 2014-02-02
2014-02-02 579
579 WW – это глобальная гипертекстовая система, организованная на базе Интернета. WWW представляет собой механизм, при помощи которого связывается информация, доступная посредством многочисленных Web-серверов во всем мире. Web-сервер – это программа, которая «умеет» получать http-запросы и выполнять в соответствии с этими запросами определенные действия, например, запускать приложения и генерировать документы.
WW – это глобальная гипертекстовая система, организованная на базе Интернета. WWW представляет собой механизм, при помощи которого связывается информация, доступная посредством многочисленных Web-серверов во всем мире. Web-сервер – это программа, которая «умеет» получать http-запросы и выполнять в соответствии с этими запросами определенные действия, например, запускать приложения и генерировать документы.
Документ, доступный через Web, называют Web-страницей, а группы страниц, объединенные общей темой и навигационно, – Web-узлами, или Web-сайтами. Один аппаратный Web-сервер может содержать несколько Web-сайтов, но возможна и обратная ситуация, когда огромный Web-сайт может поддерживаться группой Web-серверов (компьютеров).
Для того чтобы лучше понять идею организации Всемирной паутины, обратимся к рис. 2, на котором показан пример использования WWW для поиска информации о новостях. Предположим, что пользователю, проживающему в США, необходимо узнать последние московские новости, и он не знает адреса сервера, на котором можно найти эту информацию. Вполне вероятно, что для того, чтобы получить необходимые данные, он набирает известный ему адрес Web-сайта, который физически расположен на компьютере в США и посвящен теме «Новости в мире». Очевидно, что на одном сервере не могут храниться данные о местных новостях всех уголков земного шара.
При этом возможно, что у наиболее важных новостей мирового значения на сервере есть ссылки на новостные сайты, актуальные для разных регионов. Вполне вероятно, что, выбрав ссылку «Европа», пользователь соединится уже с другим компьютером, расположенным где-то в Европе (рис. 2). Предположим, что на странице европейского сайта есть ссылка на Россию. По ссылке «Россия» можно соединиться с сервером в России. Вероятно, по ссылке «Москва» на этом сайте пользователь получит необходимую информацию, а возможно, соединится с четвертым сервером, который представит необходимую ему информацию. Таким образом, уточняя и детализируя информацию, можно получить новости конкретного района.
Важно отметить, что в представленном на рисунке примере пользователь обращается с запросами к разным серверам и при переходе с одного сервера на другой ему не нужно каждый раз задавать адреса серверов и тем более знать о том, где они физически находятся. В этом случае говорят, что процедура происходит прозрачно для пользователя, то есть пользователь воспринимает весь процесс так, как если бы все полученные им страницы находились на его собственном компьютере. Таким образом, процесс просмотра информации можно сравнить с перелистыванием страниц огромной книги на одном рабочем столе по принципу «нажми и получи».
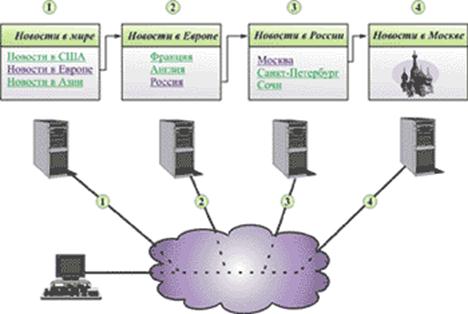 Рис.2.
Рис.2.
Процесс перемещения по документам с помощью гипертекстовых ссылок получил в обиходе название навигации, или серфинга.
Тот факт, что серфинг не требует знаний о местоположении искомых документов, как раз и является основным удобством и причиной популярности службы WWW.








