 2015-05-20
2015-05-20 15237
15237Диаграммы «сущность-связь» (ERD) предназначены для разработки моделей данных и обеспечивают стандартный способ определения данных и отношений между ними. С помощью ERD-диаграмм осуществляется детализация хранилищ данных моделируемой и проектируемой системы путем идентификации и документирования объектов (сущностей), важных для предметной области, свойств этих объектов (атрибутов) и их отношений с другими объектами (связей).
Нотация Чена
Нотация ERD-диаграмм была предложена Ченом. Нотация Чена предоставляет богатый набор средств моделирования данных, включая собственно ERD-диаграммы, а также диаграммы атрибутов и диаграммы категоризации. Эти диаграммные техники используются для моделирования и проектирования как реляционных, так и иерархических и сетевых баз данных.
Сущность представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, предметов, состояний, идей и т.п.), обладающих общими характеристиками (атрибутами). Любой объект системы может быть представлен только одной сущностью, которая должна быть уникально идентифицирована. При этом имя сущности должно отражать тип или класс объекта, а не его конкретный экземпляр (например, Город, а не Москва).
Отношение представляет собой связь между двумя и более сущностями. Именование отношения осуществляется с помощью грамматического оборота глагола (Имеет, Определяет, Можетвладеть и т.п.).
Другими словами, сущности представляют собой базовые типы информации, хранимой в базе данных, а отношения показывают, как эти типы данных взаимоувязаны друг с другом. Введение подобных отношений преследует две основополагающие цели:
- обеспечение хранения информации в единственном месте (даже если она используется в различных комбинациях);
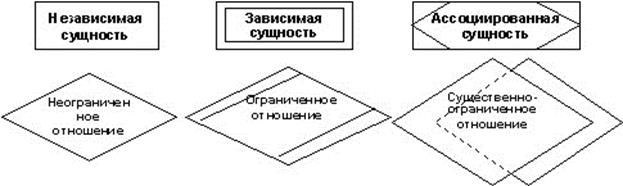
- использование этой информации различными приложениями. Символы ERD-диаграмм, соответствующие сущностям и отношениям, приведены на рис. 3.11.
 |
Независимая сущность представляет независимые данные, которые всегда присутствуют в системе. При этом отношения с другими сущностями могут как существовать, так и отсутствовать. В свою очередь, зависимая сущность представляет данные, зависящие от других сущностей в системе. Поэтому она должна всегда иметь отношения с другими сущностями. Ассоциированная сущность представляет данные, которые ассоциируются с отношениями между двумя и более сущностями.
Неограниченное (обязательное) отношение представляет собой безусловное отношение, т.е. отношение, которое всегда существует до тех пор, пока существуют относящиеся к делу сущности. Ограниченное (необязательное) отношение представляет собой условное отношение между сущностями. Существенно-ограниченное отношение используется, когда соответствующие сущности в системе взаимозависимы.
Для идентификации отношений, в которые вовлекаются сущности, используются связи. Каждая связь соединяет сущность и отношение и может быть направлена только от отношения к сущности. Значение связи характеризует ее тип и, как правило, выбирается из следующего множества:
{«0 или 1». «0 или более», «1», «1 или более», “p: q” (диапазон)}.
Пара значений связей, принадлежащих одному и тому же отношению, определяет тип этого отношения. Практика показала, что для большинства приложений достаточно использовать следующие типы отношений:
- 1*1 (один-к-одному). Отношения данного типа используются, как правило, на верхних уровнях иерархии модели данных, а на нижних уровнях встречаются сравнительно редко.
- 1*n (один-к-многим). Отношения данного типа являются наиболее часто используемыми.
- n*m (многие-к-многим). Отношения данного типа обычно используются на ранних этапах проектирования с целью прояснения ситуации. В дальнейшем каждое из таких отношений должно быть преобразовано в комбинацию отношений типов 1 и 2 (возможно, с добавлением вспомогательных сущностей и с введением новых отношений).
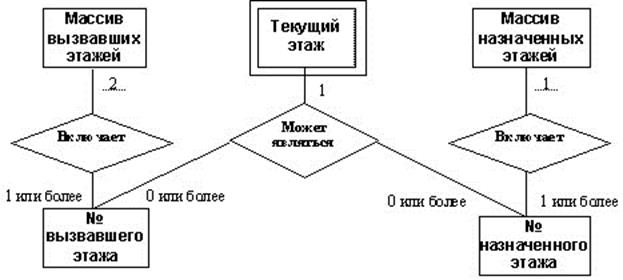
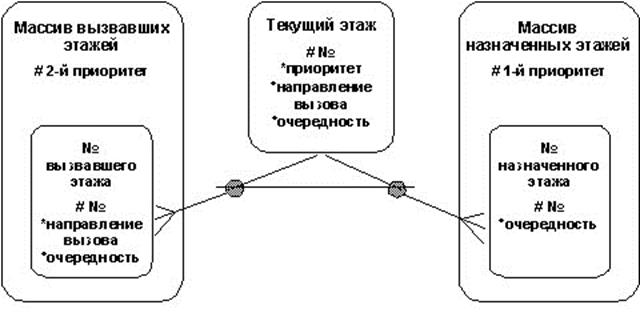
На рисунке 3.12 приведен пример диаграммы «сущность–связь», моделирующей отношения между сущностями, содержащимися в хранилищах системы управления лифтом, в нотации Чена.
 |
Каждая сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. При этом любой атрибут может быть определен как ключевой.
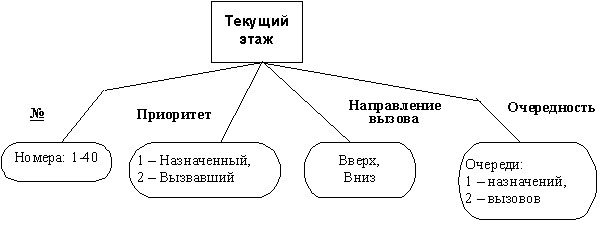
Детализация сущности осуществляется с использованием диаграммы атрибутов, которая раскрывает характеристики (атрибуты) сущности. Диаграмма атрибутов состоит из детализируемой сущности, соответствующих атрибутов и доменов, описывающих области значений атрибутов.
Пример диаграммы атрибутов, приведен на рис. 3.13. На диаграмме каждый атрибут представляется в виде связи между сущностью и соответствующим доменом, являющимся графическим представлением множества возможных значений атрибута. Все атрибутные связи имеют значения на своем окончании. Для идентификации ключевого атрибута используется подчеркивание имени атрибута.
 |
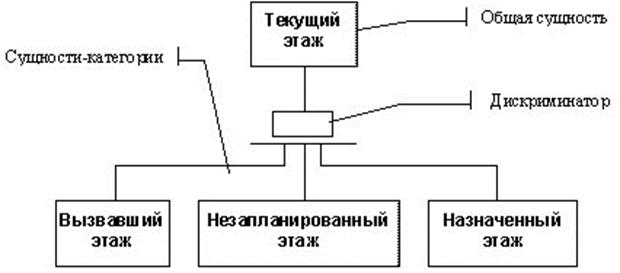
Сущность может быть разделена и представлена в виде двух или более сущностей-категорий, имеющих общие атрибуты и/или отношения. Эти атрибуты определяются однажды на верхнем уровне для разделяемой сущности (общей сущности) и наследуются на нижнем. Сущности-категории должны иметь и свои собственные атрибуты и/или отношения, а также, в свою очередь, могут быть декомпозированы своими сущностями-категориями на следующем уровне. На промежуточных уровнях декомпозиции одна и та же сущность может быть как общей сущностью, так и сущностью-категорией.
Для демонстрации декомпозиции сущности на категории используется диаграмма категоризации. Такая диаграмма содержит общую сущность, две и более сущности-категории и специальный узел-дискриминатор, который описывает способы декомпозиции сущностей (см. рис. 3.14).
 |
Существуют 4 возможных типа дискриминатора:
- Е/М (exclusive/mandatory) – полное и обязательное вхождение – сущность должна быть одной и только одной из категорий декомпозиции.
- Е/0 (exclusive/optional) – полное и необязательное вхождение – сущность может быть одной и только одной из категорий декомпозиции.
- VM (inclusive/mandatory) – неполное и обязательное вхождение –сущность должна быть по крайней мере одной из категорий декомпозиции.
- I/O (inclusive/optional) – неполное и необязательное вхождение – сущность может быть, по крайней мере, одной из категорий декомпозиции.
Нотация Баркера
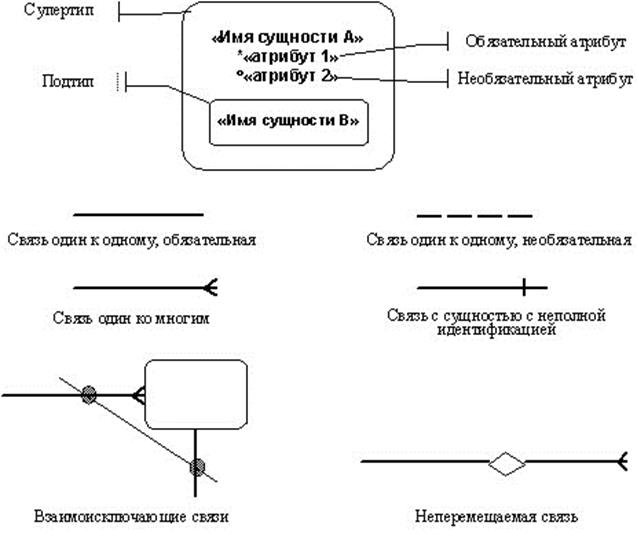
Дальнейшее развитие диаграммы «сущность-связь» получили в работах Баркера, предложившего оригинальную нотацию (см. рис. 3.15), которая позволила интегрировать средства описания моделей Чена.
 |
В нотации Баркера используется только один тип диаграмм: собственно ERD-диаграммы. Сущность на ERD-диаграмме представляется прямоугольником любого размера, содержащим внутри себя имя сущности, список имен атрибутов (возможно, неполный) и указатели ключевых атрибутов (знак «#» перед именем атрибута). Понятия категории и общей сущности Чена заменяются Баркером на эквивалентные понятия подтипа и супертипа соответственно. Атрибуты сущностей могут быть обязательными и необязательными. Кроме того, атрибуты могут быть описательными (дескрипторами сущности) или входить в состав первичного ключа (уникального идентификатора сущности). Сущность, как правило, может быть полностью идентифицирована своим первичным ключом. Однако, могут быть случаи, когда в идентификации данной сущности участвуют также атрибуты другой сущности-родителя. Кроме первичных ключей могут использоваться альтернативные (возможные) ключи.
Все связи являются бинарными и представляются линиями, соединяющими родительскую сущность с одной или несколькими сущностями-потомками. Для связей должно быть определено имя (выражаемое грамматическим оборотом глагола), степень множественности (один или много объектов участвуют в связи) и степень обязательности (т.е. обязательная или необязательная связь между сущностями). Для множественной связи линия присоединяется к прямоугольнику сущности в трех точках, а для одиночной связи – в одной точке. При обязательной связи рисуется непрерывная линия до середины связи, при необязательной – пунктирная линия. Могут иметь место ситуации, при которых связи данной сущности рассматриваются как взаимоисключающие. Кроме того, связь может быть рекурсивной, а также неперемещаемой, если экземпляр сущности не может быть перенесен из одной связи в другую.
На рис. 3.16 приведен пример ERD-диаграммы, моделирующей отношения между сущностями, содержащимися в хранилищах системы управления лифтом (см. рис. 3.12), в нотации Баркера.

Построение модели
Разработка ERD-диаграммы включает следующие основные этапы [20]:
- Идентификация сущностей, их атрибутов, а также первичных и альтернативных ключей.
- Идентификация отношений между сущностями и указание типов отношений.
- Разрешение неспецифических отношений (отношений n*m).
Рассмотрим эти этапы в соответствии с работой [20] более подробно.
1-й этап построения ERD-диаграммы (или модели данных) является определяющим. Исходной информацией для данного этапа служит содержимое хранилищ данных, зависящее от входящих и выходящих потоков данных, представленных на DFD-диаграмме.
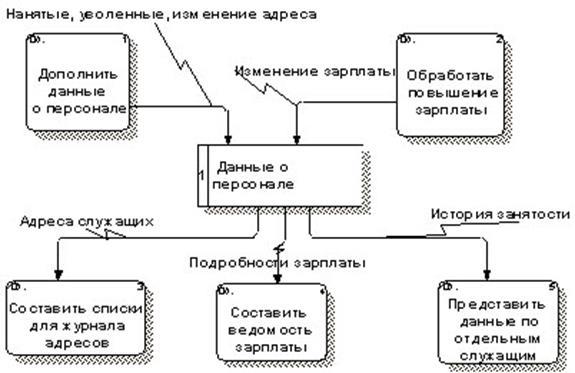
Таким образом, для построения ERD-диаграммы необходимо иметь предварительно построенную DFD-диаграмму. На рисунке 3.17 приведен фрагмент DFD-диаграммы, моделирующей деятельность бухгалтерии предприятия по ведению данных о персонале и начислению зарплаты.
 |
ERD-диаграмма является результатом анализа DFD-диаграммы. При этом первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища. Из диаграммы на рис. 3.17 следует, что хранилище должно содержать информацию о всех сотрудниках: имена, адреса, должности, оклады и т.д. Рассмотрим данные и их структуры, содержащиеся во входных и выходных потоках:
Таблица 3.4. Структуры данных для работы бухгалтерии.
| ВХОДНЫЕ СТРУКТУРЫ ДАННЫХ Нанятые Дата_найма Фамилия таб_номер адрес должность начальная_зарплата Уволенные Фамилия таб_номер Изменение_адреса Фамилия таб_номер старый_адрес новый_адрес Изменение_зарплаты Фамилия таб_номер старая_зарплата новая_зарплата дата_изменения | ВЫХОДНЫЕ СТРУКТУРЫ ДАННЫХ Адрес_служащего фамилия адрес Подробности_з/пл фамилия таб_номер текущая_зарплата История_занятости фамилия таб_номер дата_наима история_карьеры * должность дата_изменения история_зарплаты * зарплата |
Сравнивая входные и выходные структуры данных, отметим следующее:
- Поле «адрес» (элемент структуры входного потока «Нанятые») хранит текущий адрес сотрудника, а структура входного потока «Изменение адреса» хранит еще и старый адрес, что не является необходимым, с точки зрения выходных потоков.
- Для формирования структуры «История зарплаты» (составной части выходного потока «История занятости»), наоборот, требуется перечислить все оклады сотрудника, поэтому необходимо иметь набор, состоящий из пар («зарплата, дата»), а не просто «старая_зарплата» и «новая_зарплата» (как в структуре входного потока «Изменение зарплаты»).
- Аналогичная ситуация и со структурой «Историей карьеры» (другой составной части структуры выходного потока «История занятости»). Отметим, что на диаграмме вообще отсутствует входной поток со структурой данных, определяющей изменения в должности, что является серьезным упущением функциональной модели.
- Отметим, что изменение в должности обычно (но не всегда) соответствует изменению в зарплате.
С учётом этих моментов первый вариант схемы хранилища (базы данных) может выглядеть следующим образом:

