 2015-04-01
2015-04-01 924
924С появлением и развитием корпоративных и иных сетей появилась возможность организации доступа к одним и тем же данным из различных структурных подразделений предприятия или из других регионов. При этом разработаны два вида баз данных:
- централизованные;
- распределенные.
Централизованная база данных характерна тем, что она полностью находится на центральном компьютере, к которому обращаются пользователи (клиенты) с помощью своих компьютеров за информацией. Управление базой данных (ее корректировка и прочие процедуры, поддерживающие ее целостность, безопасность и пр.) осуществляется централизованно (см. рис. 4.7.)
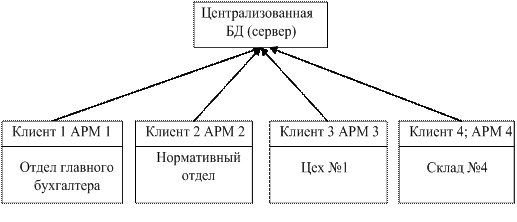
рис. 4.7. Централизованная БД.
Один компьютер, который располагает ресурсами, называется сервером. Компьютер, который обращается к серверу за данными или требованием решения задачи, называется клиентом.
Недостатки централизованной БД состоят в следующем:
- требуется передача большого потока данных;
- низкая надежность;
- низкая производительность.
|
|
|
Преимущества: минимальные затраты на корректировку централизованной БД.
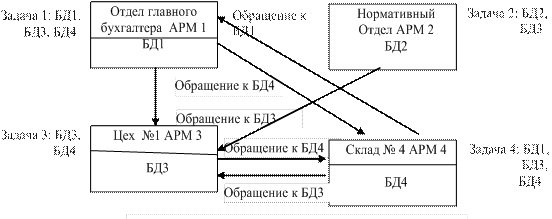
рис.4.8. Распределенная база данных
Для снижения остроты перечисленных недостатков создают распределенные базы данных, то есть базы, части которой находятся в различных узлах сети. Предприятия сами по себе имеют распределенную структуру, поэтому данные фактически распределены по структурным подразделениям. Фактически распределенная база данных есть виртуальный объект, составные части которого хранятся в разных узлах сети. Для пользователя они находятся в одной логической модели базы данных. На рис 4.8. представлена сеть с полностью распределенной БД. Стрелки указывают на направление передачи данных, необходимых для решения задач в конкретном узле:
· для решения задачи 1 в отделе главного бухгалтера требуются базы данных БД1, БД3, БД4;
· для решения задачи 2 в нормативном отделе требуются базы данных БД2, БД3;
· для решения задачи 3 в цеху № 1 требуются базы данных БД3, БД4;
· для решения задачи 4 на складе № 4 требуются базы данных БД3, БД4.
Полностью распределенная БД создается в тех случаях, когда частота решения всех задач и объемы передаваемых данных для их решения примерно одинаковы.
Главный критерий распределения данных в сети состоит в следующем: данные должны находиться там, где существует наибольшая частота обращения к ним.








