 2015-05-10
2015-05-10 608
608#include "stdafx.h"
using namespace System;
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
void serialmxv(int m, int n, double *a, double * b, double * c);
int main(int argc, char *argv[])
{
double *a,*b,*c;
int i, j, m, n;
printf("Please give m and n: ");
scanf("%d %d",&m,&n);
if ((a=(double *)malloc(m*sizeof(double))) == NULL)
perror("memory allocation for a");
if ((b=(double *)malloc(m*n*sizeof(double))) == NULL)
perror("memory allocation for b");
if ((c=(double *)malloc(n*sizeof(double))) == NULL)
perror("memory allocation for c");
printf("Initializing matrix B and vector c\n");
for (j=0; j<n; j++)
c[j] = 2.0;
for (i=0; i<m; i++)
for (j=0; j<n; j++)
b[i*n+j] = i;
DateTime dt1 = DateTime::Now;
printf("Start %s \n", dt1.ToString());
printf("Executing mxv function for m = %d n = %d\n",m,n);
serialmxv(m, n, a, b, c);
DateTime dt2 = DateTime::Now;
printf("End %s \n", dt2.ToLongTimeString());
Int64 t = dt2.Ticks - dt1.Ticks;
printf("Ticks = %s \n", t.ToString());
for(i=0; i<n; i++)
printf("a%d %f\n",i, a[i]);
free(a);free(b);free(c);
return(0);
}
void serialmxv(int m, int n, double * a, double * b, double * c)
{
int i, j, p;
for (i=0; i<m; i++)
{
a[i] = 0.0;
for (j=0; j<n; j++)
a[i] += b[i*n+j]*c[j];
}
}
Параллельные способы вычислений.
В нижеописанном варианте принимается во внимание отсутствие зависимостей между вычислениями соседних продукций, таким образом каждая продукция может вычисляться отдельным процессором. Распараллеливание проводится по индексу рядков. Схема представлена на рис.2.
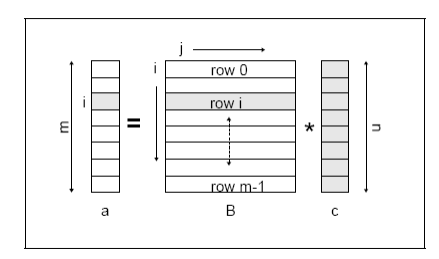
Рис.2. Графическое представление перемножение матрица-вектор на базе использования индекса строк.
OpenMP реализация операции перемножения матрица-вектор показана ниже.
void ompmxv(int m, int n, double * a, double * b, double * c)
{
int i, j, p;
#pragma omp parallel shared(m,n,a,b,c, p) private(i,j) num_threads(10)
{
#pragma omp for
for (i=0; i<m; i++)
{
a[i] = 0.0;
for (j=0; j<n; j++)
a[i] += b[i*n+j]*c[j];
}
}
}
Приложение Г
Пример реализации комманды сложения массивов из 4-х чисел с плавающей точкой.
Для сложения чисел используется комманда addps(сложение упакованных чисел с плавающей точкой).
void sse()
{
float a[4] = {2.0, 4.9, 5.8, 6.1};
float b[4] = {2.0, 2.0, 2.0, 2.0};
_asm{
movups xmm0, a; //load a to 128-bit register
movups xmm1, b;
addps xmm0, xmm1;
movups a, xmm0; //store result in memory
}
for (int i=0; i<=3; i++)
printf("%f\n",a[i]);
}
Приложение Д
Для измерения времени выполнения блока программы рекомендуется использовать следующий блок кода.
Diagnostics::Stopwatch^ oStopWatch =
gcnew Diagnostics::Stopwatch;
oStopWatch->Start();
//…Work region…
Int64 oElapsedTicks = oStopWatch->ElapsedTicks;
cout <<"Time "<< oElapsedTicks <<" ticks";








