 2015-04-12
2015-04-12 364
364Списком называется объект, который содержит произвольное количество других объектов. Запись списка имеет следующий вид
[a, b, c, e, f], [7, 4, -3, 5].
Элементы списка разделяются запятой, а их типы определяются соответствующей записью в разделе domains
domains
list1 = symbol*
list2 = integer*.
Так первая запись означает, что список типа list1 состоит из символов, а типа list2 – из целых чисел. В разделе предикатов должны быть соответствующие описания
pred1 (list1)
pred2 (list2).
Списки могут быть простыми, как приведенные выше, и сложными, например,
[3, [8, 9], 2, -1, [5, 4, 9],...].
В этом случае объявление списка имеет вид
domains
list = integer*
ll = list*.
В Прологе реализовано встроенное средство работы со списками. Список автоматически разбивается на две части путем записи
[H|T]
где Н обозначает голову списку (head), а T – его хвост (tail). Голова списка является элементом и, в зависимости от структуры, может быть тоже списком. Так, для списка [[a, b], e, t, k] имеем
H = [a, b], T = [e, t, k].
Хвост всегда является списком. Список, который не содержит ни одного элемента, называется пустым и обозначается как [ ]. Так, константа а и список [a] есть два разных объекта, поскольку этот список может быть изображен как [a|[]]. Попытка разбить пустой список на хвост и голову всегда приводить к неудаче. С приведенного определения вытекает, что концептуально список имеет древовидную структуру, которая для списка [a, b, c] может быть изображена так (рис 1).
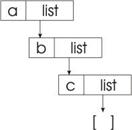
Рис 1.
Основным средством обработки списков является рекурсия. Рассмотрим задачу принадлежности элемента к списку. Поскольку списки являются объектами последовательного доступа, все действия, определенные в правиле, выполняются с текущим значением головы. В нашем случае надо определить, будет ли данный элемент совпадать с головой списка. Выполнение этого условия и будет граничным условием. При этом значение хвоста не является существенным, что и обозначается анонимной переменной. Если сравнение не было успешным, эту операцию надо повторить уже со следующим элементом списка, т.е. с головой хвоста. Необходимый вызов делается во второй части правила.
member([E|_], E).
member([_|T], E):- member(T, E).
Изъятие всех вхождений заданного элемента со списка. В этой задаче предикат должен иметь три аргумента: входной список, элемент, который подлежит изъятию, и список результат.
delete ([], [], _).
delete ([H|T], [H|T1], E):- E<>H, delete (T, T1, E).
delete ([E|T], T1, E):- delete (T, T1, E).
Рассмотрим действие правила на примере списка L = [a,f,b,c,f], из которого нужно удалить все вхождения элемента f
Фаза редукции Фаза решения
R3 = [a| R2] R =[a,b,c]
R2 = [b| R1] R2 =[b,с]
R1= [c| R0] R1 =[c]
R0 = [ ]
Изъять элемент – значит не присоединить его к хвосту списка-результата. Первое правило осуществляет простое копирование входного списка в список-результат, когда голова не равна заданному элементу.
По определению рекурсивных вычислений граничным условием является задача, решение которой известно. Вычислим длину списка (количество его элементов). Так как длина пустого списка равна нулю, граничным условием будет
len ([], 0).
При каждом рекурсивном вызове правила (обращении к длине хвоста), длина списка увеличивается на единицу, при этом значение элемента-головы не является существенным.
len ([_|T], L):- len (T, K), L = K+1.
Правило для вычисления суммы элементов списка будет совершенно аналогичным предыдущему с единственным отличием, значение головы списка необходимо для вычисления суммы.
sum ([], 0).
sum (H|T], R):- len (T, S), R = S+H.








