но каждая на своем процессоре.
75. Нет.
76. Нет.
81. Обеспечение процессов необходимыми ресурсами, синхронизация потоков, «зачистка» завершившихся процессов.
82. Нет.
83. Определяет момент времени смены активного потока, выбирает на выполнение готовый поток.
84. При значительном увеличении кванта времени, когда любая задача может быть решена за один квант.
85. Потоки реального времени, потоки с переменным приоритетом.
101. Символьные имена – присваивает пользователь при написании программы.
Виртуальные адреса (математические или логические адреса) –вырабатывает транслятор, переводящий программу на машинный язык.
Физические адреса – соответствуют номерам ячеек оперативной памяти, где будут расположены переменные и команды.
102. Замена всех виртуальных адресов один раз во время загрузки процесса.
Программа загружается в виртуальных адресах, но во время обращения к ОП они преобразуются в физические адреса ОП.
103. Вытесняемая (paged) и невытесняемая (non-paged).
110. Алгоритмы, основанные на перемещении сегментов процессов между ОП и дисками, и алгоритмы, в которых внешняя память не используется.
111. Свопинг (swapping) – образы процессов перемещаются целиком.
Виртуальная память (virtual memory) – только части образов процессов (сегменты и страницы) перемещаются между ОП и диском.
112. Файл свопинга или страничный файл.
113. Нет, так как в этом случае отсутствует механизм прав доступа к областям ОП.
129. Блок-ориентированные и байт-ориентированные.
130. Да.
131. Логическая модель заменяет физическую структуру хранимых данных на более удобную, представляя ее в виде файла.
132. Обычные файлы, каталоги и специальные файлы.
133. Один файл – одно полное имя.
134. Принципы размещения файлов, каталогов и системной информации на реальном устройстве.
135. Одно.
152. На системную (загрузочная запись, FAT, корневой каталог) и область данных.
153. Главная таблица файлов (MFT).
154. Атрибут. Данные также являются атрибутом файла, как и его имя.
155. Для разбиения упорядоченных имен файлов на группы с целью сокращения поиска нужного файла.
169. Нет. В роли общего ресурса могут выступать различные внешние устройства: принтеры, модемы, графопостроители и т. п. Область памяти, используемая для обмена данными между процессами, также является разделяемым ресурсом. Сами процессы в некоторых случаях выступают в роли разделяемого ресурса, когда пользователи посылают процессам сигналы, на которые процесс должен реагировать.
170. Пользователи осуществляют доступ к разделяемым ресурсам не непосредственно, а с помощью прикладных процессов, которые запускаются от его имени.
171. Нет. Для файла – чтение, запись, удаление. Для принтера – перезапуск, очистка очереди, приостановка печати.
172. Избирательный доступ, когда для каждого объекта сам владелец может определить допустимые операции с объектами.
Мандатный доступ (обязательный, принудительный) – это такой подход к определению прав доступа, при котором система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу в зависимости от того, к какой группе пользователей он принад-лежит.
173. Реальные идентификаторы субъектов задаются процессу при его порождении, а по эффективным идентификаторам проверяются права доступа процесса к файлу. Эффективные идентификаторы могут заменить реальные, но в исходном состоянии они совпадают с реальными.
184. Набор допустимых операций.
Идентификатор владельца.
Управление доступом.
185. Древовидная иерархическая структура для файлов и каталогов.
Иерархическая структура родитель-потомок для процессов.
Для устройств – принадлежность к определенному типу устройств и связь с устройствами других типов.
186. Централизованный.
187. Разрешения (permissions) – это множество операций, которые могут быть определены для субъектов всех типов по отношению к объектам любого типа: файлам, каталогам, принтерам, секциям памяти и т. д.
Права (user rights) – определяются для субъектов типа группа на выполнение некоторых системных операций: установку системного времени, архивирование файлов, выключение компьютера и т. п. Именно права, а не разрешения отличают одну встроенную группу пользователей от другой. Некоторые права у встроенной группы являются также встроенными – их у группы нельзя отнять. Остальные права можно удалить или добавить из общего списка прав.
Возможности пользователей (user abilities) определяются для отдельных пользователей на выполнение действий, связанных с формированием их операционной среды, например изменения состава главного меню и т.д.
188. Если процесс во время создания объекта явно задает все права доступа, то система безопасности приписывает этот ACL объекту.
Если процесс не снабжает объект списком ACL и объект имеет имя, то применяется принцип наследования разрешений.
Если процесс не задал явно ACL для создаваемого объекта и не имеет наследуемых элементов ACL, то используется список ACL по умолчанию из токена доступа процесса.
189. Пользователи не могут работать с каталогом или файлом, если они не имеют явного разрешения на это или же они не относятся к группе, которая имеет соответствующее разрешение. Разрешения имеют накопительный характер за исключением разрешения No Access, которое отменяет все прочие разрешения.
[1] ПРИМЕЧАНИЕ ——————————————————————————————————-
При восстановлении часто возникают ситуации, когда система пытается отменить транзакцию, которая уже была отменена или вообще не выполнялась. Аналогично при повторении некоторой транзакции может оказаться, что она уже была выполнена. Учитывая это, необходимо так определить подоперации транзакции, чтобы многократное выполнение каждой из этих подопераций не имело никакого добавочного эффекта по сравнению с первым выполнением этой подопераций. Такое свойство операции называется идемпотентностью (idempotency). Примером идемпотентной операции может служить, например, многократное присвоение переменной некоторого значения (сравните с операциями инкремента и декремента).








