 2015-04-12
2015-04-12 905
905Использование бинарных деревьев поиска – удачный выбор для решения задачи поиска со вставкой, но только при условии, что все дерево может быть размещено в оперативной памяти компьютера. Однако это не всегда возможно, даже в условиях постоянно возрастающих объемов памяти современных компьютеров. Важный класс задач поиска связан с запросами к базам данных, которые хранятся на периферийных устройствах памяти (дисках и т.п.). При этом, как и в задачах внешней сортировки, рассмотренных в подразд. 3.7, высокая эффективность работы может быть достигнута применением таких алгоритмов и структур данных, которые минимизируют количество обращений к внешней памяти.
С этой точки зрения бинарные деревья представляются малопригодными. Действительно, если не принять специальных мер, то вершины дерева могут оказаться произвольным образом разбросанными по блокам (секторам) устройства, при этом почти каждый переход от вершины-отца к ее левому или правому сыну потребует выполнения операции чтения блока с устройства.
Целесообразно ввести в рассмотрение такие структуры данных (и связанные с ними алгоритмы), которые принимают во внимание блочную структуру хранения данных на устройстве. Действительно, поскольку за одно обращение к диску обязательно читается или записывается сразу блок данных, то алгоритмы поиска должны выполнить максимум полезной работы с этим блоком, прежде чем потребуется перейти к другому блоку. Такие алгоритмы легче конструировать, если физическому понятию «блок» поставить в соответствие некоторую единую структуру данных. Назовем такую структуру страницей.
Ясно, что страница должна содержать намного больше данных, чем вершина бинарного дерева. Типичный размер блока (512 байт для большинства компьютеров) позволяет разместить на одной странице данные, соответствующие нескольким десяткам ключей и указателей. Один из наиболее логичных способов перехода от бинарного дерева к набору страниц показан на рис. 4.6.
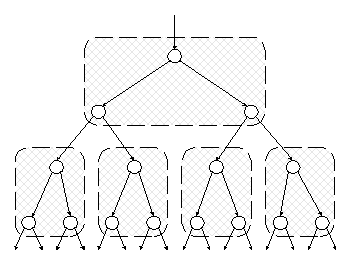
Рис. 4.6. Разбиение бинарного дерева на страницы
Изображенный на рисунке фрагмент сбалансированного бинарного дерева разбит на страницы, которые, ради простоты примера, содержат по три вершины. Разумеется, на практике страница содержит значительно больше данных. Рисунок иллюстрирует две важные особенности разбиения. Во-первых, все страницы представляют собой одинаковые структуры данных. Во-вторых, алгоритм поиска выполняет как можно больше работы на одной странице, прежде чем перейти к другой странице. В данном маленьком примере это выражается в том, что на каждой странице выполняется не одно, а два сравнения ключей.
Теперь посмотрим, что же получилось. Результат разбиения бинарного дерева на страницы схематически показан на рис. 4.7.
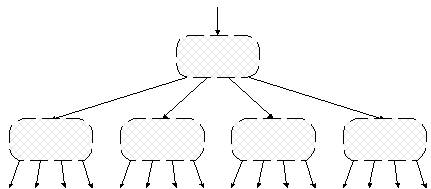
Рис. 4.7. Страничное дерево
Безусловно, это дерево. Но теперь уже не бинарное. Каждая вершина дерева представляет собой страницу, т.е. блок данных на диске, и содержит не два, а большее число указателей на нижележащие вершины-страницы (в данном примере – четыре указателя).
В действительности, страничные деревья далеко не всегда удается так хорошо сбалансировать, как на рисунке. Приходится до определенных пределов мириться и с неполными страницами, и с разной длиной ветвей в дереве страниц.
Рассмотрим подробнее, из чего состоит страница.
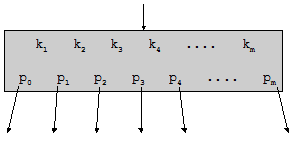
Рис. 4.8. Структура страницы
Как показано на рис. 4.8, страница содержит некоторое количество m ключей k1, k2, …, km и m+1 указателей на нижележащие страницы p0, p1, p2, …, pm. Максимальное значение m называется порядком страничного дерева; порядок дерева зависит от размеров страницы, ключа и указателя.
Каждый из pi указывает на поддерево, содержащее ключи x из определенного диапазона, а именно:
p0 x £ k1;
p1 k1 £ x £ k2;
…
pi ki £ x £ ki+1;
…
pm km £ x.
По аналогии с бинарным деревом поиска, описанным в подразд. 4.2, дерево страниц, удовлетворяющее приведенным выше неравенствам, будем называть страничным деревом поиска.
Заметим кстати, что бинарное дерево поиска можно считать частным случаем страничного при m = 1.
Поиск по страничному дереву выполняется следующим образом. Сначала искомый ключ x сравнивается с ключами корневой страницы дерева. При этом либо на странице будет найден ключ ki = x, либо будет определен интервал (ki, ki+1), в который попадает значение x. В этом случае происходит переход по указателю pi (т.е. фактически с устройства читается другая страница), после чего поиск продолжается. Если дерево не содержит искомого значения x, то на некотором шаге будет получен пустой указатель pi.
Следует заметить, что слово «указатель» в данном случае не обязательно означает адрес оперативной памяти. Если страничное дерево хранится в файле, то «указатель» будет скорее всего представлять собой смещение указываемой страницы от начала файла (в байтах или в секторах).
Может возникнуть вопрос, как на самом деле расположены ключи и указатели внутри страницы. Судя по рис. 4.6, они образуют бинарное дерево, но на рис. 4.8 размещение больше похоже на два массива. На самом деле, этот вопрос несуществен. Как уже говорилось в подразд. 3.7, операции обмена данными с устройствами выполняются настолько медленнее, чем любые операции в оперативной памяти, что способ организации поиска внутри страницы не оказывает большого влияния на общую скорость поиска. Внутри страницы можно использовать сортированный массив, бинарное дерево или любую другую удобную структуру. Желательно лишь, чтобы эта структура была как можно более компактной, поскольку это позволит увеличить m – число ключей на странице.
Скорость поиска по страничному дереву определяется главным образом числом операций чтения страницы. Поскольку при поиске выполняется спуск от страницы-корня к одной из страниц-листьев, максимальное время поиска определяется высотой дерева. Нетрудно оценить зависимость высоты страничного дерева от общего числа ключей n и порядка дерева m. Введем сначала понятие сбалансированного страничного дерева. Это дерево, все ветви которого по длине различаются не более, чем на 1, и все страницы, кроме, быть может, одной страницы на каждом уровне, содержат ровно m ключей. Можно показать, что высота сбалансированного страничного дерева не превышает logm(n) + 1. Отсюда понятно, что увеличение порядка дерева приводит к уменьшению высоты дерева, т.е. к ускорению поиска.
Как и в случае бинарных деревьев поиска, многократные операции вставки и удаления ключей в страничное дерево могут, если не принять специальных мер, привести к вырождению дерева. Вырождение заключается в том, что число ключей на страницах становится значительно меньше m, при этом ветви дерева могут сильно различаться по длине. Следствием вырождения будет не только увеличение времени поиска, как в бинарном случае, но и излишний расход дисковой памяти на хранение неполных страниц.
Здесь пора вспомнить, что, помимо ключа, каждая запись таблицы может еще содержать поле данных. На рис. 4.8 поля данных не показаны. Хранение данных внутри страниц дерева может привести к значительному уменьшению значения m (поскольку в одном секторе диска будет помещаться меньше записей). На практике, чтобы не хранить в страничном дереве объемные данные, вместо этого на странице размещают указатель на эти данные, которые хранятся где-нибудь в другом месте (например, в отдельном файле).








