 2015-01-30
2015-01-30 1357
1357Построение оптимального кода Хаффмена (n,P)
Обозначим
n – количество символов исходного алфавита
P – массив вероятностей, упорядоченных по убыванию
C – матрица элементарных кодов
L – массив длин кодовых слов
Huffman(n,P)
IF (n=2) C[1,1]:=0, L[1]:=1
C[2,1]:=1, L[2]:=1
ELSE q:=P[n-1]+P[n]
j:=Up(n,q) <поиск и вставка суммы>
Huffman(n-1,P)
Down(n,j) <достраивание кодов>
FI
Функция Up (n,q) находит в массиве P место, куда вставить число q и вставляет его, сдвигая вниз остальные элементы.
DO (i=n-1, n-2,…,2)
IF (P[i-1]≤q) P[i]:=P[i-1]
ELSE j:=I
OD
FI
OD
P[j]:=q
Процедура Down (n,j) формирует кодовые слова.
S:=C[j,*] <запоминание j-той строки матрицы элементарных кодов в массив S>
L:=L[j]
DO (i=j,…,n-2)
C[i,*]:=C[i+1,*] <сдвиг вверх строк матрицы С>
L[i]:=L[i+1]
OD
C[n-1,*]:= S, C[n,*]:= S <восстановление префикса кодовых слов из массива S >
C[n-1,L+1]:=0, C[n,L+1]:=1
L[n-1]:=L+1, L[n]:=L+1
16.5 Почти оптимальное алфавитное кодирование
Рассмотрим несколько классических побуквенных кодов, у которых средняя длина кодового слова близка к оптимальной. Пусть имеется дискретный вероятностный источник, порождающий символы алфавита А={ a1,…,an } с вероятностями pi = p(ai), 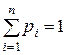 .
.








