 2015-04-30
2015-04-30 1355
1355В процессе принятия решений пользователь генерирует некоторые гипотезы, которые необходимо проверять. Проверка гипотезы может быть осуществлена на основе информации об анализируемой предметной области. Причем не представляется возможным заранее предусмотреть, какие запросы будет формировать пользователь, т.к. генерация этих запросов производится «на лету».
К тому же требуется, чтобы анализ данных можно было осуществлять по множеству параметров, т.е. должна быть предусмотрена возможность выполнения многомерного анализа данных.
В связи с этим встает вопрос о том, как организовать данные, описывающие предметную область так, чтобы по ним было удобно проводить многомерный анализ.
Такой анализ данных целесообразно проводить на основе многомерной модели данных, которая лежит в основе построения большинства хранилищ данных.
Многомерная модель данных – это информационное содержимое предметной области в виде N-мерного куба (гиперкуба), где каждая ось соответствует измерению, представлено на рисунке 3.3.1
|
|
|
Измерение – это последовательность значений одного из анализируемых параметров.
На пересечении осей измерений находятся факты (меры), количественно характеризующие события, описываемые значениями измерений.
| Измерение 1 |
| Измерение 2 |
| Измерение N |
| Факты (меры) |
Рисунок 3.3.1 - Графическое представление многомерной модели данных
Многомерное представление данных позволяет легко выполнять ряд операций.
1. Срез – формирование подмножества данных, соответствующих фиксированному значению одного или нескольких измерений, т.е. построение проекции гиперкуба, представлено на рисунке 3.3.2.
| Фиксированное значение |
| Срез |
Рисунок 3.3.2 - Операция среза многомерной модели данных
2. Вращение – изменение расположения измерений в представлении данных многомерной модели, представлено на рисунке 3.3.3.
| Вращение |
| Измерение 1 |
| Измерение 3 |
| Измерение 2 |
| Измерение 1 |
| Измерение 2 |
| Измерение 3 |
Рисунок 3.3.3 - Операция вращения многомерной модели данных
Операция вращения обычно применяется при отображении многомерных данных в отчете в виде кросс-таблиц или кросс-диаграмм.
Кросс-таблица представляет собой размещение многомерных данных на плоскости в виде сводной таблицы.
Измерения могут быть в строках и столбцах кросс-таблицы, а факты с применением какой-либо агрегирующей функции отображаются на пересечении измерений, т.е. на пересечении строк и столбцов.
В качестве агрегирующих функций чаще всего используются: минимум (min), максимум (max), сумма(sum), среднее (average), количество(count).
Кросс-таблица состоит из следующих элементов:
|
|
|
· заголовки строк;
· заголовки столбцов;
· матрица с фактами.
Изобразить геометрическую интерпретацию гиперкуба с размерностью более 3-х не представляется возможным. Но в принципе число используемых измерений может быть любым.
Однако следует помнить, что использование большого числа измерений не рекомендуется, в первую очередь потому, что осмысление и интерпретация результатов аналитиком в этом случае могут быть затруднены.
3. Консолидация и детализация – переход от детального представления данных к агрегированному (обобщенному) и наоборот, отражено на рисунке 3.3.4 и рисунке 3.3.5.
При выполнении операции детализации отображаются все записи, которые вносят свой вклад в формирование значения выделенной ячейки, имеющей агрегированное значение в многомерной модели.
| Консолидация |
Рисунок 3.3.4 - Операция консолидации многомерной модели данных
| Детализация |
Рисунок 3.3.5 -Операция детализации многомерной модели данных
По кросс-таблицам, полученным в результате консолидации, строятся кросс-диаграммы, позволяющие анализировать тренд.
Тренд позволяет увидеть тенденции, которые обычно скрыты из-за большого разброса значений, наличия отклонений, не типичных для отображаемого процесса.
Таким образом, представленные операции многомерной модели данных предоставляют конечному пользователю ряд аналитических и навигационных функций:
· расчеты и вычисления по нескольким измерениям;
· анализ трендов;
· выборка подмножеств данных для просмотра;
· получение обобщенных (агрегированных) значений;
· переход к детальным данным, лежащим в основе анализа;
· вращение кросс-таблиц отображаемых данных.
Легкость проводимых манипуляций с гиперкубом обеспечивает возможность формирования запросов «на лету».
Есть два основных подхода к реализации многомерной модели данных:
· Multidimensional OLAP (MOLAP) – реализация механизма при помощи многомерной базы данных на стороне сервера, т.е. использование специализированных OLAP-средств.
· Relational OLAP (ROLAP) – построение кубов «на лету» на основе SQL запросов к реляционной СУБД, т.е. внедрение средств OLAP в реляционную СУБД.
Каждый из этих подходов имеет свои плюсы и минусы.
MOLAP использует для хранения и управления данными многомерные базы данных. При этом данные хранятся в виде упорядоченных многомерных массивов.
Физически данные, представленные в многомерном виде, хранятся в плоских файлах. При этом куб представляется в виде одной плоской таблицы, в которую построчно вписываются все комбинации всех измерений с соответствующими им значениями фактов.
ROLAP использует для хранения и управления данными реляционные базы данных.
В таблице 3.19 представлена сравнительная характеристика ROLAP и MOLAP, из которой видно, что по многим параметрам ROLAP превосходит MOLAP.
Таблица 3.19 - Сравнительные характеристики ROLAP и MOLAP
| Характеристики | ROLAP | MOLAP |
| Производительность | Ниже | Выше |
| Требуемый объем памяти | Меньший | Больший |
| Обработка разреженных данных | Лучше | Хуже |
| Обработка детализированных данных | Лучше | Хуже |
| Функциональная гибкость | Выше | Ниже |
| Уровень защиты данных | Выше | Ниже |
В связи с тем, что рабочее место аналитика (аналитические возможности) разрабатываются для системы, которая уже реализована средствами реляционной СУБД, то целесообразно выбрать в качестве способа реализации многомерной модели данных модель ROLAP.
В этом случае построение кубов производится «на лету» на основе SQL запросов к имеющейся реляционной БД.
В настоящее время распространены две основные схемы реализации многомерного представления данных с помощью реляционных таблиц: схема «звезда» и схема «снежинка».
Наибольшее распространение получила схема «звезда» ввиду простоты ее реализации и более высокого быстродействия.
|
|
|
На рисунке 3.3.6 изображена схема, в центре которой располагаются факты и агрегатные данные, а «лучами» являются измерения. Каждая звезда описывает определенное действие (процесс), например, финансирование.
| Отечественное финансирование Зарубежное финансирование |
| Факты |
| Время |
| Проект |
| Вуз |
| Измерение |
| Измерение |
| Измерение |
| Процесс «Финансирование» |
| Заказчик |
| Измерение |
Рисунок 3.3.6 - Пример схемы «звезда»
Схема «звезда» предполагает выделение таблиц фактов и таблиц измерений. Каждая таблица фактов содержит детальные данные и внешние ключи на таблицы измерений.
Таблица фактов содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. Обычно для однозначной идентификации члена измерения используется суррогатный ключ и как минимум одно описательное поле (обычно имя члена измерения).
Каждая таблица измерений должна находиться в отношении «один-ко-многим» с таблицей фактов.
При реализация многомерного представления данных в дипломном проекте также используется схема «снежинка». Как и в схеме «звезды», схема «снежинки» представлена централизованной таблицей фактов, соединенной с таблицами измерений. Отличием является то, что здесь таблицы измерений нормализованы с рядом других связанных измерительных таблиц, — в то время как в схеме звезды таблицы измерений полностью денормализованы, с каждым измерением представленным в виде единой таблицы, без соединений на связанные таблицы в схеме «снежинки». Чем больше степень нормализации таблиц измерений, тем сложнее выглядит структура схемы «снежинки». Создаваемый «эффект снежинки» затрагивает только таблицы измерений, и не применим к таблицам фактов. Пример схемы «снежинка» приведен на рисунке 3.3.7.
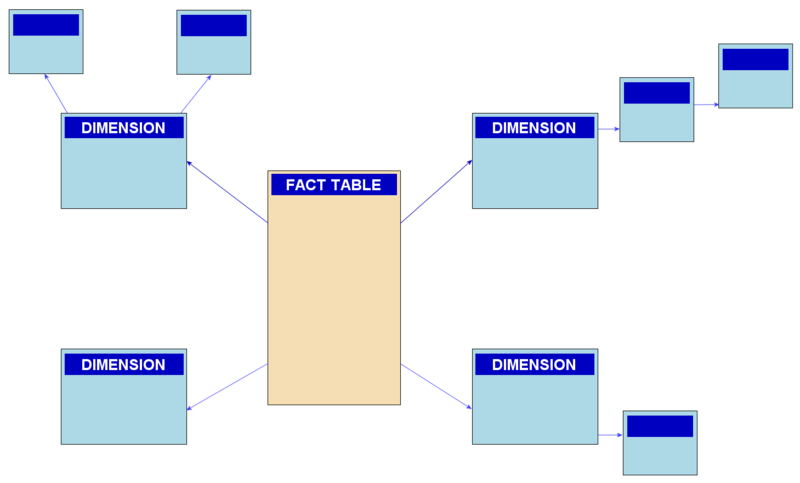
Рисунок 3.3.7 - Пример схемы «снежинка»
На основании вышесказанного для предварительной подготовки данных с целью их оптимизации были разработаны многомерные модели данных в виде схем «звезда» и «снежинка».
|
|
|
Схема реализации многомерного представления данных для формирования гиперкуба «сводные данные по исполнителям» представлена на рисунке 3.3.8.
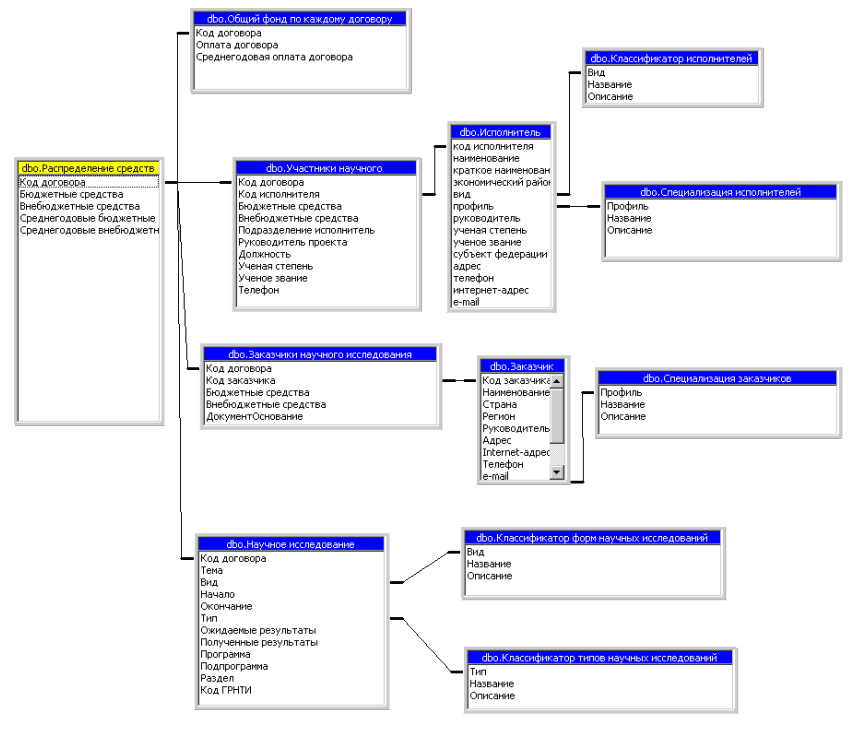
Рисунок 3.3.8 - Многомерная модель данных для гиперкуба«Сводные данные по исполнителям»
В представленной на рисунке 3.3.8 схеме основными таблицами измерений являются таблицы «Общий фонд по каждому договору», «Участники научного исследования», «Заказчики научного исследования», «Научное исследование». Таблица «Распределение средств» является таблицей фактов, связанной с таблицами измерений отношениями «один-ко-многим».
При формировании запросов к базе данных пользователю будут предложены следующие измерения: область знания, экономический район, профиль вуза, вид вуза, регион заказчика, страна заказчика, форма исследования, вид исследования.
Схема реализации многомерного представления данных для формирования гиперкуба «сводные данные по регионам мира» представлена на рисунке 3.3.9.
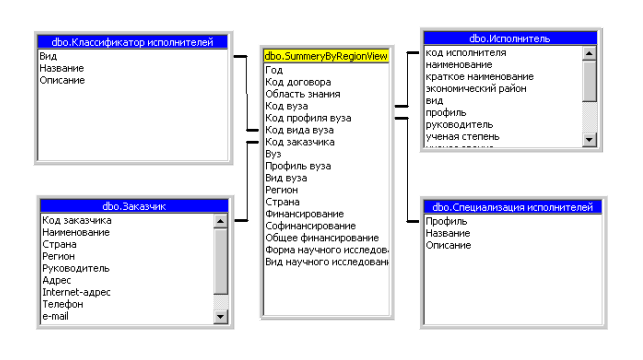
Рисунок 3.3.9 - Многомерная модель данных для гиперкуба«Сводные данные по регионам мира»
В схеме представленной на рисунке 3.3.9 таблицами измерений являются таблицы «Классификатор исполнителей», «Заказчик», «Исполнитель», «Специализация исполнителей».
При формировании запросов к базе данных пользователю будут предложены следующие измерения: наименование заказчика, наименование вуза, вид вуза, профиль вуза, год.
Схема реализации многомерного представления данных для формирования гиперкуба «Российская статистика довузовского обучения» представлена на рисунке 3.3.10.
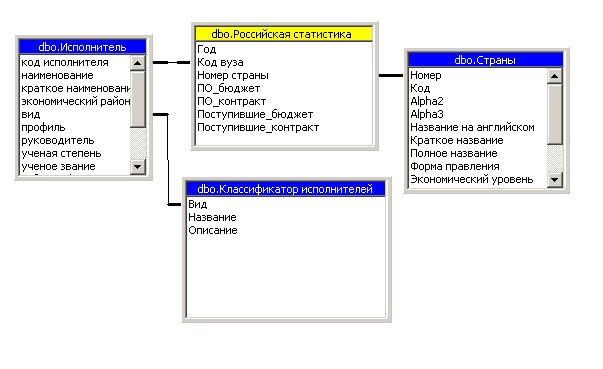
Рисунок 3.3.10 - Многомерная модель данных для гиперкуба«Российская статистика довузовского обучения»
Схема реализации многомерного представления данных для формирования гиперкуба «Российская статистика послевузовского обучения» представлена на рисунке 3.3.11.
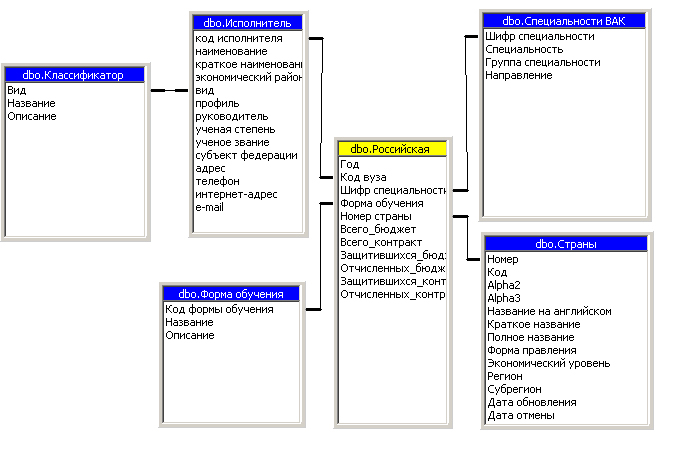
Рисунок 3.3.11 - Многомерная модель данных для гиперкуба«Российская статистика послевузовского обучения»
Схема реализации многомерного представления данных для формирования гиперкуба «Российская статистика вузовского обучения» представлена на рисунке 3.3.12.
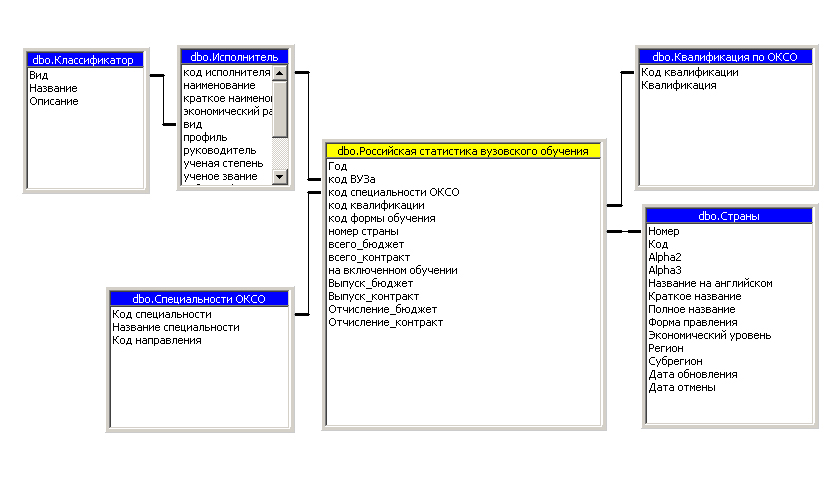
Рисунок 3.3.12 - Многомерная модель данных для гиперкуба«Российская статистика вузовского обучения»
Схема реализации многомерного представления данных для формирования гиперкуба «Зарубежная статистика послевузовского обучения» представлена на рисунке 3.3.13.
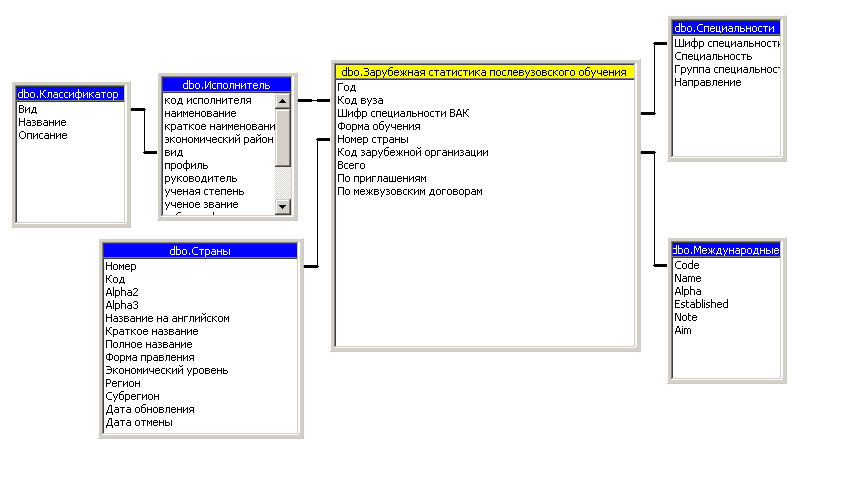
Рисунок 3.3.13 - Многомерная модель данных для гиперкуба«Зарубежная статистика послевузовского обучения»
Схема реализации многомерного представления данных для формирования гиперкуба «Зарубежная статистика сотрудников вузов» представлена на рисунке 3.3.14.
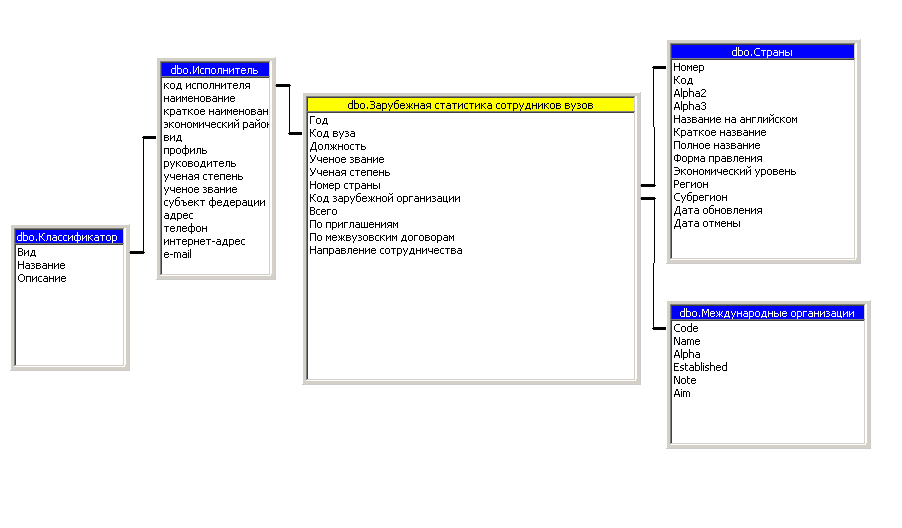
Рисунок 3.3.14 - Многомерная модель данных для гиперкуба«Зарубежная статистика сотрудников вузов»
Схема реализации многомерного представления данных для формирования гиперкуба «Зарубежная статистика вузовского обучения» представлена на рисунке 3.3.15.
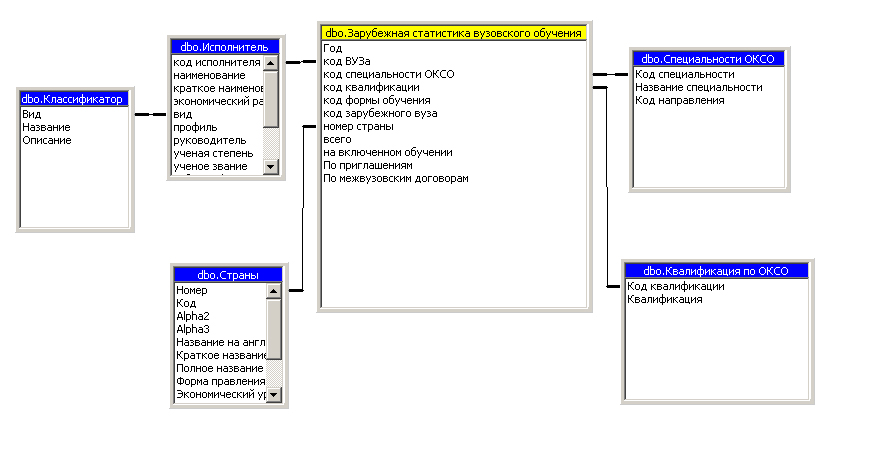 Рисунок 3.3.15 - Многомерная модель данных для гиперкуба«Зарубежная статистика вузовского обучения»
Рисунок 3.3.15 - Многомерная модель данных для гиперкуба«Зарубежная статистика вузовского обучения»
4 Разработка интерфейса WEB-приложения для аналитической обработки данных
Основной задачей дипломного проекта является разработка программного обеспечения для аналитической обработки информации о международном и научно-техническом и образовательном сотрудничестве вузов России на основе технологии OLAP. Разработанный интерфейс предоставляет конечному пользователю возможность определения структуры OLAP-куба, с которым он хочет работать и в графической форме результаты выводятся в виде таблиц и диаграмм. При запуске приложения оператор попадает на форму представленную на рисунке 4.1.1.
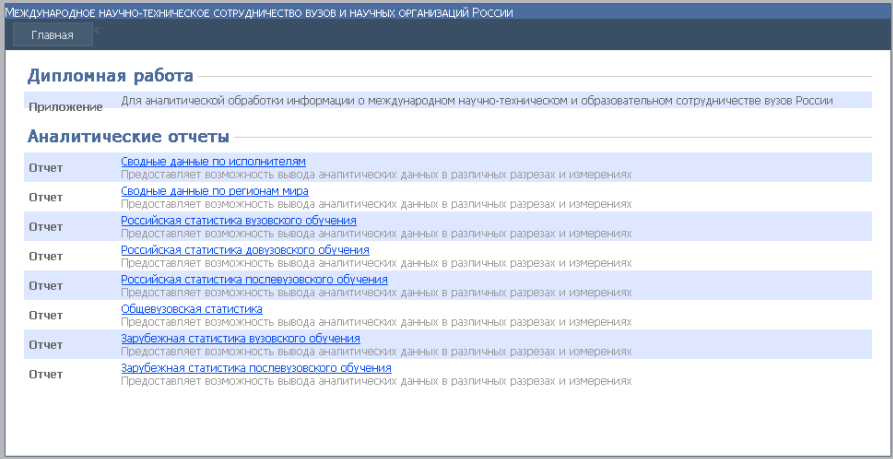
Рисунок 4.1.1 – Главная страница приложения
На основе рассмотренных в предыдущей главе многомерных моделей данных пользователь выбирает куб, с которым будет работать, руководствуясь желаемой областью анализа данных.
После выбора оператор попадает на одну из форм, общий вид которых рассмотрим на примере формы «Сводные данные по исполнителям», представленной на рисунке 4.1.2.
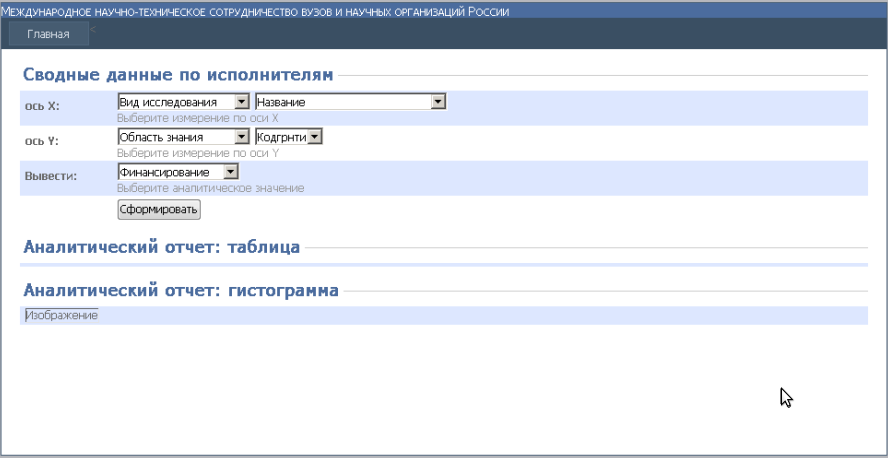
Рисунок 4.1.2 – Форма «Сводные данные по исполнителям»
По оси X и Y пользователь выбирает структуру формируемого куба. Выпадающие списки обеспечивают возможность выбора измерений, по которым будут формироваться результирующая таблица и гистограмма. Топология таблиц сложна, число связей велико, поэтому пользователю предлагается дополнительно выбрать значения выводимых полей таблиц измерений. На рисунке 4.1.3 продемонстрирован процесс выбора оператора. Для полноты информации при формировании запроса пользователю необходимо выбрать «меру», то есть непосредственно критерий, по которому будет заполняться матрица фактов выводимой таблицы. За это действие отвечает выпадающий список «Вывести».
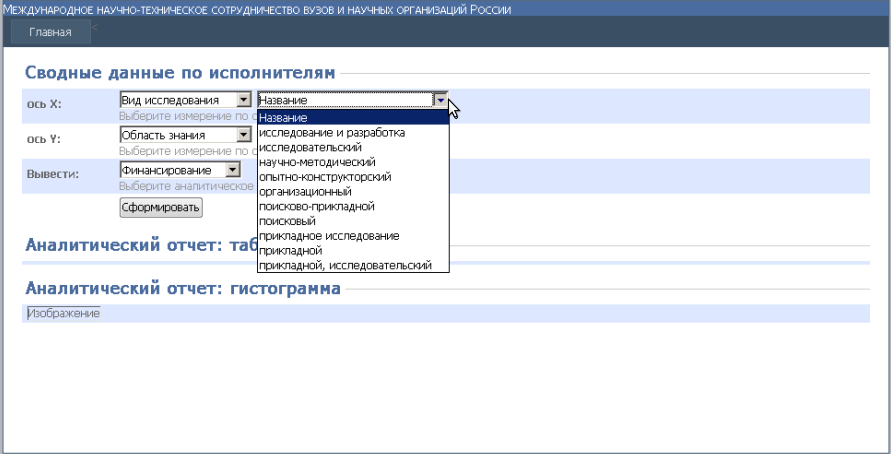
Рисунок 4.1.3 – Выпадающие списки на формах
Обработчик кнопки «Сформировать» формирует и отсылает запрос к SQL серверу, результатом которого является получение необходимого среза OLAP куба. На рисунке 4.1.4 представлен вариант отображения этого среза в виде таблицы, а на рисунке 4.1.5 в виде гистограммы.
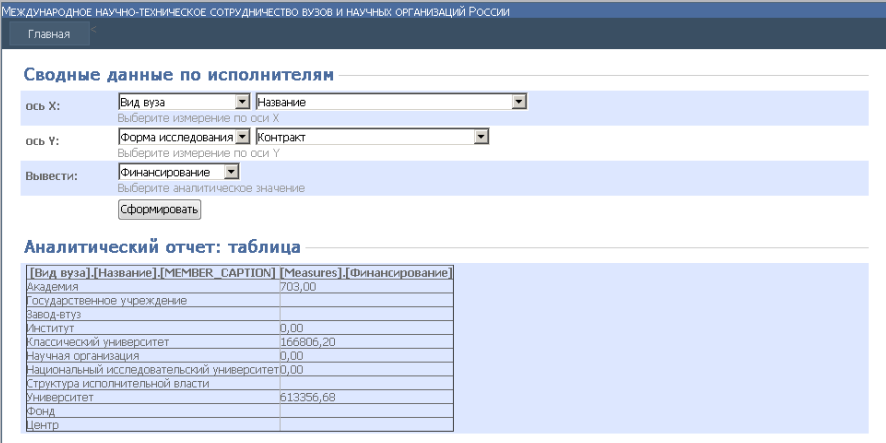
Рисунок 4.1.4 – Табличный вид отображения данных
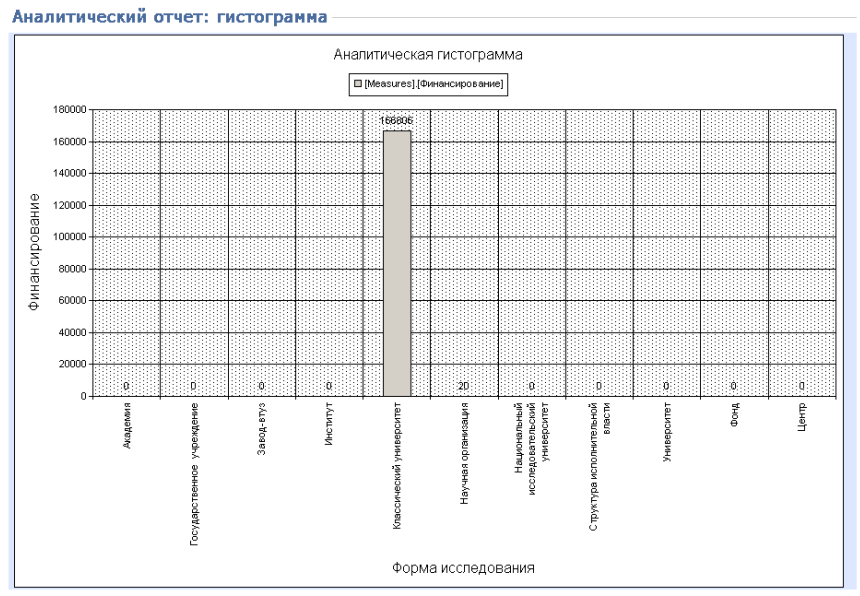
Рисунок 4.1.5 – Отображение данных в виде гистограммы
В качестве примера рассмотрим следующую ситуацию. Пользователю необходимо получить информацию о финансировании исследований, связанных с регионом заказчика и профилями вузов. Изначально оператора интересуют регионы мира с наибольшим финансированием по естественно-научному и гуманитарному профилям.
Порядок действий:
1. Запускаем приложение, выбираем «сводные данные по исполнителям».
2. По оси Х выбираем в качестве измерения «Регион заказчика», по оси Y выбираем в первом списке «Профиль вуза», во втором конкретизируем до «естественно-научный и гуманитарный».
3. В качестве меры нас интересует финансирование, поэтому в списке «Вывести» выбираем соответствующее поле.
4. Нажимаем кнопку «Сформировать». Результат в виде таблицы и диаграммы на рисунке 4.1.6.
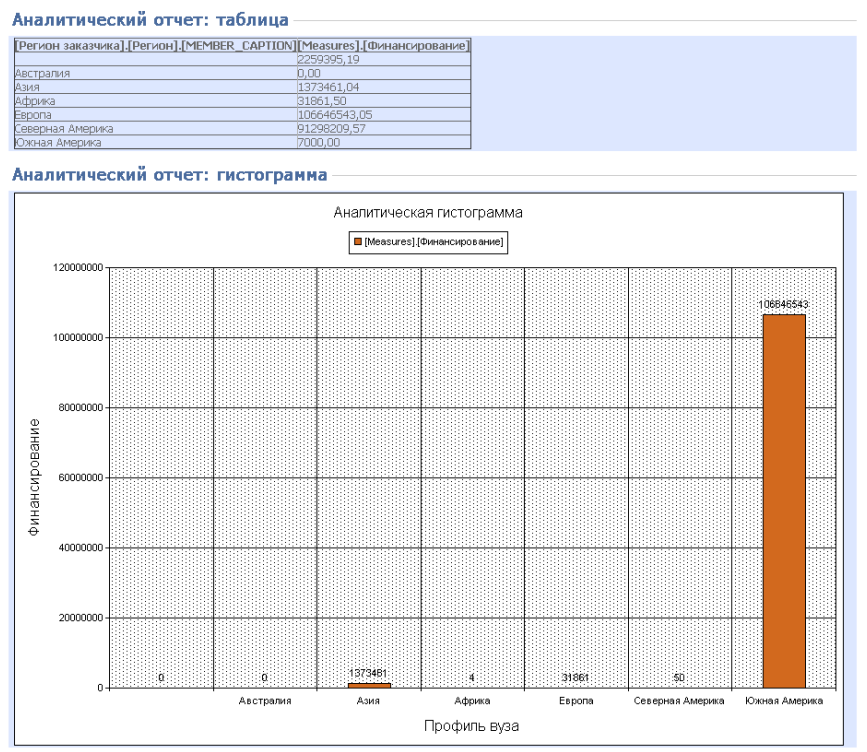
Рисунок 4.1.6 – Результат работы программы при выводе финансирования по регионам заказчиков и естественно-научным и гуманитарным профилям вузов
В рассматриваемом примере Южная Америка занимает лидирующую позицию по критерию финансирования.
Предположим, что теперь необходимо просмотреть информацию по финансированию проектов по регионам заказчиков по всем профилям вузов. Для этого будет достаточным в дополнительном выпадающем списке напротив оси Y сменить вариант «естественно-научный и гуманитарный» на «название». После этого получим результат в виде таблицы, представленной на рисунке 4.1.7 и в виде диаграммы, представленной на рисунке 4.1.8.
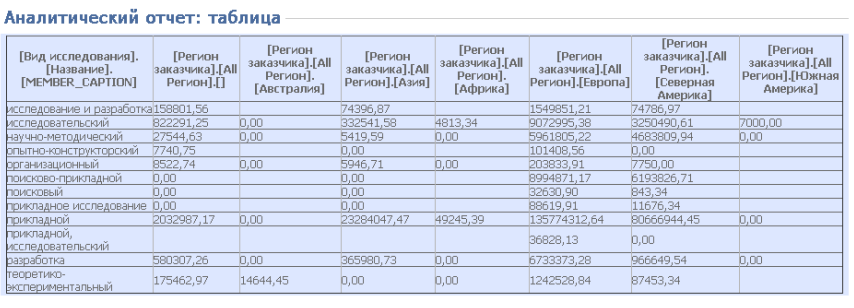
Рисунок 4.1.7 – Табличный вывод данных по регионам заказчиков и профилям вузов
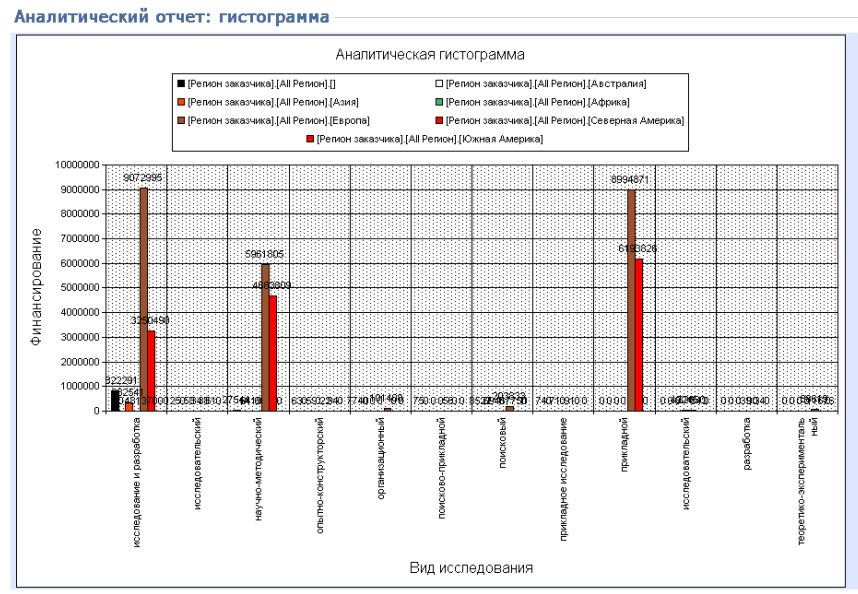
Рисунок 4.1.8 – Вывод данных в виде гистограммы по регионам заказчиков и профилям вузов
Для визуализации выборок при объемных таблицах данных на форме диаграммы предусмотрена легенда, благодаря которой значительно упрощается восприятие результирующей информации конечным пользователем. В рассматриваемом нами примере на диаграмме на рисунке 4.1.8 коричневым цветом обозначена Европа, которая занимает лидирующие позиции по финансированию в областях: исследование и разработка, научно-методическая, прикладная.
Для более детальной информации по финансируемым видам исследований в Европе достаточно просто подкорректировать измерения нового куба и получим результат на рисунке 4.1.9.
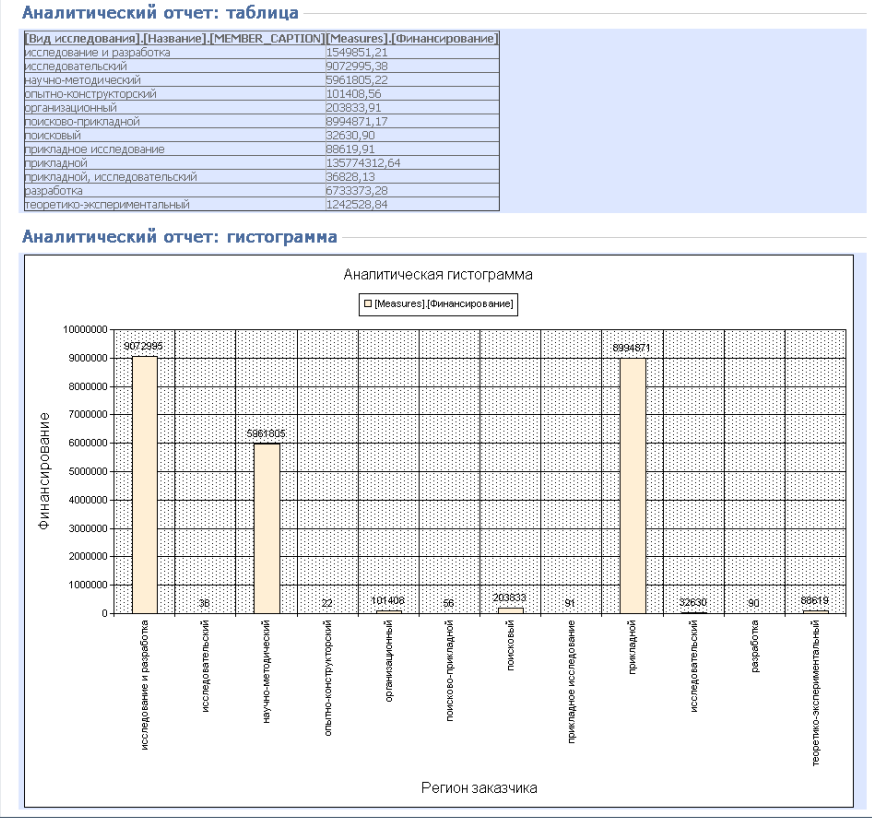
Рисунок 4.1.9 – Финансирование по видам исследований в Европе
Теперь пользователь может подробно ознакомиться с распределением финансирования средств по интересующему его региону по видам исследований.
Так как прикладной тип исследования является одним из доминирующих в данном примере, может появиться необходимость в просмотре профилей вузов, финансируемых по данному типу. Результаты подобной пользовательской выборки также легко получаются при смене формируемых измерений OLAP куба и представлены на рисунке 4.1.10
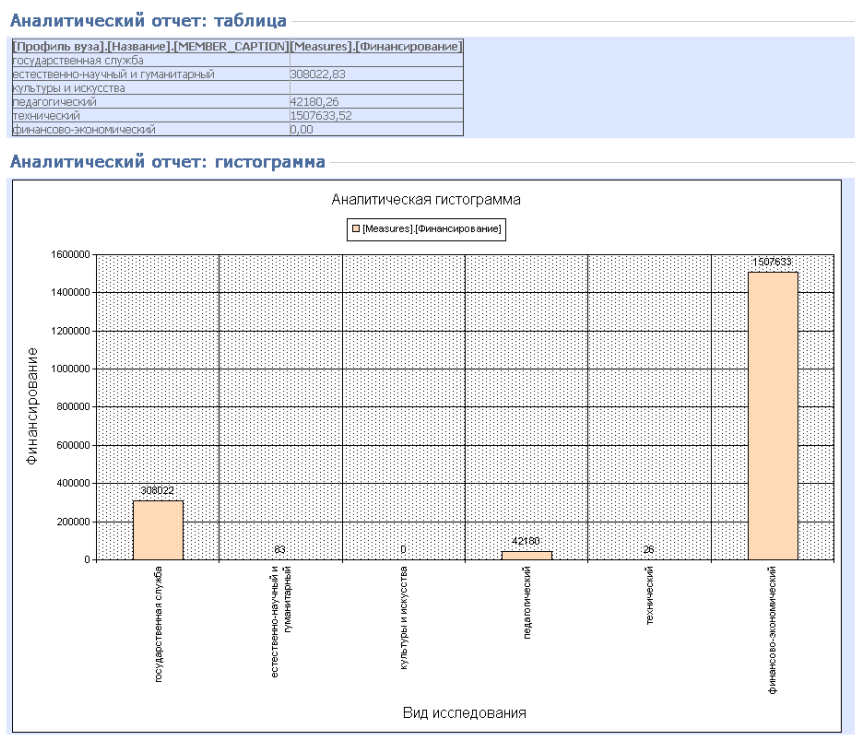
Рисунок 4.1.10 – Финансирование по профилям вузов в области прикладных исследований
Разработанный интерфейс предлагает пользователю обширный выбор вариантов формирования измерений гиперкуба для последующего вывода результатов в графической форме. Визуализация происходит как в масштабах всего множества полученных данных, так и локально в пределах среза куба для более детального рассмотрения. Использование легенд, цифровых сеток, отображений значений столбцов на диаграмме направлены на улучшение восприятия конечного оператора и оптимизации его дальнейшего принятия решений. Мягкий цветовой фон и отсутствие необходимости перезагрузки страницы направлены на повышение концентрации при работе пользователя. Интерфейс предельно прост и интуитивно понятен, полностью оптимизирован под выполняемые задачи. Решение отказаться от нагроможденности форм несколько лишило его гибкости, но привело к повышению скорости обработки действий оператора.
Разработка интерфейса осуществлена на базе технологии ASP.NET и компонентов библиотеки MS OWC. Реализация отображения графических изображений формируемых при помощи MS OWC происходит при помощи встроенного в ASP.NET обработчика HTTPhendler, которая компилируется при вызове этого файла во время формирования изображения в объекте Image. Таким образом, формирование картинки происходит “налету” и не требует предварительного формирования файла. После того как экземпляр класса библиотеки OWC11 сформирует графическое представление переданных результатов, он возвращает изображение вызывающему его объекту. В случае если построение графика не было завершено, программа не выполняет прорисовку графики, а в сессию передается сообщение об ошибке.
5 Разработка программного обеспечения WEB-приложения для аналитической обработки данных








