 2015-08-13
2015-08-13 3003
3003Многомерная (или многофакторная) регрессионная модель – это уравнение с несколькими независимыми переменными.
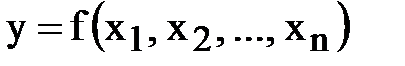
Для построения многомерной регрессионной модели могут быть использованы различные функции, наибольшее распространение получили линейная и степенная зависимости:
1. линейная: 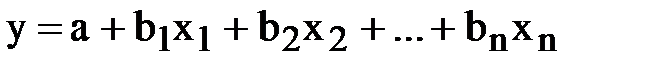
2. степенная: 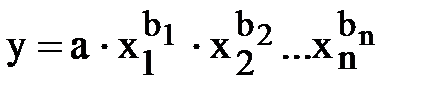
В линейной модели параметры (b1, b2, … bn) интерпретируются как влияние каждой из независимых переменных на прогнозируемую величину, если все другие независимые переменные равны нулю.
В степенной модели параметры являются коэффициентами эластичности. Они показывают, на сколько процентов изменится в среднем результат (y) с изменением соответствующего фактора на 1% при неизменности действия других факторов.
| При построении регрессионных моделей решающую роль играет качество данных. Сбор данных создает фундамент прогнозам, поэтому имеется ряд требований и правил, которые необходимо соблюдать при сборе данных. 1. Во-первых, данные должны быть наблюдаемыми, т.е. получены в результате замера, а не расчета. 2. Во-вторых, из массива данных необходимо исключить повторяющиеся и сильно отличающиеся данные. Чем больше неповторяющихся данных и чем однороднее совокупность, тем лучше будет уравнение. Под сильно отличающимися значениями понимается наблюдения исключительно не вписывающиеся в общий ряд. Например, данные о зарплате рабочих выражены четырех- и пятизначными числами (7 000, 10 000, 15 000), но обнаружено одно шестизначное число (250 000). Очевидно, что это ошибка. Наблюдение исключаем из массива. 3. Третье правило (требование) – это достаточно большой объем данных. Мнения статистиков относительно того, сколько необходимо данных для построения хорошего уравнения расходятся. |
По мнению одних, данных необходимо в 4-6 раз больше числа факторов. Другие утверждают, что не менее чем в 10 раз больше числа факторов, тогда закон больших чисел, действуя в полную силу, обеспечивает эффективное погашение случайных отклонений от закономерного характера связи.
В электронных таблицах Excel имеется возможность построения только лишь линейной многомерной регрессионной модели.
Метод имитационного моделирования Монте-Карло
| Метод имитационного моделирования получил свое название в честь города Монте-Карло, расположенного в княжестве Монако, одного из самых маленьких государств мира, расположенного на берегу Средиземного моря, около границы Франции и Италии. |
Метод имитационного моделирования Монте-Карло предполагает генерирование случайных значений в соответствии с заданными ограничениями. Приступая к проведению имитационного моделирования, прежде всего, необходимо разработать экономико-математическую модель (ЭММ) прогнозируемого показателя, отражающего взаимосвязь между факторными переменными, а также степень и характер их влияния на результат.
Поскольку в условиях современной рыночной конъюнктуры на субъект экономических отношений оказывают одновременное воздействие множество факторов различной природы и направленности и степень их воздействия не является детерминированной, представляется необходимым разделить переменные ЭММ на две группы: стохастические и детерминированные;
Далее следует определить типы вероятностных распределений для каждой стохастической переменной и соответствующие входные параметры, выполнить имитацию значений стохастических переменных с использованием генератора случайных чисел MS Excel или иных программных средств.
Инструмент «генерация случайных чисел» доступен пользователям MS Excel 2007 после активизации надстройки Пакет анализа.
Для выполнения имитационного моделирования в меню ДАННЫЕ необходимо выбрать пункт «Анализ данных», в появившемся диалоговом окне из списка выбрать инструмент «Генерация случайных чисел» и щелкнуть ОК.
В появившемся диалоговом окне необходимо для каждой стохастической переменной выбрать тип вероятностного распределения и задать соответствующие входные параметры. Данные этап является одним из наиболее сложных, поэтому при его выполнении необходимо использовать знания и опыт экспертов
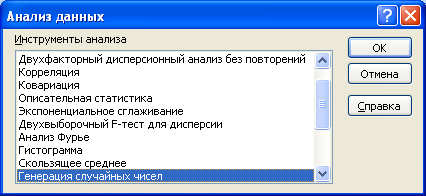
Рисунок 1.46 - Интерфейс меню анализа данных
Выбор типа вероятностного распределения также может осуществляться на основе имеющейся статистической информации. На практике чаще всего используют такие виды вероятностных распределений как нормальное, треугольное и равномерное.
| Нормальное распределение (или закон Муавра-Гаусса-Лапласа) предполагает, что варианты прогнозируемого параметра тяготеют к среднему значению. Значения переменной, существенно отличающиеся от среднего, то есть находящиеся в «хвостах» распределения, имеют малую вероятность. Треугольное распределение представляет собой производную от нормального распределения и предполагает линейно нарастающее, по мере приближения к среднему значению, распределение. Равномерное распределение используется в том случае, когда все значения варьируемого показателя имеют одинаковую вероятность реализации. |
При важности переменной и невозможности подобрать закон распределения её можно рассматривать с точки зрения дискретного распределения. Перечисленные выше виды вероятностных распределений требуют определения входных параметров, представленных в таблице.
Таблица - Входные параметры основных видов вероятностных распределений
| Вид вероятностного распределения | Входные параметры |
| 1 Нормальное распределение | - среднее значение; - стандартное отклонение. |
| 2 Треугольное распределение | - среднее значение; - пределы возможного диапазона значений. |
| 3 Равномерное распределение | - пределы возможного диапазона значений. |
| 4 Дискретное распределение | - конкретные значения переменной; - соответствующие данным значениям вероятности. |
В результате проведения серии экспериментов будет получено распределение значений стохастических переменных, на основании которых следует рассчитать значение прогнозируемого показателя.
Следующим необходимым этапом является проведение экономико-статистического анализа результатов имитационного моделирования, при котором рекомендуется рассчитывать следующие статистические характеристики:
- среднее значение;
- среднеквадратическое отклонение;
- дисперсию;
- минимальное и максимальное значение;
- размах колебаний;
- коэффициент асимметрии;
- эксцесс.
Указанные выше показатели могут быть использованы для проверки гипотезы о нормальном распределении. В случае подтверждения гипотезы для составления интервального прогноза может быть использовано правило «трех сигм». Правило «трех сигм» гласит, что если случайная величина X подчинена нормальному закону распределения с параметрами 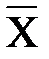 и
и  , то практически достоверно, что её значения заключены в интервале
, то практически достоверно, что её значения заключены в интервале 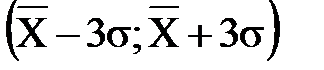 , то есть
, то есть 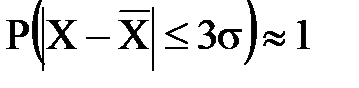 . Для повышения наглядности и упрощения интерпретации целесообразно построить гистограмму.
. Для повышения наглядности и упрощения интерпретации целесообразно построить гистограмму.
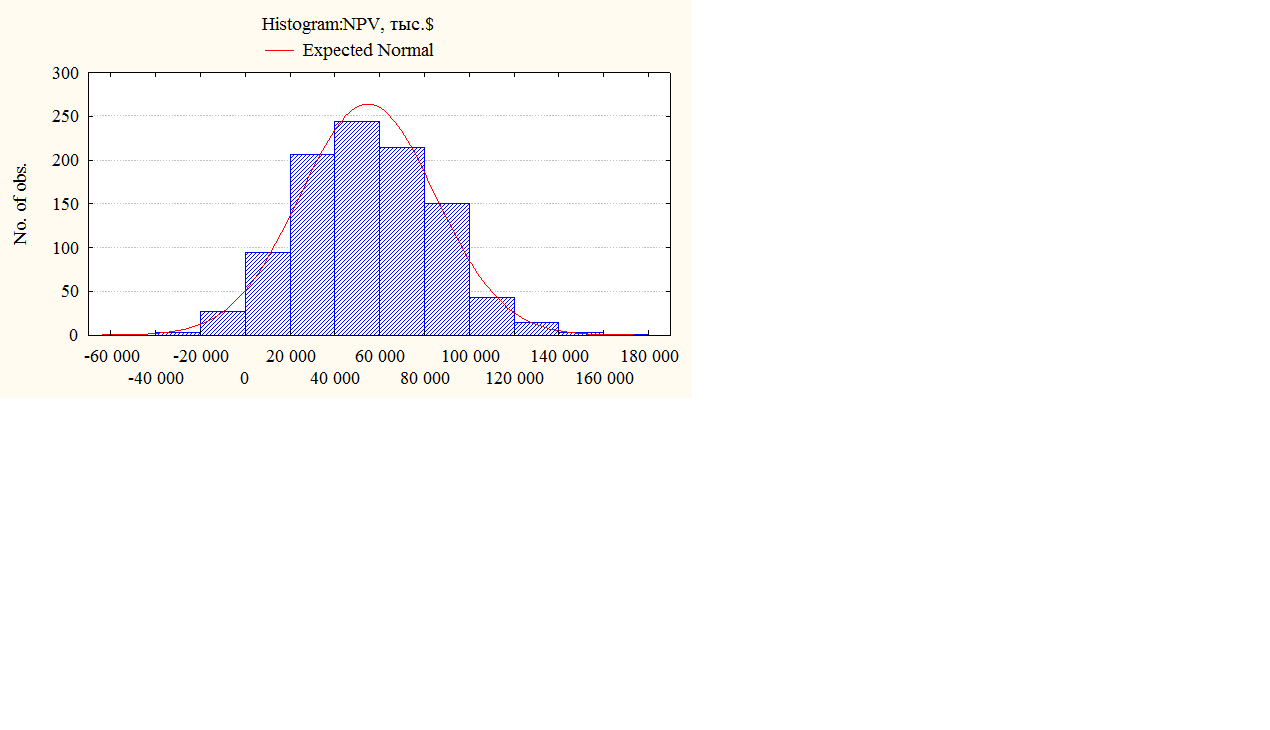
Рисунок 1.48 - Гистограмма значений прогнозируемого показателя
Реализация указанных этапов позволит получить вероятностную оценку значений прогнозируемого показателя (интервальный прогноз).

