2015-05-13
2015-05-13 704
704Кластерный анализ - метод многомерного статистического анализа для решения задачи классификации данных.(Синонимы: численная таксономия, численная классификация, распознавание с самообучением и т.д.) Трион в 1939 г. определил предмет кластерного анализа и сделал его описание (Cluster – гроздь, скопление). Задача классификации данных и выявления соответствующей структуры в ней. Результат решения - разбиение множества исследуемых объектов и признаков на однородные в некотором понимании группы, или кластеры
Предполагается что, 1)выбранные характеристики допускают в принципе желательное разбиение на кластеры;2)единицы измерения (масштаб) выбраны правильно.
Данные нормируют вычитанием среднего и делением на среднеквадратичное отклонение, так что дисперсия становится равной единицы, а математическое ожидание - нулю 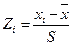
3)объекты представляются как множество точек в многомерном евклидовом пространстве; 4)каждый объект принадлежит одному и только одному подмножеству разбиения; 5) Происходит объединение объектов, схожих по всей совокупности факторов, и замена их некоторым усредненным объектом, что исключает дублирование данных; 6)объекты, принадлежащие одному и тому же кластеру - сходны, в то время, как объекты, принадлежащие разным кластерам - разнородны
I = { I1, I2,..., In } - n объектов
C = (C1, C2,..., Cp)т- p наблюдений показателей (характеристик), которыми обладает каждый объект из I
xij - результат измерения j -й характеристики объекта Ii
X = { X1, X2,..., Xn } - множество векторов измерений для множества объектов I
Неотрицательная величина d (Xi, Xj) называется функцией расстояния (метрикой), если выполняются следующие условия: 1) d (Xi, Xj) ³ 0 для всех Xiи Xj; 2) d (Xi, Xj) = 0 только тогда, когда Xi= Xj;
3) d (Xi, Xj) = d (Xj, Xi) для всех Xiи Xj; 4)d (Xi, Xj) £ d (Xi, Xk) + d (Xk, Xj), где Xi, Xiи Xk - любые три вектора из p-мерного евклидова пространства
Меры однородности объектов: 1. Евклидово расстояние dE (Xi, Xj) = 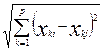
2. Линейное расстояние (хеммингово)d1 (Xi, Xj) = 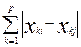
3. Sup-норма (расстояние Чебышева)d∞ (Xi, Xj) = sup {| xik- xkj|}, k = 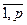
4.Обобщенное степенное растояние Минковскогоdp(Xi, Xj) = 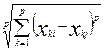
5. Расстояние Махаланобиса dM(Xi, Xj) = (Xi - Xj)т W -1(Xi - Xj), где W -1 - матрица, обратная к матрице рассеяния dM (Xi, Xj) = 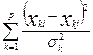
6. Манхетеннское («расстояние городских кварталов») 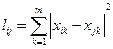
7.обобщенное расстояние Колмогорова (Power distance) 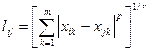
Вычисления расстояния между качественными и количественными, а также между двумя качественными признаками: качественный признак, имеющий m значений, рассматривается как набор m независимых бинарных переменных, обозначения состояния которых 0 и 1 считаются действительными числами.
Стратегии объединения кластеров:
1.Стратегия ближайшего соседа 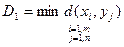
2.Стратегия дальнего соседа (метод «полных связей») 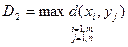
3.Стратегия группового среднего (метод «средней связи») 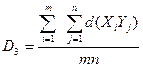
4.Центроидная стратегия («центроидный метод») 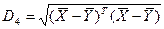 ;
; 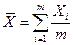 ;
; 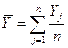
5. Стратегия, основанная на приращении суммы квадратов 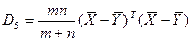
Решением задачи кластерного анализа являются разбиения, удовлетворяющие некоторому критерию оптимальности. Этот критерий может представлять собой некоторый функционал, выражающий уровни желательности различных разбиений и группировок, который называют целевой функцией.
Например, в качестве целевой функции может быть взята внутригрупповая сумма квадратов отклонения: 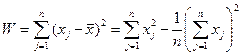 ,где xj - представляет собой измерения j -го объекта.
,где xj - представляет собой измерения j -го объекта.
Критерии построения разбиения:
1) минимизация внутриклассовой инерции. Расстояние между классами определяется как разность моментов инерции двух последовательных разбиений, одно из которых получено из другого объединением рассматриваемых классов
2) минимизация полной инерции при объединении двух классов. Расстояние между классами определяется как момент инерции их объединения
3) минимизация дисперсии объединения двух классов. Расстояние между классами - дисперсия объединенного класса
Достоинства:
1)позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков;
2)не накладывает никаких ограничений на вид рассматриваемых объектов, позволяет рассматривать множество исходных данных практически произвольной природы;
3)позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы информации, делать их компактными и наглядными.
Недостатки и ограничения:
1)состав и количество кластеров зависит от выбираемых критериев разбиения;
2)при сведении исходного массива данных к более компактному виду могут возникать определенные искажения, а также могут теряться индивидуальные черты отдельных объектов за счет замены их характеристиками обобщенных значений параметров кластера
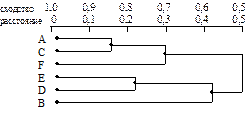 Дендограмма
Дендограмма
Иерархические агломеративные методы: 1) Для n объектов
вычисляются все n (n - 1) / 2 расстояний, и два наиболее близких
объекта объединяют в один кластер.
2)При этом число объектов становится равным (n - 1), причем один кластер содержит два объекта, а (n - 2) остальных - по одному.
3) Далее необходимо определить подходящую меру различия между первым классом и остальными (n - 2) объектами, а на более поздних стадиях также определять расстояния между объектом и кластером любого размера, а также между двумя кластерамти.
4) На каждом шаге классификации осуществляется то объединение, для которого мера различия наименьшая среди всех оставшихся к даному шагу.
5) Мера различия должна быть такой, чтобы объект мог рассматриваться как кластер из одного элемента.