 2015-05-06
2015-05-06 1688
1688Статистический графический пакет StatGraphics (Statistical Graphics System) предназначен для статистического анализа и обработки данных на персональном компьютере. Он является наиболее полной интегрированной статической и графической системой, объединяющей профессиональные методы обработки больших объемов данных, качественную графику и дружественный пользовательский интерфейс. StatGraphics позволяет выполнять статический анализ экспериментальных данных, полученных в результате исследования сложных стохастических (вероятностных) систем.
Для определения показателей надежности для двух вариантов исходных данных необходимо выполнить последовательность действий:
1. Подготовка исходных данных к статистической обработке для двух наборов одновременно. С этой целью запускаем StatGraphics Plus, создадим две переменные (2 столбца) с именами narabotka1 и narabotka2, сохраним их в файле с именем OTKAZ.
В переменную (столбец) narabotka1 поместим первый набор исходных данных непосредственно из табл. 1. Для исходных данных, содержащихся в табл. 2, вычислим разности между последующими и предыдущими значениями моментов времени отказов каждого элемента, в результате чего получим набор чисел, приведенный в табл. 3.
Таблица 3. Время между отказами элементов
| Номер элемента | Моменты отказа на периоде времени 700 часов |
| 204; 17;124;31;161;160 | |
| 2;37;32:33;14;95;331;52;12;49 | |
| 138; 176;73;80;4;85;143 | |
| 8; 3;41;42;98;284;15;36;128 | |
| 106; 62;157;35;330 | |
| 192; 15;10;145;64 | |
| 225;215;178;39;10 | |
| 371; 49;80 | |
| 85; 286;197;11;32;14;38 | |
| 80; 31;41;10;207;25;68;89 |
Полученные разности из табл. 3 поместим в переменную (столбец) narabotka2. На экране компьютера получается следующая заставка:
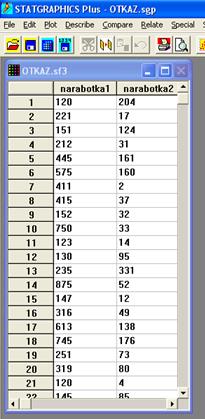
Длины переменных narabotkal и narabotka2 соответственно равны 100 и 65, что соответствует количеству чисел в табл. 1 и 3.
2. Определение статистических показателей для каждого набора данных, содержащихся в переменных OTKAZ.narabotkal и OTKAZ.narabotka2.
Нажатие кнопки StatWizard  получим:
получим:
Это приведет к расчету требуемых характеристики и выводу их на экран в следующем виде:
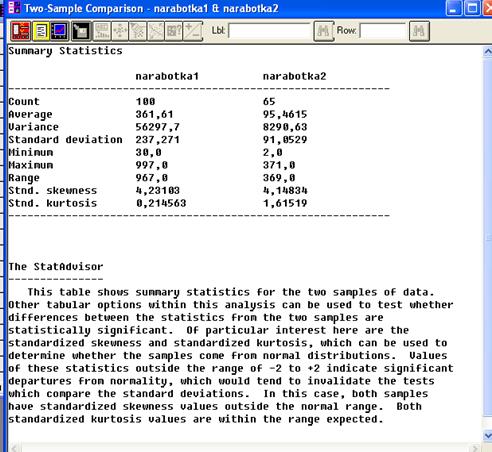
| Narabotka1 | Narabotka2 | |
| Размер выборки | ||
| Среднее значение | 361,61 | 95,4615 |
| Стандартное отклонение | 237,271 | 91,0529 |
| Минимум | ||
| Максимум | ||
| Размах |
Отсюда следует, что для первого набора исходных данных средняя наработка до первого отказа приближенно равна T1 =362 часа, а для второго набора средняя наработка на отказ равна T2 = 95 часов. В первом случае распределение времени работы элемента между отказами явно отличается от экспоненциального, т. к. стандартное отклонение s1 = 237 существенно отличается от средней наработки на отказ. Во втором случае стандартное отклонение s2 =91 достаточно близко к средней наработке до отказа, что свидетельствует о возможной близости распределения к экспоненциальному.
Видим также, что для первого набора данных все реализации случайной наработки до отказа находятся в интервале [30; 997], и размах выборки равен 967 часов. Для второго набора данных все выборочные значения содержатся в интервале [2; 371] длиной 369 часов.








