 2014-02-09
2014-02-09 9181
9181В диаграммах потоков данных все используемые символы складываются в общую картину, которая дает четкое представление о том, какие данные используются, и какие функции выполняются системой документооборота. При этом часто выясняется, что существующие потоки информации, важные для деятельности компании, реализованы ненадежно и нуждаются в реорганизации. Наличие в диаграммах DFD элементов для описания источников, приемников и хранилищ данных позволяет точно описать процесс документооборота. Однако для описания логики взаимодействия информационных потоков модель дополняют диаграммами еще одной методологией – IDEF3, также называемой workflow diagramming. Методология моделирования IDEF3 позволяет графически описать и задокументировать процессы, фокусируя внимание на течении этих процессов и на отношениях процессов и важных объектов, являющихся частями этих процессов.
IDEF3 - это метод, имеющий основной целью дать возможность аналитикам описать ситуацию, когда процессы выполняются в определенной последовательности, а также описать объекты, участвующие совместно в одном процессе. С их помощью можно описывать сценарии действий сотрудников организации, например последовательность обработки заказа или события, которые необходимо обработать за конечное время. Каждый сценарий сопровождается описанием процесса и может быть использован для документирования каждой функции.
IDEF3 предполагает построение двух типов моделей: модель может отражать некоторые процессы в их логической последовательности, позволяя увидеть, как функционирует организация, или же модель может показывать “сеть переходных состояний объекта”, предлагая вниманию аналитика последовательность состояний, в которых может оказаться объект при прохождении через определенный процесс.
Диаграмма является основной единицей описания в IDEF3. Важно правильно построить диаграммы, поскольку они предназначены для чтения другими людьми (а не только автором).
С помощью диаграмм IDEF3 можно анализировать сценарии из реальной жизни, например, как закрывать магазин в экстренных случаях или какие действия должны выполнить менеджер и продавец при закрытии. Каждый такой сценарий содержит в себе описание процесса и может быть использован, что бы наглядно показать или лучше задокументировать бизнес-функции организации.
Модель, выполненная в IDEF3, может содержать следующие элементы:
Единицы работы (Unit of Work) - основной компонент диаграммы IDEF3 близкий по смыслу к работе IDEF0. В IDEF3 работы изображаются прямоугольниками с прямыми углами и имеют имя, выраженное отглагольным существительным, обозначающим процесс действия, одиночным или в составе фразы, и номер (идентификатор); другое имя существительное в составе той же фразы обычно отображает основной выход (результат) работы (например, "Изготовление изделия"). Часто имя существительное в имени работы меняется в процессе моделирования, поскольку модель может уточняться и редактироваться. Идентификатор работы присваивается при создании и не меняется никогда. Даже если работа будет удалена, ее идентификатор не будет вновь использоваться для других работ. Обычно номер работы состоит из номера родительской работы и порядкового номера на текущей диаграмме.
Связи (Links) - Связи, изображаемые стрелками, показывают взаимоотношения работ. Все связи в IDEF3 однонаправлены и могут быть направлены куда угодно, но обычно диаграммы IDEF3 стараются построить так, чтобы связи были направлены слева направо.
В IDEF3 различают три типа связей:
Связь предшествования (Precedence) – показывает, что прежде чем начнется работа-приемник, должна завершиться работа-источник. Обозначается сплошной линией.
Связь отношения (Relational) - показывает связь между двумя работами или между работой и объектом ссылки. Обозначается пунктирной линией.
Связь поток объектов (Object Flow) – показывает участие некоторого объекта в двух или более работах, как, например, если объект производится в ходе выполнения одной работы и потребляется другой работой. Обозначается стрелкой с двумя наконечниками.
Перекрестки (соединения) - перекрестки используются в диаграммах IDEF3, чтобы показать ветвления логической схемы моделируемого процесса и альтернативные пути развития процесса могущие возникнуть во время его выполнения. Окончание одной работы может служить сигналом к началу нескольких работ, или же одна работа для своего запуска может ожидать окончания нескольких работ. Перекрестки используются для отображения логики взаимодействия стрелок при слиянии и разветвлении или для отображения множества событий, которые могут или должны быть завершены перед началом следующей работы.
Различают два типа перекрестков:
Перекресток слияния (Fan-in Junction) – узел, собирающий множество стрелок в одну, указывая на необходимость условия завершенности работ-источников стрелок для продолжения процесса.
Перекресток ветвления (Fan-out Junction) – узел, в котором единственная входящая в него стрелка ветвится, показывая, что работы, следующие за перекрестком, выполняются параллельно или альтернативно.
Таблица 1.4. Типы перекрестков
| Обозначение | Наименование | Смысл в случае слияния стрелок (Fan-in Junction) | Смысл в случае разветвления стрелок (Fan-oat Junction) |
| |& | Asynchronous AND | Все предшествующие процессы должны быть завершены | Все следующие процессы должны быть запущены |
| |&| | Synchronous AND | Все предшествующие процессы завершены одновременно | Все следующие процессы запускаются одновременно |
| |O | Asynchronous OR | Один или несколько предшествующих процессов должны быть завершены | Один или несколько следующих процессов должны быть запущены |
| |O| | Synchronous OR | Один или несколько предшествующих + процессов завершены одновременно | Один или несколько следующих процессов запускаются одновременно |
| X | XOR (Exclusive OR) | Только один предшествующий процесс завершен | Только один следующий процесс запускается |
Все перекрестки на диаграмме нумеруются, каждый номер имеет префикс J. Можно редактировать свойства перекрестка при помощи диалога Definition Editor. В отличие от IDEF0 и DFD в IDEF3 стрелки могут сливаться и разветвляться только через перекрестки.
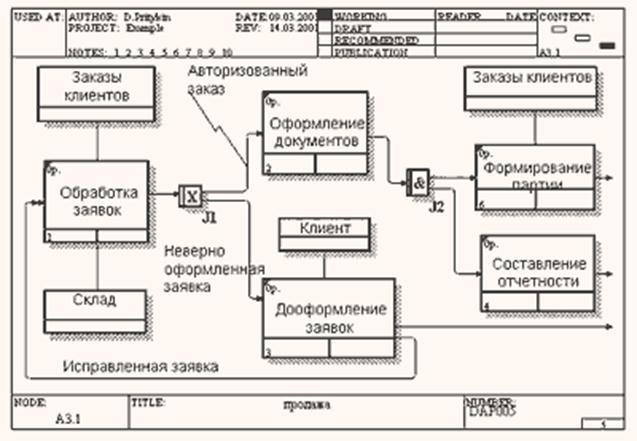
рис. 9 Пример диаграммы IDEF3
В результате дополнения диаграмм IDEF0 диаграммами DFD и IDEF3 может быть создана смешанная модель, которая наилучшим образом описывает все стороны деятельности предприятия (рис. 1.55). Иерархию работ в смешанной модели можно увидеть в окне Model Explorer. Работы в нотации IDEF0 изображаются зеленым цветом, IDEF3 - желтым, DFD - синим.
4.5 Моделирование данных (IDEF1X)
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для удобного построения концептуальной схемы.
Концептуальная схема - универсальное представление структуры данных независимое от конечной реализации базы данных и аппаратной платформы.
Использование метода IDEF1X наиболее целесообразно для построения логической структуры базы данных после того, как все информационные ресурсы исследованы (скажем с помощью метода IDEF1) и решение о внедрении реляционной базы данных, как части корпоративной информационной системы, было принято.
Сущность в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друх от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности.
Связи в IDEF1X представляют собой ссылки, соединения и ассоциации между сущностями. Связи это суть глаголы, которые показывают, как соотносятся сущности между собой. Ниже приведен ряд примеров связи между сущностями:
Отдел <состоит из> нескольких Сотрудников
Самолет <перевозит> нескольких Пассажиров.
Сотрудник <пишет> разные Отчеты.
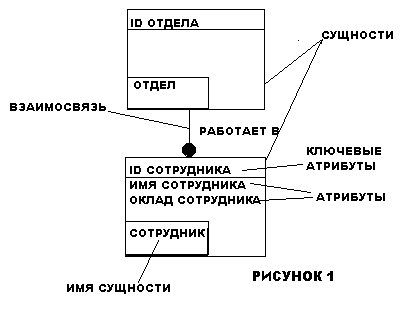
Во всех перечисленных примерах взаимосвязи между сущностями соответствуют схеме один ко многим. Это означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности. Причем первая сущность называется родительской, а вторая - дочерней. В приведенных примерах глаголы заключены в угловые скобки. Связи отображаются в виде линии между двумя сущностями с точкой на одном конце и глагольной фразой, отображаемой над линией.
Отношения многие ко многим обычно используются на начальной стадии разработки диаграммы, например, в диаграмме зависимости сущностей и отображаются в IDEF1X в виде сплошной линии с точками на обоих концах.
Так как отношения многие ко многим могут скрыть другие бизнес правила или ограничения, они должны быть полностью исследованы на одном из этапов моделирования.
Идентификация сущностей. Представление о ключах.
Сущность описывается в диаграмме IDEF1X графическим объектом в виде прямоугольника. На рис.2 приведен пример IDEF1X диаграммы. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены ключевые поля и часть, где расположены неключевые поля. Верхняя часть называется ключевой областью, а нижняя часть областью данных. Ключевая область объекта СОТРУДНИК содержит поле "Уникальный идентификатор сотрудника", в области данных находятся поля "Имя сотрудника", "Адрес сотрудника", "Телефон сотрудника" и т.д.
Ключевая область содержит первичный ключ для сущности. Первичный ключ - это набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над линией в ключевой области. Как следует из названия, неключевой атрибут - это атрибут, который не был выбран ключевым. Неключевые атрибуты располагаются под чертой, в области данных.
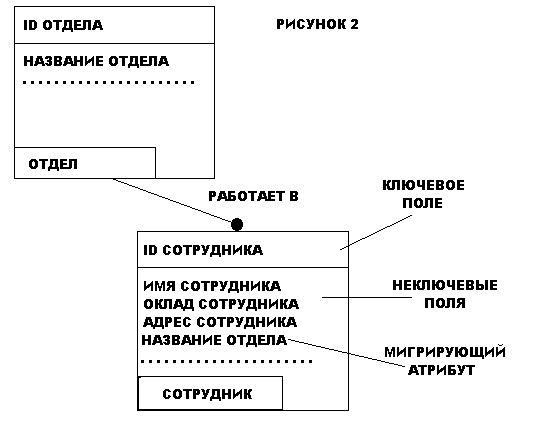
При создании сущности в IDEF1X модели, одним из главных вопросов, на который нужно ответить, является: "Как можно идентифицировать уникальную запись?". Для этого требуется уникальная идентификация каждой записи в сущности для того, чтобы правильно создать логическую модель данных. Напомним, что сущности в IDEF1X всегда имеют ключевую область и, поэтому в каждой сущности должны быть определены ключевые атрибуты.
Выбор первичного ключа для сущности является очень важным шагом, и требует большого внимания.
В качестве первичных ключей могут быть использованы несколько атрибутов или групп атрибутов.
Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты). Кандидаты в ключи должны уникально идентифицировать каждую запись сущности.
В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Правила устанавливают, что атрибуты и группы атрибутов должны:
Уникальным образом идентифицировать экземпляр сущности.
Не использовать NULL значений.
Не изменяться со временем. Экземпляр идентифицируется при помощи ключа. При изменении ключа, соответственно меняется экземпляр.
Быть как можно более короткими для использования индексирования и получения данных.
Если вам нужно использовать ключ, являющийся комбинацией ключей из других сущностей, убедитесь в том, что каждая из частей ключа соответствует правилам.
Для наглядного представления о том, как целесообразно выбирать первичные ключи, приведем следующий пример - выберем первичный ключ для знакомой нам сущности "СОТРУДНИК":
Атрибут "ID сотрудника" является потенциальным ключом, так как он уникален для всех экземпляров сущности СОТРУДНИК.
Атрибут "Имя сотрудника" не очень хорош для потенциального ключа, так как среди служащих на предприятии может быть, к примеру, двое Иванов Петровых.
Атрибут "Номер страхового полиса сотрудника" является уникальным, но проблема в том, что СОТРУДНИКА может не иметь такового.
Комбинация атрибутов "имя сотрудника" и "дата рождения сотрудника" может оказаться удачной для наших целей и стать искомым потенциальным ключом.
После проведенного анализа можно назвать два потенциальных ключа - первый "Номер сотрудника" и комбинация, включающая поля "имя сотрудника" и "Дата рождения сотрудника". Так как атрибут "Номер сотрудника" имеет самые короткие и уникальные значения, то он лучше других подходит для первичного ключа.
При выборе первичного ключа для сущности, разработчики модели часто используют дополнительный (суррогатный) ключ, т.е. произвольный номер, который уникальным образом определяет запись в сущности. Атрибут "Номер сотрудника" является примером суррогатного ключа. Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. К тому же суррогатные ключи могут автоматически генерироваться системой так, чтобы нумерация была сплошной, т.е. без пропусков.
Потенциальные ключи, которые не выбраны первичными, могут быть использованы в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.

