 2015-04-01
2015-04-01 3853
3853После того, как все переменные нашей анкеты были занесены в программу SPSS необходимо осуществить наполнение базы данных, основываясь на результатах, полученных от респондентов. Как уже отмечалось выше, ввод данных в программе осуществляется в поле Data View посредством ввода числа в поле переменной, в соответствии с кодировкой. Ниже представлен пример ввода данных.
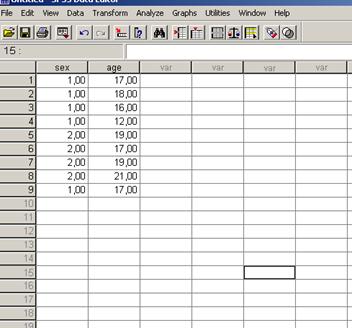
Рис. 18. Пример ввода данных в программу.
В приведенном примере показаны две переменные – пол и возраст респондента. Первая переменная имеет только два возможных варианта: «1» - мужской и «2» - женский. Вторая переменная, возраст, относится к метрической числовой шкале. Данные читаются следующим образом: первый респондент – молодой человек (1) в возрасте 17 лет. Для простоты восприятия остановимся на данном примере.
Обработка данных в программе SPSS осуществляется путем вызова соответствующих команд из главного меню Analyze. Первый этап обработки данных в социологии всегда рекомендуется начинать с частотного распределения и описательной статистики. В выпадающем меню Analyze нужно выбрать команду Descriptive Statistics (описательные статистики) и затем – Frequenses (частоты).
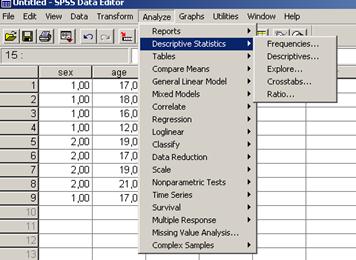
Рис. 19. Вызов меню частотного анализа.
После этого откроется новое диалоговое окно для определения переменных, которые подвергаются анализу (рис. 20).
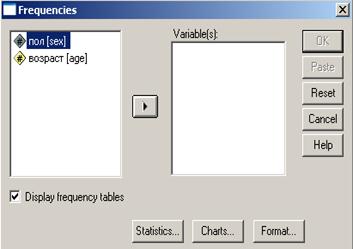
Рис. 20. Частотный анализ переменных.
Рассмотрим это окно подробнее, так как принцип выбора переменных одинаков для всех типов анализа. В диалоговом окне видны два поля: слева перечислены все переменные (в нашем случае их всего 2). Правое поле пустое. Оно как раз и предназначено для выбора переменных, подвергающихся анализу. При помощи мыши нужно выделить анализируемую переменную и нажав на кнопку  перенести ее в правое окно. Сделаем это для переменной «возраст». Окно примет следующий вид.
перенести ее в правое окно. Сделаем это для переменной «возраст». Окно примет следующий вид.
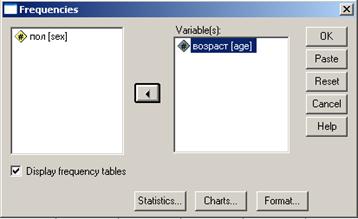
Рис. 21. Выбор переменной для анализа.
Для того, чтобы определить требуемые статистические параметры нужно нажать кнопку  и в открывшемся меню выбрать нужные статистики.
и в открывшемся меню выбрать нужные статистики.
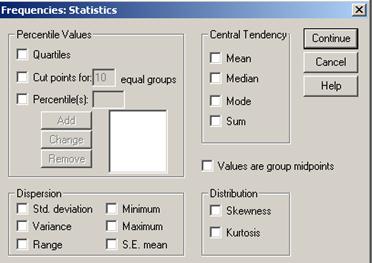
Рис. 22. Окно определения статистик.
Левый верхний угол окна содержит такие статистики, как квартиль (Quartiles), точки раздела (Cut points for) – показатели процентилей, разделяющие выборку на группы наблюдений, имеющих одинаковую ширину, то есть включают одинаковое число наблюдений, процентили (Percentiles). Нижний левый угол относится к статистикам, характеризующим меру разброса: стандартное отклонение (St. deviation), дисперсия (Variance), размах (Range), наименьшее и наибольшее значение в выборке (Minimum, Maximum) и стандартная ошибка среднего (S.E. mean). Следующая группа статистик используется наиболее часто – меры центральной тенденции: среднее (Mean), медиана (Median), мода (Mode) и сумма (Sum). Наконец, есть группа, позволяющая оценить ассиметричность распределения, - Distribution. Здесь мы видим две статистики6 Skewness (коэффициент асимметрии) и Kurtosis (коэффициент вариации). Для вычисления требуемых статистик нужно просто проставить галочки в клетках рядом с соответствующими параметрами. Для нашего примера давайте определим все меры центральной тенденции, кроме суммы, а также стандартное отклонение, дисперсию и размах. После установки соответствующих галочек, нажмем клавишу  . В окне статистик нажимаем кнопку ОК. Полученные результаты приведены на рисунке 23.[13]
. В окне статистик нажимаем кнопку ОК. Полученные результаты приведены на рисунке 23.[13]
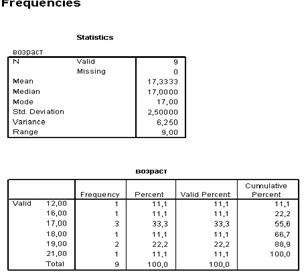
Рис. 23. Окно вывода результатов.
Полученные данные сведены в две таблицы. В первой указаны: количество наблюдений в выборке (9), количество пропущенных значений (0), среднее значение (17,3333), медиана (17), мода (17), стандартное отклонение (2,5), дисперсия (6,25) и размах (9). По этой таблице мы можем сделать вывод, что в нашей выборке средний возраст респондентов составил 17, 3 лет, размах выборки составил 9 лет, наибольшее количество респондентов находятся в возрасте 17 лет.
Вторая таблица представляет собой анализ распределения переменной возраст. В ней в левом столбце указаны все возможные варианты, в следующем столбце – абсолютное значение частот, далее – процентное значение, далее – процентное значение с учетом пропусков и накопленный процент. В нашем случае можно говорить о том, что 33,3% респондентов в возрасте 17 лет, 22,2% - 19 лет и по 11% респондентов имеют возраст 12,16, 18 и 21 год. В нашем примере у нас не было пропущенных ответов, однако на практике пропуски встречаются довольно часто. Пари анализе данных в частотном распределении крайне важно обращатиь на это внимание. При наличии пропусков в отчетах о результатах обработки следует использовать процентный показатель с учетом пропусков (Valid Percent).
Частотный анализ данных может осуществляться по указанному выше алгоритму вне зависимости от того, какую переменную мы анализируем. Однако, как уже было отмечено выше, чрезвычайно важно помнить о том, по какой шкале измеряется анализируемая переменная. В данном примере мы сознательно обратились к переменной, которая относится к метрическим шкалам и имеет самые богатые возможности для анализа. Вместе с тем, при выборе такой переменной, как «пол», вычисление статистик типа среднее значение, стандартное отклонение и прочие становится бессмысленным, так как переменная принадлежит к номинальной шкале.

