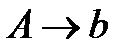Компиляция текста на ограниченном естественном языке во внутримашинное представление – составная часть интеллектуальных информационных систем. В упрощенном варианте она организуется в два этапа: 1) лексический анализ текста и 2) синтаксический анализ текста.
Основная задача первого этапа установить факт использования в тексте только «разрешенных» лексем из предварительно сформированного в памяти компьютера машинного словаря. Если проверяемая лексема есть в словаре, то она заменяется на специальное кодовое обозначение, взятое из тог же словаря. Если проверяемой лексемы в словаре нет, то она считается ошибочной, выдается сообщение об ошибке и весь текст считается ошибочным, подлежащим исправлению. Пусть на входе компилятора есть следующий текст на ограниченном естественном языке:
«быть (судно) иметь имя (агат) (иметь параметр (длина) иметь меру (метр) иметь значение (75))(иметь параметр (ширина) иметь меру (метр) иметь значение(25)) (иметь параметр (осадка) иметь меру (метр) иметь значение (5,5)) (иметь характеристику (тип) иметь значение (РТМ))».
При этом в памяти компьютера заблаговременно сформирован машинный словарь из табл.10.
Тогда после завершения лексического анализа текст будет преобразован в следующее внутримашинное представление:
«RO1 (XP13) RO2 (XИ1) (RO3 (ХП9) RO6 (XM3) RO5 (75))(RO3 (ХП14) RO6 (ХМ3) RO5(25)) (RO3(ХП11) RO6 (ХМ3) RO5 (5,5)) (RO4 (ХХ13) RO5 (XЗ26))».
В ходе выполнения на втором этапе компиляции синтаксического анализа, должен быть установлен факт корректности текста с точки зрения его синтаксиса, который задан в табл. 10. В этой связи рекомендуется следующий порядок действий. Предварительно синтаксис должен быть записан в терминах S-грамматики. Для этого удобно результат лексического анализа записать в следующем виде:
«RO1 (XP) RO2 (XИ) (RO3 (ХП) RO6 (XM) RO5 (75))(RO3 (ХП) RO6 (ХМ) RO5(25)) (RO3(ХП) RO6 (ХМ) RO5 (5,5)) (RO4 (ХХ) RO5 (XЗ))».
В последнем представлении из знаков-лексем удалены идентифицирующие коды и оставлены только коды функциональных классов лексем. Тогда оставшиеся обозначения, включая круглые скобки, могут рассматриваться как элементы алфавита терминальных символов:
«‘RO1’ (‘XP’) ‘RO2’ (‘XИ’) (‘RO3’ (‘ХП’) ‘RO6’ (‘XM’) ‘RO5’ (‘XЗ’))(‘RO3’ (‘ХП’) ‘RO6’ (‘ХМ’) ‘RO5’(‘ХЗ’)) (‘RO3’(‘ХП’) ‘RO6’ (‘ХМ’) ‘RO5’ (‘ХЗ’)) (‘RO4’ (‘ХХ’) ‘RO5’ (‘XЗ’))».
При этом обратите внимание, что все числовые значения замены также на код функционального класса – «значение», т.е. на ‘ХЗ’. Это сделано с целью упростить синтаксический анализ, исключив из рассмотрения синтаксис чисел.
Далее необходимо определить три оставшиеся объекта S-грамматики: словарь нетерминальных символов, начальный символ (аксиому) и правила вывода.
Автоматизация процесса нисходящего синтаксического анализа основывается на построении распознавателя, использующего свойства формальной грамматики. Такой распознаватель строится как автомат с магазинной памятью.
Описание поведения магазинного автомата заключается в том, что для каждой комбинации его состояния, входного символа и символа в вершине стека задается новое состояние перехода и одна или несколько операций.
Принципы работы распознавателя рассмотрим на примере S-грамматики. Перечислим ограничения S-грамматики: правая часть каждого правила должна начинаться с терминального символа; для двух любых правил, имеющих одинаковые левые части, начальные терминальные символы должны быть различны; не допускаются правила с пустой правой частью. Следующая грамматика является S-грамматикой:
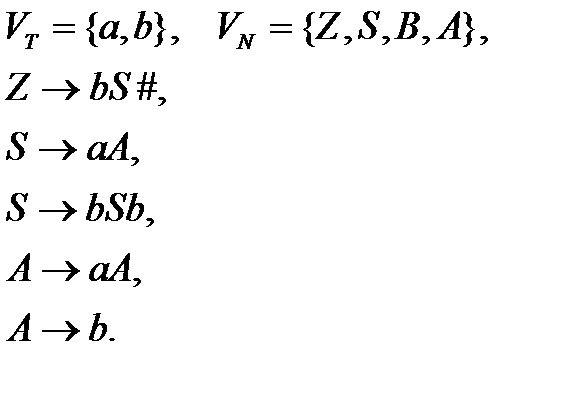
Грамматика производит цепочки вида bbbaaaaabbb, где символ a повторяется не менее одного раза, а количество символов b справа и слева равны:
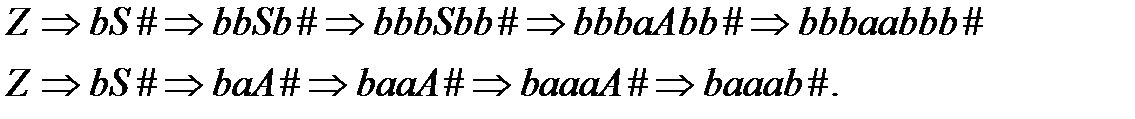
Ниже, на рис. 45 приведено дерево синтаксического разбора.
| Рис. 45 – Дерево синтаксического разбора
|
После определения роли и места стека в процессе функционирования магазинного автомата алгоритм его работы содержит следующую последовательность шагов:
1. Е исходном состоянии в стек записывается начальный нетерминал;
2. Если одновременно пусты стек и входная строка, то распознавание считается выполненным успешно;
3. Если один из них пуст, а другой – нет, то распознаватель обнаруживает синтаксическую ошибку;
4. если в вершине стека находится терминальный символ, совпадающий с очередным символом входной строки, то оба они исключаются из стека и строки соответственно;
5. Если в вершине стека находится терминальный символ, не совпадающий с очередным символом входной строки, то распознаватель обнаруживает синтаксическую ошибку;
6. Если в вершине стека находится нетерминальный символ, то ищется правило, у которого левая часть совпадает с этим нетерминалом, а очередной символ строки совпадает с первым символом правой части правила.В этом случае в стеке производится замена нетерминала левой части правила на правую часть.
На рис. 46 дан пример работы распознавателя на цепочке bbaabb (принадлежит языку).
| Рис. 46 — Пример работы распознавателя для цепочки bbaabb
|
На рис. 47 приведена реализация распознающего автомата со стековой памятью на языке Рефал Плюс.
| $module Mod23;
$use StdIO;
$func Fun0 e = e;
$func Fun1 e = e;
$func Fun2 e = e;
$func Fun3 e = e;
$func Main = e;
// Шаг 1 алгоритма
Main
= < Fun0(<ReadLine>)('Z') >;
Fun0
{
t1 ('Z')= <Fun3 t1 ('bS#'('ZSAB'))(('S-aA')('S-bSb')('A-aA')('A-b'))>;
};
//1 предложение -шаг 4; 2- шаг 5; 3,4 - шаг 3
Fun1 {
(s1 e2)(s1 e3 t6)t5 = <Fun3 (e2)(e3 t6)t5>;
(s1 e2)(s4 e3 e6)t5 = <PrintLn 'СИНТАКСИЧЕСКАЯ ОШИБКА'>;
()(e1 t6)t5 = <PrintLn 'СИНТАКСИЧЕСКАЯ ОШИБКА'>;
(e1)(t6)t5 = <PrintLn 'СИНТАКСИЧЕСКАЯ ОШИБКА'>;
e1 = <PrintLn 'СИНТАКСИЧЕСКАЯ ОШИБКА'>;
};
// 1 предложение - шаг 6
Fun2
{
(s1 e2)(s3 e4 t8)(e5(s3'-'s1 e6)e7) = <Fun3(s1 e2)(s1 e6 e4 t8)(e5(s3'-'s1 e6)e7)>;
e1 = <PrintLn 'СИНТАКСИЧЕСКАЯ ОШИБКА'>;
};
// 1 предложение - шаг 2
Fun3
{
()('#'t2) t5 = <PrintLn 'ЦЕПОЧКА ПРИНАДЛЕЖИТ ЯЗЫКУ'>;
t1 (s2 e6(e3 s2 e4)) t5 = < Fun2 t1 (s2 e6(e3 s2 e4)) t5>;
e1 = < Fun1 e1 >;
};
|
| Рис. 47 – Реализация распознающего автомата на языке Рефал Плюс
|
Функция Main считывает цепочку символов, для которой нужно определить принадлежность к языку, формируемому рассмотренной выше грамматикой. Две скобки в аргументе функции Fun0 – это строка и стек в порядке слева-направо. В стек сразу же заносится начальный символ – ' Z ’. Функция Fun0 приписывает к этим двум скобкам справа еще и скобку с правилами вывода S -грамматики. В скобки стека включена еще пара структурных скобок с алфавитом нетерминальных символов для проверки на шаге 6 алгоритма. Далее для анализа текста модуля можно руководствоваться вставленными в текст комментариями.
 2015-05-10
2015-05-10 288
288