 2014-02-09
2014-02-09 7898
78981. Энтропия является величиной вещественной и не отрицательной. Так как вероятность исхода любых событий или опытов может изменяться только от 0 до 1, то логарифм таких величин является отрицательным, поэтому произведение двух отрицательных величин всегда положительно.
2. Энтропия – величина ограниченная. Для слагаемых в диапазоне изменения вероятности от 0 до 1 ограниченность энтропии очевидна, но предел произведения отрицательной вероятности на логарифм этой вероятности не пределен. Если найти предел при вероятности, стремящейся к нулю, то, используя правило Лопиталя, мы в конечном итоге получим, что предел:
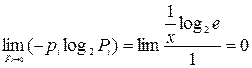
3. Энтропия обращается в ноль в том случае, когда вероятность одного из состояний равна единице.
4. Энтропия максимальна, когда все события равновероятны. Чтобы доказать это свойство, можно пользоваться математической величиной, но формула, предложенная Хартли, представляет собой:
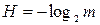
m – величина исходов.
Так как величина исходов берется равная ½, то и энтропия при этой вероятности является максимальной. То есть частная форма подтверждает это свойство.
5. Энтропия двух независимых опытов с числом исходов, равным m1 и m2, равна сумме энтропий каждого из этих опытов, взятых в отдельности.
Суммарная энтропия:
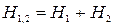
Информация, поступающая в АСУ от датчиков, измеряющих различные параметры технологического процесса, а так же вводимых при помощи клавиатуры по каналам связи, могут эти сигналы все носить непрерывный или дискретный характер. Непрерывные сигналы перед вводом их в ЭВМ преобразуются в дискретную форму с помощью АЦП. Таким образом информация в АСУ представляется в дискретной форме. Текстовая информация состоит из конечного числа символов, букв, цифр, пробелов, знаков препинания, значков. Совокупность знаков текста и цифр образует первичный алфавит. Этот первичный алфавит не удобен для кодирования информации, так как содержит довольно много всевозможных знаков. Поэтому непосредственное его использование при обработке информации крайне сложно. Чтобы обеспечить удобство переработки информации необходимо преобразовать этот первичный алфавит во вторичный. Сам алгоритм преобразований алфавита с первичного, например, кириллицы, во вторичный алфавит, называется кодом. А операция – кодированием.
Последовательности символа вторичного алфавита, который соответствует содержанию передаваемого алфавита называется КОДОВЫМ СЛОВОМ.
Для того, чтобы вторичный алфавит можно было применить и он был пригоден для кодирования, к нему предъявляются требования:
1) простота, надежность и эффективность аппаратной реализации информационных устройств;
2) минимальное время для передачи информации (максимально сжатая информация);
3) минимальный объем памяти запоминающих устройств;
4) простота выполнения всех арифметических и логических операций с помощью вторичного алфавита.
Если в канале присутствуют помехи при передаче информации, то важнейшее значение приобретает проблема достоверности принимаемых, декодированных сообщений. Заданная достоверность обеспечивается внесением некоторой избыточности в сообщение. Эта избыточность позволяет определить и исключить ошибки при передаче символов.
Кодирование, как процесс представления информации в цифровой форме.
При кодировании информации обычно используются позиционные коды (системы счисления). При этих системах счисления значение каждого символа зависит от его разряда или его положения по отношению к другим символам. Цифры двоичного кода позволяют легко выполнять все вышеприведенные требования. Простота: 0 и 1. Эффективное кодирование: учитывая вероятностное появление букв в алфавите, мы можем сжать информацию без потери информативности. Минимальное время передачи за счет сжатия. Минимальный объем. Легко реализуются действия в двоичной системе.
Но двоичный код несколько неудобен при вводе и выводе информации, так как оператору трудно оценить непривычные числа. Поэтому получили распространение и другие системы счисления. Наиболее распространенные: 8-ричная и десятично-двоичная.
В восьмеричной для записи всех возможных символов используется 8 цифр: 0—7. Перевод из 8-ричной в 2-чную осуществляется заменой на двоичные числа.
Например: 714 в двоичной системе: 111=7; 001=1; 101=4.
Двоично-десятичная СИ наиболее приемлема, так как она имеет большие преимущества и легко переводится с одной в другую. При этом каждая цифра десятичного числа записывается в виде четырех двоичного.
Например:
| Десятичный | Двоично-десятичный | Десятичный | Двоично-десятичный |
Более сложные проблемы возникают при кодировании текстовой информации. Необходимо учитывать необходимость обнаружения ошибок при приеме, при декодировании, а не только вероятность появления букв в сообщении.
При кодировании текстов используются равномерные и неравномерные коды. Равномерные – длина сообщений об одной букве постоянная. Пример: коды Бодо. Они состоят из пяти элементов. У неравномерных кодов они состоят из различных по длительности для каждой буквы кодов. Например: код Морзе. Длина сообщения в этом коде для каждой буквы различна.
Код Шинона—Фоно.
Эффективное кодирование состоит в том, чтобы, учитывая статистические свойства источника сообщения, а именно, вероятность появления каждого знака первичного алфавита, минимизировать среднее число двоичных знаков, требующихся для кодирования одного знака. То есть наиболее часто повторяющиеся знаки обозначаются минимальным числом двоичных знаков, а те, которые применяются редко, -- длинными. Средняя величина знаков на одну букву в результате этого уменьшается на 30%.
Теоретической базой эффективного кодирования является теорема Шинона для каналов передачи с отсутствием помех. Теорема Шинона формулируется следующим образом: сообщение, передаваемые источником с энтропией Н можно закодировать так, чтобы среднее число двоичных знаков на одну букву первичного алфавита было сколь угодно близким к энтропии, но не меньше этой величины.
Эта методика кроме Шинона была разработана и Фоно, независимо.
Последовательность построения такого кода можно изложить в следующем виде:
1. Буквы первичного алфавита записываются в таблицу в порядке убывания их вероятности появления в сообщении.
2. Все буквы разделяются на две группы, так, чтобы суммы вероятностей в них были примерно одинаковыми.
Например:
z1. Вероятность появления Рz1=0,27
Pz2=0,23
Pz3=0,16
Pz4=0,16
Pz5=0,1
Pz6=0,08
Рz1=0,27
Pz2=0,23 à0,5
Pz3=0,16
Pz4=0,16
Pz5=0,1
Pz6=0,08à0,5
Это идеальный пример, но нужно как можно ближе подгонять к половине!!
При чем не переставляя буквы местами.
3. Буквы первой группы в качестве первого символа получают 1. А буквам второй группы – 0.
4. Эти две подгруппы снова разбиваются в свою очередь на две подгруппы. С условием, чтобы вероятности в этих подгруппах были приблизительно одинаковыми и равны ¼. Каждой подгруппе присваивается 1 первой половине, 0 – второй половине. Таким образом, разбиваются так подгруппы, пока не дойдет до одной буквы.
Недостаток методики построения кодов Шинона—Фоно: неоднозначность вариантов кодов отдельных знаков. Это следует из того, что разбиение знаков алфавита можно сделать большей по вероятности как верхнюю, так и нижнюю. Буквы с равной вероятностью попадают в разные группы, тогда код у нее становится более длинным. Эта неопределенность вносит некоторую избыточность в код.
Код Хаффмана
Методика построения кода Хаффмана включает в себя следующие этапы:
1. Буквы алфавита располагаются в порядке убывания вероятностей.
2. Две последние буквы объединяются в одну вспомогательную букву, которой приписывается суммарная вероятность. В нашем примере: z6+z5. Pz5,6=0,17. Она бы, соответственно поднялась вверх по столбу вероятностей.
3. Вероятности букв, не участвующие в объединении и полученные суммарные вероятности снова располагаются в порядке убывания. Пункты 2-3 повторяются до тех пор, пока не будет получена единственная вспомогательная буква с вероятностью равной 1.
4. На втором этапе построения кода строится кодовое дерево. Для составления кодовой комбинации необходимо проследить путь перехода по строкам и столбцам таблицы. Эта задача облегчается при использовании кодового дерева. Из точки, соответствующей вероятности 1 выходят две ветви, ветвь с большей вероятностью, которой присваивается символ 1, а ветвь с меньшей – символ 0. Такая последовательность ветвления продолжается до тех пор, пока ветвь не дойдет до каждой буквы.
На 3-ем этапе по кодовому дереву составляется кодовая комбинация для каждой буквы. Двигаясь по кодовому дереву от единицы, можно записать для каждой буквы соответствующую ей кодовую комбинацию.
Методы кодирования, когда кодируются сочленения букв, позволяют достигнуть максимального сжатия букв.
Средняя величина значков на каждую букву уменьшается.
Пути совершенствования эффективного кодирования
При эффективном кодировании среднее количество знаков приближается к значению ЭНТРОПИИ за счет присвоения более вероятным знакам первичного алфавита более коротких комбинаций и более длинных комбинаций – менее вероятным знакам. Неравномерность кодов существенно усложняет задачу декодирования. А как вы знаете, эффективные коды неравномерные, имеют длину в зависимости от вероятности. Эта разность вероятностей и разность длин кодов затрудняет определение начала и конца символов. Введение же разделительного символа невыгодно по причине, что изменится средняя длина кодовой комбинации (она взрастет). Более рациональным методом разделения знаков является такое построение кода, при котором ни одна комбинация кода не совпадает с началом более длинной комбинации. Такие коды называются ПРЕФИКСНЫМИ.
Пусть задана последовательность кодов:
1) 100000110110110100.
Эти коды имеют вид:
z1=00
z2=01
z3=101
z4=100
Данная последовательность однозначно декодируется:
100\00\01\101\101\101\00.
Таким образом, можно сказать, что эта последовательность – префиксный код.
2) 000101010101.
Приведенная последовательность комбинаций непрефиксного кода при значении букв:
z1=00
z2=01
z3=101
z4=010.
Данная последовательность может декодироваться различным способом, так как комбинация 01 является началом более длинной комбинации 010:
00\01\01010101.
00\010\1010101.
Коды, полученные по методу Шинона-Фено и Хаффмана удовлетворяют требованиям префиксных кодов.
Для совершенствования эффективного кодирвоания целесообразно укрупнять знаки первичного алфавита, то есть разбивать подлежащие передаче сообщения на двух-, трех- или n-знаковые сочетания, вероятности которых определяются на основе вероятностей появления знаков исходного алфавита. Каждому такому сочетанию ставится в соответствие своя кодовая комбинация, найденная по ранее указанным методикам. При таком объединении знаков первичного алфавита процесс кодирования облегчается, так как укрупненные знаки корреляционно ослабляются (ослабляется корреляция).
Помехоустойчивое кодирование
Если в канале связи отсутствуют помехи, то при приеме сигнала его код легко устанавливается и соответствует коду, с помощью которого сообщение было закодировано. При наличие же помех возможно искажение сигнала, а следовательно, и информации. Для того, чтобы это не происходило предпринимаются специальные меры, направленные на повышение достоверности принимаемой информации.
Главные среди них:
1. Увеличение мощности полезного (передаваемого) сигнала, для того, чтобы его мощность значительно выделялась по сравнению с помехами.
2. Многократное повторение кодовых комбинаций.
3. Помехоустойчивое кодирование.
Увеличение мощности передаваемого сигнала связано с энергетическими затратами, а многократное повторение его связано с затратами по времени, в то же время и энергии на передачу. Поэтому основным средством борьбы с влиянием помех является помехоустойчивое кодирование.
Теория помехоустойчивого кодирования базируется на второй теореме Шинона: при любой скорости передачи двоичных сигналов меньше чем пропускная способность канала связи существует такой код, при котором вероятность ошибочного декодирования может быть сведена к минимальной. Если скорость передачи больше пропускной способности канала связи, то вероятность ошибки не может быть сделана произвольно малой.
На основе этой теории и разрабатываются помехоустойчивые (КОРРЕКТИРУЮЩИЕ) коды. Эти коды позволяют не только обнаружить ошибку в принимаемом сигнале, но и исправить ее.
Рассмотрим двоичный код длиной n. С помощью этого кода можно получить число комбинаций 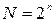 .
.
Ошибка при приеме этих комбинаций состоит в том, что в результате действия помехи вместо единицы можно принять ноль или вместо нуля – единицу. Когда в кодовой комбинации 1 знак заменяется другим, то такая ошибка называется ОДИНОЧНОЙ, два – ДВОЙНОЙ и т. д. Если в процессе передачи используется всё число комбинаций N, то ошибка любой кратности остается незамеченной, так как при этом одна из возможных комбинаций переходит в другую кодовую комбинацию, которая является так же допустимой и разрешенной. Поэтому с полным основанием мы можем считать ее верной, хотя на самом деле принятая комбинация не соответствует переданной.
Для пояснения рассмотрим пример:
Сообщение состоит из 4 знаков z. Данные знаки закодированы двухзначным кодом, то есть n=2, а количество комбинаций 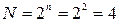
z1=00
z2=01
z3=10
z4=11.
Поскольку комбинаций 4 и они все используются при кодировании, то любое изменение комбинации, например, z2, приведет к ошибке: вместо z2 применяется либо z4 либо z1.
Ошибка во втором разряде приводит к изменению комбинаций на z1, в первом – к изменению комбинаций на z4, а так как они обе разрешены, то мы не можем знать, на самом деле они ошибочны или правильны.
Это происходит потому что комбинации 01 и 00 различаются только в одном знаке.
Для того, чтобы можно было обнаружить одиночную ошибку необходимо, чтобы комбинации различались между собой не менее чем в двух знаках и в этом случае одиночная ошибка даст комбинацию, которая от истинной или любой другой будет отличаться в одном или двух знаках. На этом принципе основано построение кодов, обнаруживающих ошибку.
Принцип формулируется так: правила построения кода, позволяющего обнаружить одиночную ошибку заключается в том, что из всех возможных комбинаций для кодирования используется только половина.
Рассмотрим пример построения кода, позволяющего обнаружить одиночную ошибку:
Для построения такого кода нужно, чтобы выбранные 4 комбинации для обозначения сообщения или букв z1-z4 отличались друг от друга не менее чем в двух разрядах. Это возможно, если для кодирования используются трехразрядные кодовые комбинации, при чем используется из них только половина.
То есть n=3, тогда N = 8. 4 комбинации мы и берем для кодирования нашего сообщения:
z1=000
z2=011
z3=101
z4=110.
Если при приеме сообщения z2 произошла ошибка во втором разряде и вместо комбинации 011 принята комбинация 001, то тому, кто это принимает сразу видно, что это ошибка, такой комбинации быть не может, она относится к запрещенным.
Но в данном примере устанавливается только факт ошибки, но не ответ на вопрос, какая из четырех комбинаций была передана.
Для того, чтобы установить не только наличие ошибки, но и указать, какая комбинация передавалась, необходимо построить так называемый код, позволяющий исправлять ошибку. В таком коде все кодовые комбинации должны отличаться не менее чем в трех разрядах от остальных, а от истинной в одном разряде.
Пример построения кодовой комбинации, исключающей ошибку:
Необходимо выбрать пятиразрядный код. То есть n=5, тогда N = 32. 4 комбинации мы и берем для кодирования нашего сообщения:
z1=00000
z2=01101
z3=10110
z4=11011.
Алгоритм декодирования кодовых комбинаций кодов, которые могут исправить ошибку, заключается в следующем:
1) производится сравнения принятых комбинаций с таблицей разрешенных;
Если для z2 вместо 01101 будет принята: 01001, то, сравнивая по принятому алгоритму мы видим, что среди разрешенных комбинаций ее нет, поэтому сравним эту комбинацию со всеми разрешенными. В результате сравнения получим: от z1 отличия принятой комбинации в 2-х знаках, от z3 – в пяти знаках, от z4 – в двух знаках. И только от z2 отличие в одном знаке. Следовательно, была передана комбинация z2. И необходимо принятую комбинацию исправить, то есть изменить, в третьем разряде 0 на 1.
Из рассмотренных примеров ясно, что помехоустойчивость кода достигается путем введения избыточных символов в кодовую комбинацию, однако кодовая комбинация состоит из информационной части символов nи, и nк – контрольная. Общая длина n естественно равна их сумме.
Чтобы определить величину эн контрольного мы знаем, по какому принципу нужно выбирать число контрольных комбинаций. Таким образом, для того, чтобы определить число контрольных комбинаций для кода Хэмминга мы будем исходить из следующих позиций. Код Хэмминга – один из наиболее распространенных систематических кодов. Он очень прост при технической реализации для обнаружения и исправления ошибки. В данную комбинацию входят как информационные, так и контрольные символы, которые определяются исходя из формул:
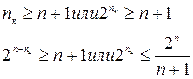
Соотношение n, nи, nк определяются из вышепредставленных формул.
Передача информации по каналам связи
Характеристики каналов связи
В зависимости от вида передаваемого сигнала каналы передачи могут быть непрерывными или дискретными. Непрерывный канал связи представляет собой совокупность средств, предназначенных для передачи непрерывных аналоговых сигналов. Дисккретным каналом связи называют совокупность технических средств для передачи дискретных сигналов. Информационная моджель каналов с помехами задается множестовм символов на его входе выходе и описанием вероятности передачи информации отдельных символов. Канал моежт иметь множество состояний и переходить из одного состояния в другое как с течением времени, так и в зависимости от последовательности передаваемых символов.
Состояние канала характеризует матрица условных вероятностей P(xi|yi ), что обозначает что икс будет передан как игрик. Значение условных вероятностей зависит от многих факторов свойств сигналов, метода кодирования, наличия случайных помех в канале, принципа декодирования сигналов.
Если переходные вероятности не зависят от времени, то канал называется СТАЦИОНАРНЫМ каналом. В НЕСТАЦИОНАРНОМ канале переходные вероятности изменяются с течением времени. В том случае, когда переходные вероятности зависят от предыдущего состояния, то канал называется КАНАЛОМ С ПАМЯТЬЮ. Иначе его называют КАНАЛОМ БЕЗ ПАМЯТИ.

